 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiltered-ViT: A Robust Defense Against Multiple Adversarial Patch Attacks
Nov 11, 2025Deep learning vision systems are increasingly deployed in safety-critical domains such as healthcare, yet they remain vulnerable to small adversarial patches that can trigger misclassifications. Most existing defenses assume a single patch and fail when multiple localized disruptions occur, the type of scenario adversaries and real-world artifacts often exploit. We propose Filtered-ViT, a new vision transformer architecture that integrates SMART Vector Median Filtering (SMART-VMF), a spatially adaptive, multi-scale, robustness-aware mechanism that enables selective suppression of corrupted regions while preserving semantic detail. On ImageNet with LaVAN multi-patch attacks, Filtered-ViT achieves 79.8% clean accuracy and 46.3% robust accuracy under four simultaneous 1\% patches, outperforming existing defenses. Beyond synthetic benchmarks, a real-world case study on radiographic medical imagery shows that Filtered-ViT mitigates natural artifacts such as occlusions and scanner noise without degrading diagnostic content. This establishes Filtered-ViT as the first transformer to demonstrate unified robustness against both adversarial and naturally occurring patch-like disruptions, charting a path toward reliable vision systems in truly high-stakes environments.
Federated Learning for Anomaly Detection in Energy Consumption Data: Assessing the Vulnerability to Adversarial Attacks
Feb 07, 2025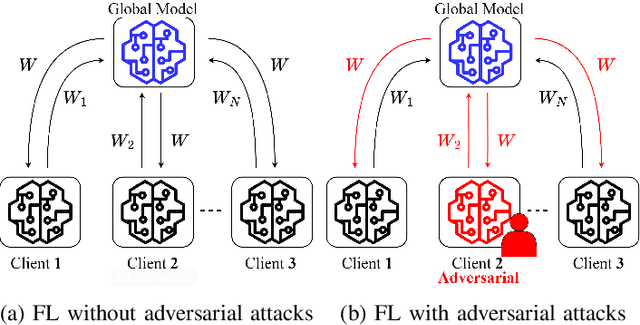
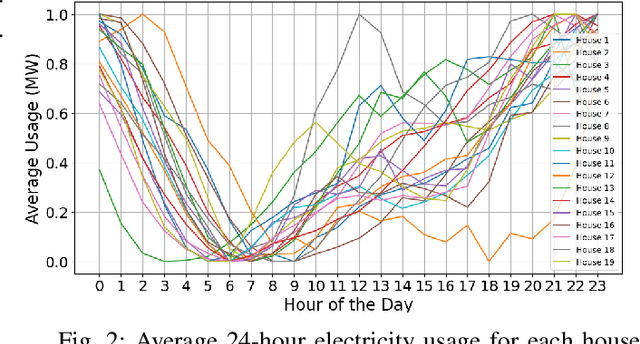
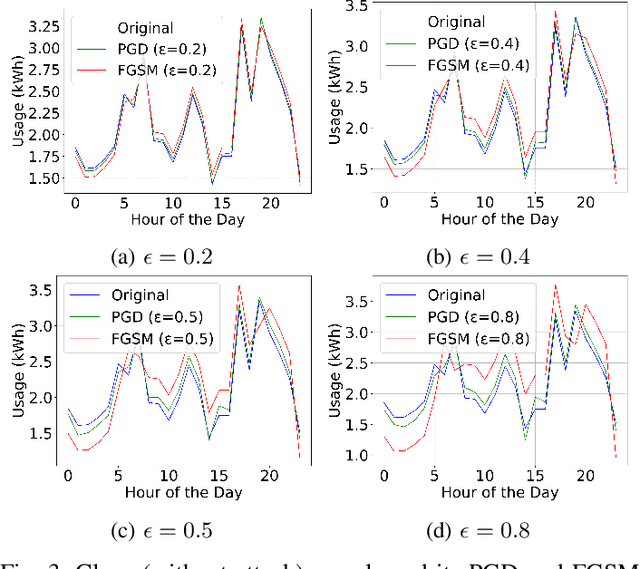
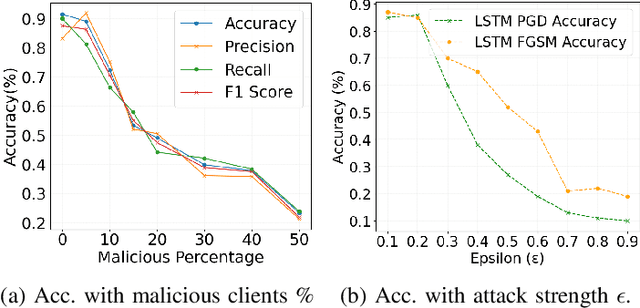
Anomaly detection is crucial in the energy sector to identify irregular patterns indicating equipment failures, energy theft, or other issues. Machine learning techniques for anomaly detection have achieved great success, but are typically centralized, involving sharing local data with a central server which raises privacy and security concerns. Federated Learning (FL) has been gaining popularity as it enables distributed learning without sharing local data. However, FL depends on neural networks, which are vulnerable to adversarial attacks that manipulate data, leading models to make erroneous predictions. While adversarial attacks have been explored in the image domain, they remain largely unexplored in time series problems, especially in the energy domain. Moreover, the effect of adversarial attacks in the FL setting is also mostly unknown. This paper assesses the vulnerability of FL-based anomaly detection in energy data to adversarial attacks. Specifically, two state-of-the-art models, Long Short Term Memory (LSTM) and Transformers, are used to detect anomalies in an FL setting, and two white-box attack methods, Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD), are employed to perturb the data. The results show that FL is more sensitive to PGD attacks than to FGSM attacks, attributed to PGD's iterative nature, resulting in an accuracy drop of over 10% even with naive, weaker attacks. Moreover, FL is more affected by these attacks than centralized learning, highlighting the need for defense mechanisms in FL.
Generating Universal Adversarial Perturbations for Quantum Classifiers
Feb 13, 2024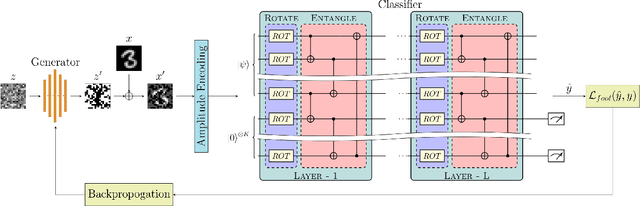
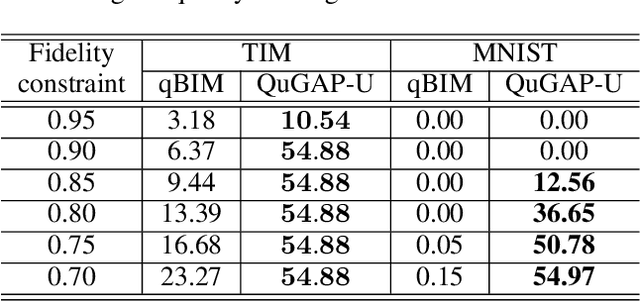


Quantum Machine Learning (QML) has emerged as a promising field of research, aiming to leverage the capabilities of quantum computing to enhance existing machine learning methodologies. Recent studies have revealed that, like their classical counterparts, QML models based on Parametrized Quantum Circuits (PQCs) are also vulnerable to adversarial attacks. Moreover, the existence of Universal Adversarial Perturbations (UAPs) in the quantum domain has been demonstrated theoretically in the context of quantum classifiers. In this work, we introduce QuGAP: a novel framework for generating UAPs for quantum classifiers. We conceptualize the notion of additive UAPs for PQC-based classifiers and theoretically demonstrate their existence. We then utilize generative models (QuGAP-A) to craft additive UAPs and experimentally show that quantum classifiers are susceptible to such attacks. Moreover, we formulate a new method for generating unitary UAPs (QuGAP-U) using quantum generative models and a novel loss function based on fidelity constraints. We evaluate the performance of the proposed framework and show that our method achieves state-of-the-art misclassification rates, while maintaining high fidelity between legitimate and adversarial samples.
Assist Is Just as Important as the Goal: Image Resurfacing to Aid Model's Robust Prediction
Nov 02, 2023Adversarial patches threaten visual AI models in the real world. The number of patches in a patch attack is variable and determines the attack's potency in a specific environment. Most existing defenses assume a single patch in the scene, and the multiple patch scenarios are shown to overcome them. This paper presents a model-agnostic defense against patch attacks based on total variation for image resurfacing (TVR). The TVR is an image-cleansing method that processes images to remove probable adversarial regions. TVR can be utilized solely or augmented with a defended model, providing multi-level security for robust prediction. TVR nullifies the influence of patches in a single image scan with no prior assumption on the number of patches in the scene. We validate TVR on the ImageNet-Patch benchmark dataset and with real-world physical objects, demonstrating its ability to mitigate patch attack.
NSA: Naturalistic Support Artifact to Boost Network Confidence
Jul 27, 2023



Visual AI systems are vulnerable to natural and synthetic physical corruption in the real-world. Such corruption often arises unexpectedly and alters the model's performance. In recent years, the primary focus has been on adversarial attacks. However, natural corruptions (e.g., snow, fog, dust) are an omnipresent threat to visual AI systems and should be considered equally important. Many existing works propose interesting solutions to train robust models against natural corruption. These works either leverage image augmentations, which come with the additional cost of model training, or place suspicious patches in the scene to design unadversarial examples. In this work, we propose the idea of naturalistic support artifacts (NSA) for robust prediction. The NSAs are shown to be beneficial in scenarios where model parameters are inaccessible and adding artifacts in the scene is feasible. The NSAs are natural looking objects generated through artifact training using DC-GAN to have high visual fidelity in the scene. We test against natural corruptions on the Imagenette dataset and observe the improvement in prediction confidence score by four times. We also demonstrate NSA's capability to increase adversarial accuracy by 8\% on average. Lastly, we qualitatively analyze NSAs using saliency maps to understand how they help improve prediction confidence.
Do we need entire training data for adversarial training?
Mar 10, 2023



Deep Neural Networks (DNNs) are being used to solve a wide range of problems in many domains including safety-critical domains like self-driving cars and medical imagery. DNNs suffer from vulnerability against adversarial attacks. In the past few years, numerous approaches have been proposed to tackle this problem by training networks using adversarial training. Almost all the approaches generate adversarial examples for the entire training dataset, thus increasing the training time drastically. We show that we can decrease the training time for any adversarial training algorithm by using only a subset of training data for adversarial training. To select the subset, we filter the adversarially-prone samples from the training data. We perform a simple adversarial attack on all training examples to filter this subset. In this attack, we add a small perturbation to each pixel and a few grid lines to the input image. We perform adversarial training on the adversarially-prone subset and mix it with vanilla training performed on the entire dataset. Our results show that when our method-agnostic approach is plugged into FGSM, we achieve a speedup of 3.52x on MNIST and 1.98x on the CIFAR-10 dataset with comparable robust accuracy. We also test our approach on state-of-the-art Free adversarial training and achieve a speedup of 1.2x in training time with a marginal drop in robust accuracy on the ImageNet dataset.
Adversarial Patch Attacks and Defences in Vision-Based Tasks: A Survey
Jun 16, 2022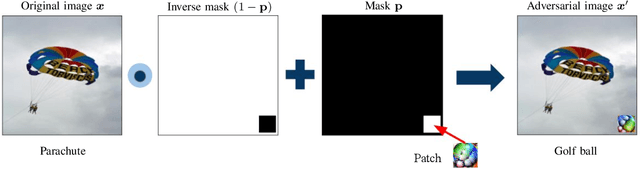


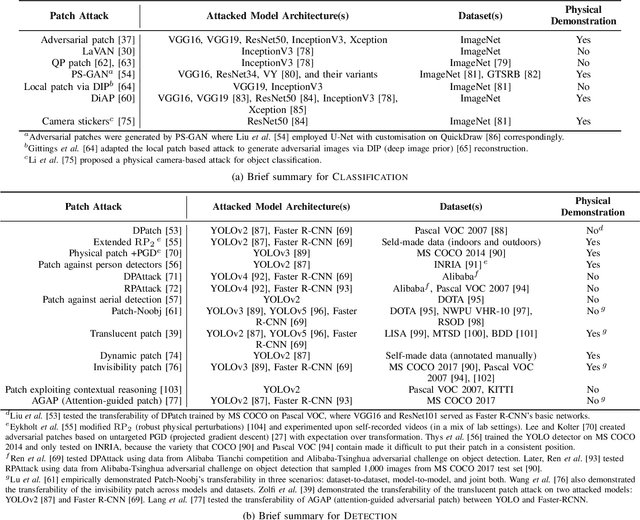
Adversarial attacks in deep learning models, especially for safety-critical systems, are gaining more and more attention in recent years, due to the lack of trust in the security and robustness of AI models. Yet the more primitive adversarial attacks might be physically infeasible or require some resources that are hard to access like the training data, which motivated the emergence of patch attacks. In this survey, we provide a comprehensive overview to cover existing techniques of adversarial patch attacks, aiming to help interested researchers quickly catch up with the progress in this field. We also discuss existing techniques for developing detection and defences against adversarial patches, aiming to help the community better understand this field and its applications in the real world.
Soft Adversarial Training Can Retain Natural Accuracy
Jun 04, 2022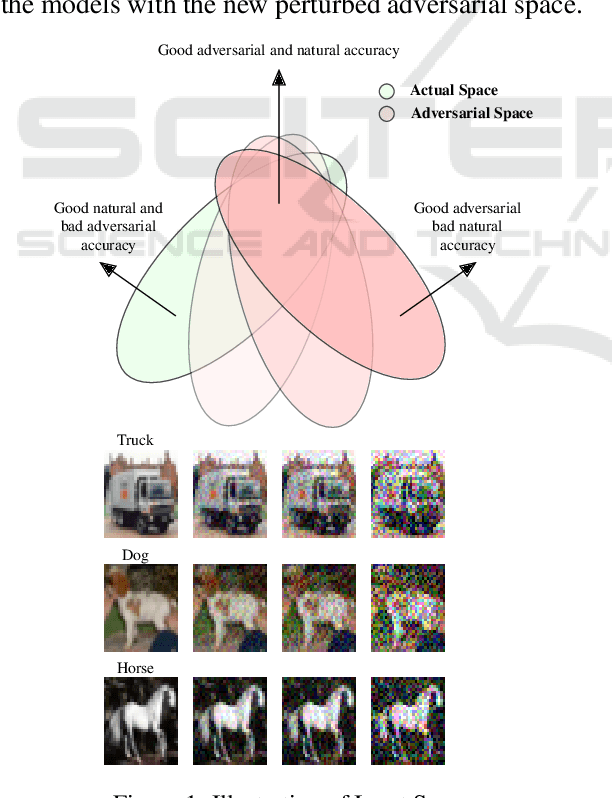
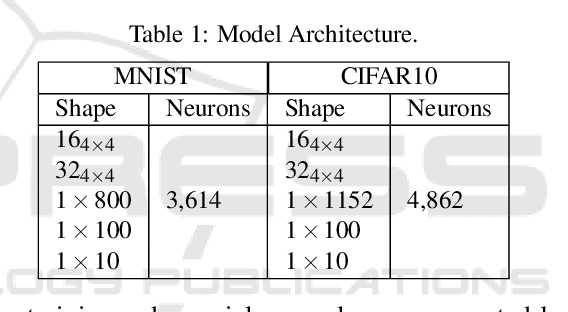
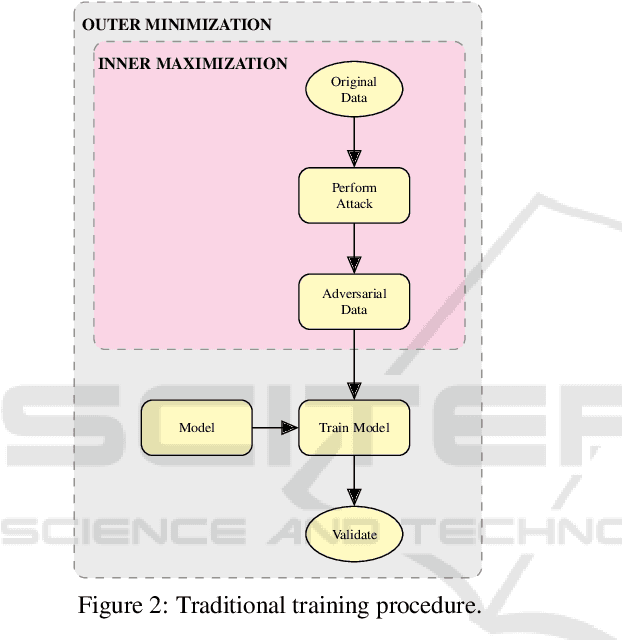
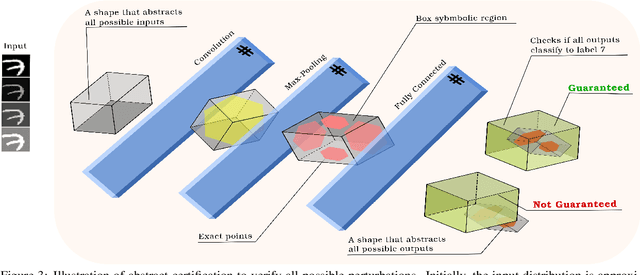
Adversarial training for neural networks has been in the limelight in recent years. The advancement in neural network architectures over the last decade has led to significant improvement in their performance. It sparked an interest in their deployment for real-time applications. This process initiated the need to understand the vulnerability of these models to adversarial attacks. It is instrumental in designing models that are robust against adversaries. Recent works have proposed novel techniques to counter the adversaries, most often sacrificing natural accuracy. Most suggest training with an adversarial version of the inputs, constantly moving away from the original distribution. The focus of our work is to use abstract certification to extract a subset of inputs for (hence we call it 'soft') adversarial training. We propose a training framework that can retain natural accuracy without sacrificing robustness in a constrained setting. Our framework specifically targets moderately critical applications which require a reasonable balance between robustness and accuracy. The results testify to the idea of soft adversarial training for the defense against adversarial attacks. At last, we propose the scope of future work for further improvement of this framework.
* 7 pages, 6 figures
Spiking Approximations of the MaxPooling Operation in Deep SNNs
May 14, 2022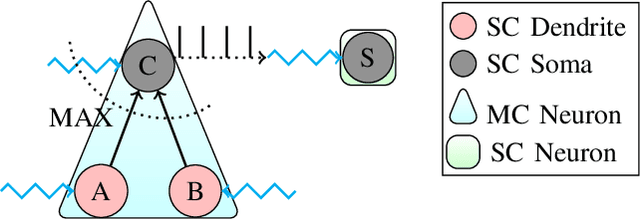
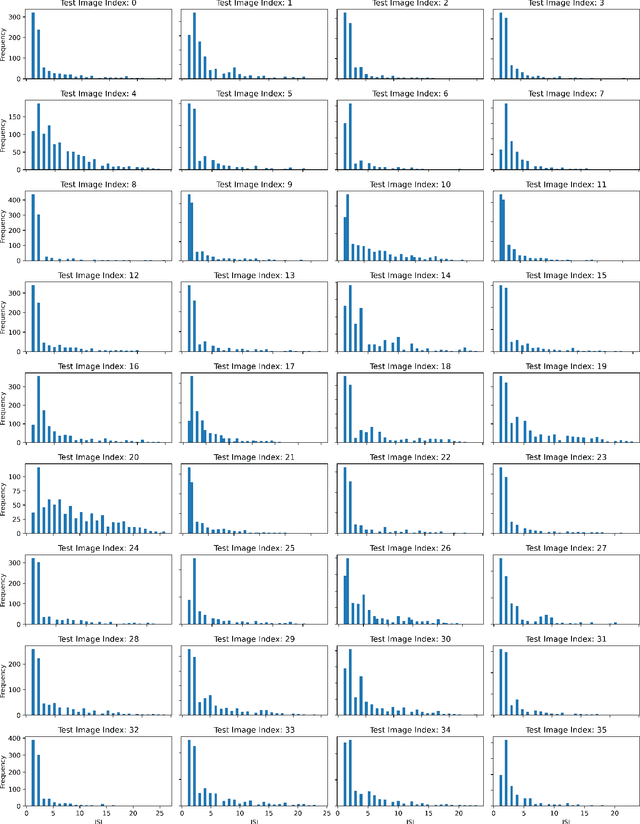
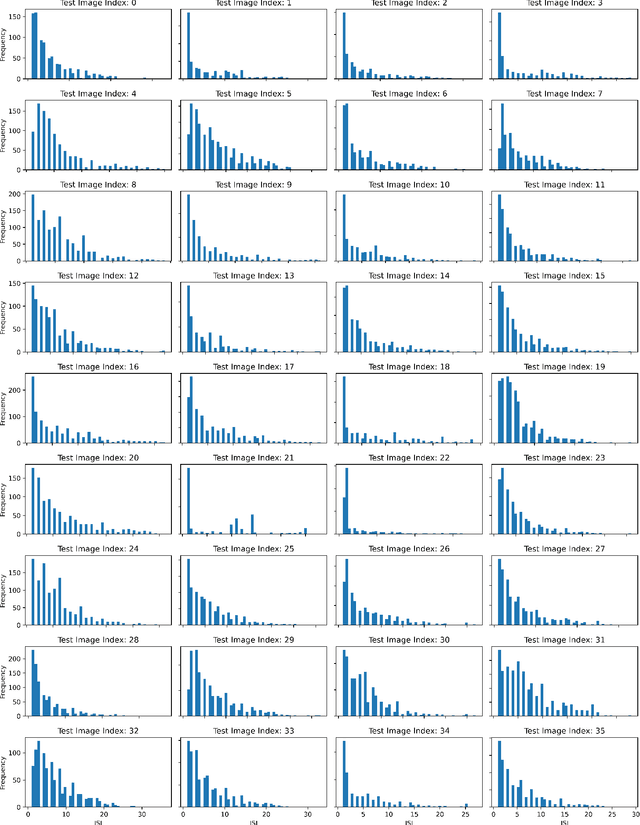
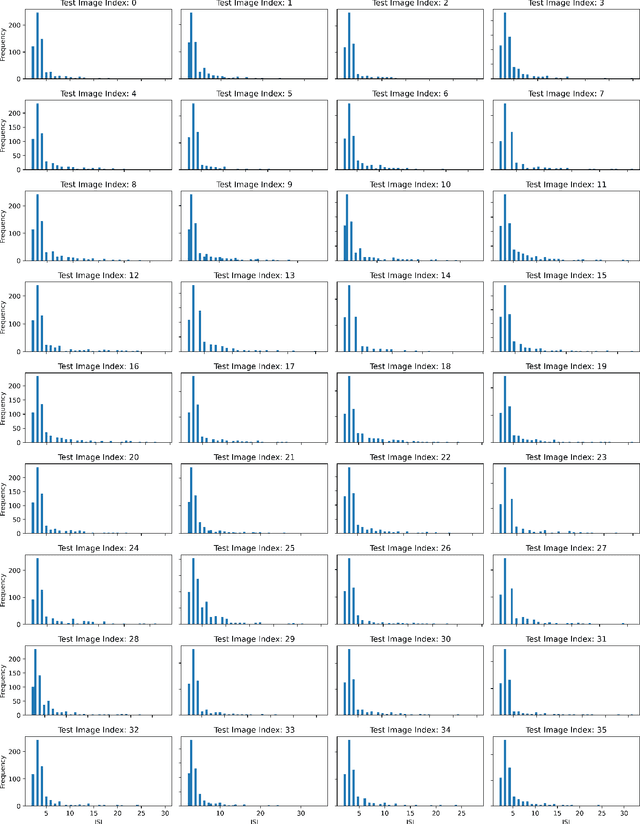
Spiking Neural Networks (SNNs) are an emerging domain of biologically inspired neural networks that have shown promise for low-power AI. A number of methods exist for building deep SNNs, with Artificial Neural Network (ANN)-to-SNN conversion being highly successful. MaxPooling layers in Convolutional Neural Networks (CNNs) are an integral component to downsample the intermediate feature maps and introduce translational invariance, but the absence of their hardware-friendly spiking equivalents limits such CNNs' conversion to deep SNNs. In this paper, we present two hardware-friendly methods to implement Max-Pooling in deep SNNs, thus facilitating easy conversion of CNNs with MaxPooling layers to SNNs. In a first, we also execute SNNs with spiking-MaxPooling layers on Intel's Loihi neuromorphic hardware (with MNIST, FMNIST, & CIFAR10 dataset); thus, showing the feasibility of our approach.
Deep Learning for System Trace Restoration
Apr 10, 2019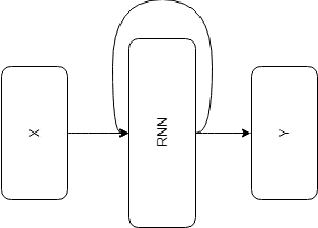
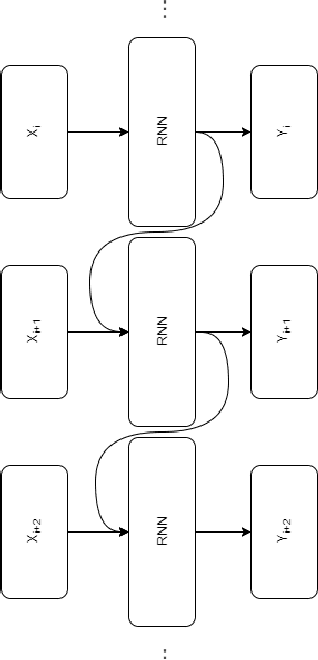
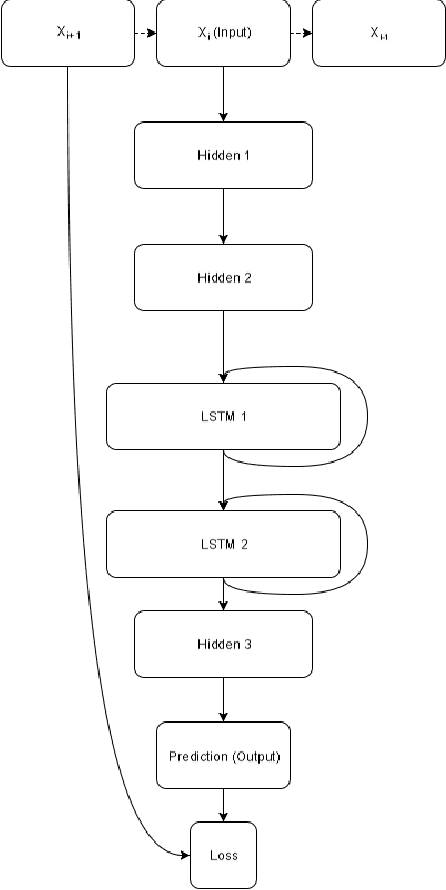
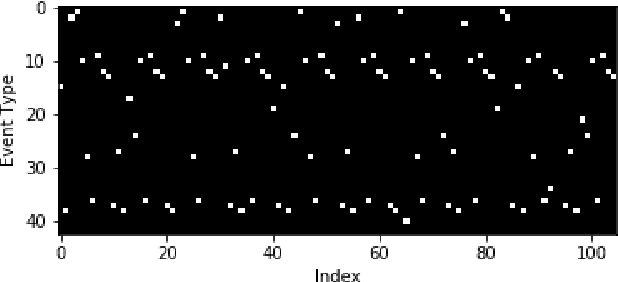
Most real-world datasets, and particularly those collected from physical systems, are full of noise, packet loss, and other imperfections. However, most specification mining, anomaly detection and other such algorithms assume, or even require, perfect data quality to function properly. Such algorithms may work in lab conditions when given clean, controlled data, but will fail in the field when given imperfect data. We propose a method for accurately reconstructing discrete temporal or sequential system traces affected by data loss, using Long Short-Term Memory Networks (LSTMs). The model works by learning to predict the next event in a sequence of events, and uses its own output as an input to continue predicting future events. As a result, this method can be used for data restoration even with streamed data. Such a method can reconstruct even long sequence of missing events, and can also help validate and improve data quality for noisy data. The output of the model will be a close reconstruction of the true data, and can be fed to algorithms that rely on clean data. We demonstrate our method by reconstructing automotive CAN traces consisting of long sequences of discrete events. We show that given even small parts of a CAN trace, our LSTM model can predict future events with an accuracy of almost 90%, and can successfully reconstruct large portions of the original trace, greatly outperforming a Markov Model benchmark. We separately feed the original, lossy, and reconstructed traces into a specification mining framework to perform downstream analysis of the effect of our method on state-of-the-art models that use these traces for understanding the behavior of complex systems.