 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny-Class Presence Likelihood for Robust Multi-Label Classification with Abundant Negative Data
Jun 06, 2025



Multi-label Classification (MLC) assigns an instance to one or more non-exclusive classes. A challenge arises when the dataset contains a large proportion of instances with no assigned class, referred to as negative data, which can overwhelm the learning process and hinder the accurate identification and classification of positive instances. Nevertheless, it is common in MLC applications such as industrial defect detection, agricultural disease identification, and healthcare diagnosis to encounter large amounts of negative data. Assigning a separate negative class to these instances further complicates the learning objective and introduces unnecessary redundancies. To address this challenge, we redesign standard MLC loss functions by deriving a likelihood of any class being present, formulated by a normalized weighted geometric mean of the predicted class probabilities. We introduce a regularization parameter that controls the relative contribution of the absent class probabilities to the any-class presence likelihood in positive instances. The any-class presence likelihood complements the multi-label learning by encouraging the network to become more aware of implicit positive instances and improve the label classification within those positive instances. Experiments on large-scale datasets with negative data: SewerML, modified COCO, and ChestX-ray14, across various networks and base loss functions show that our loss functions consistently improve MLC performance of their standard loss counterparts, achieving gains of up to 6.01 percentage points in F1, 8.06 in F2, and 3.11 in mean average precision, all without additional parameters or computational complexity. Code available at: https://github.com/ML-for-Sensor-Data-Western/gmean-mlc
Federated Learning for Anomaly Detection in Energy Consumption Data: Assessing the Vulnerability to Adversarial Attacks
Feb 07, 2025
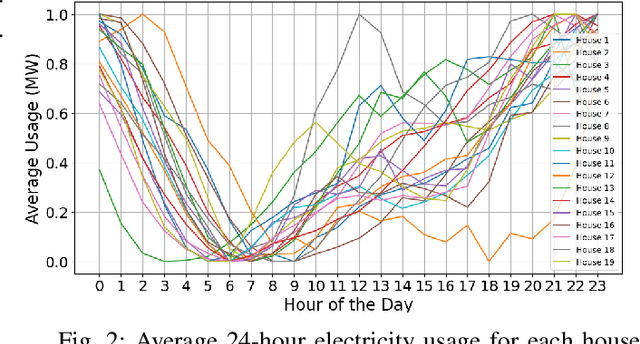
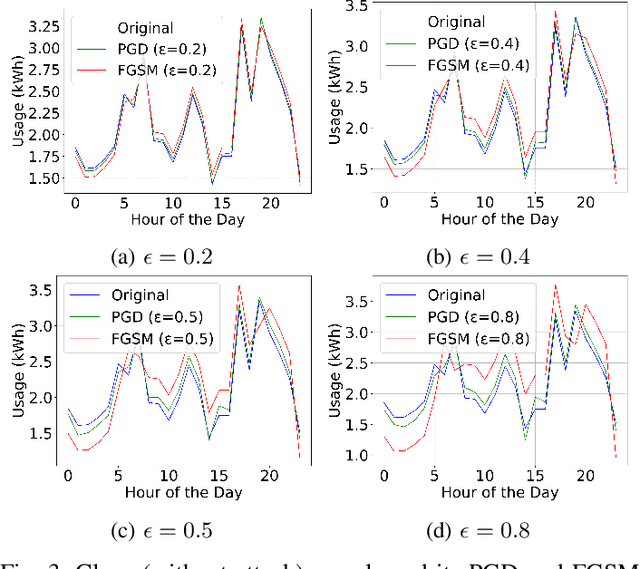
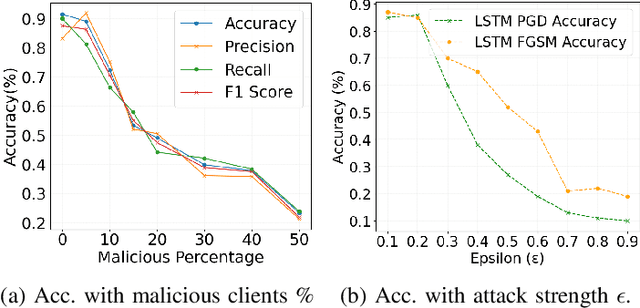
Anomaly detection is crucial in the energy sector to identify irregular patterns indicating equipment failures, energy theft, or other issues. Machine learning techniques for anomaly detection have achieved great success, but are typically centralized, involving sharing local data with a central server which raises privacy and security concerns. Federated Learning (FL) has been gaining popularity as it enables distributed learning without sharing local data. However, FL depends on neural networks, which are vulnerable to adversarial attacks that manipulate data, leading models to make erroneous predictions. While adversarial attacks have been explored in the image domain, they remain largely unexplored in time series problems, especially in the energy domain. Moreover, the effect of adversarial attacks in the FL setting is also mostly unknown. This paper assesses the vulnerability of FL-based anomaly detection in energy data to adversarial attacks. Specifically, two state-of-the-art models, Long Short Term Memory (LSTM) and Transformers, are used to detect anomalies in an FL setting, and two white-box attack methods, Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD), are employed to perturb the data. The results show that FL is more sensitive to PGD attacks than to FGSM attacks, attributed to PGD's iterative nature, resulting in an accuracy drop of over 10% even with naive, weaker attacks. Moreover, FL is more affected by these attacks than centralized learning, highlighting the need for defense mechanisms in FL.
Neural Mixture Models with Expectation-Maximization for End-to-end Deep Clustering
Jul 06, 2021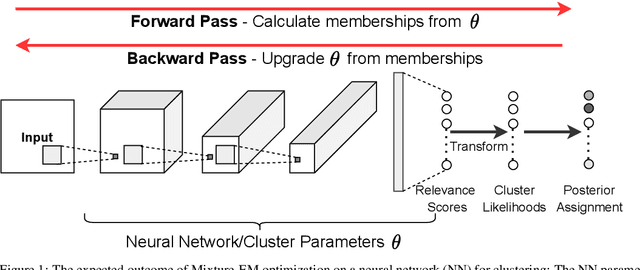

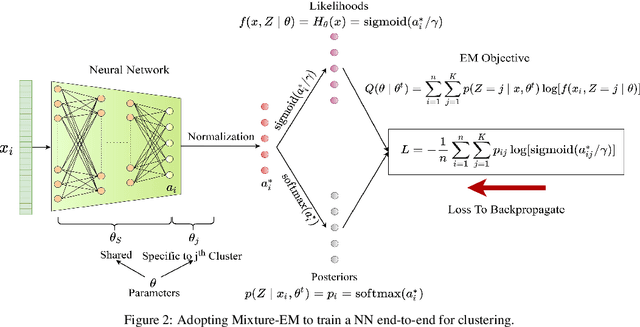

Any clustering algorithm must synchronously learn to model the clusters and allocate data to those clusters in the absence of labels. Mixture model-based methods model clusters with pre-defined statistical distributions and allocate data to those clusters based on the cluster likelihoods. They iteratively refine those distribution parameters and member assignments following the Expectation-Maximization (EM) algorithm. However, the cluster representability of such hand-designed distributions that employ a limited amount of parameters is not adequate for most real-world clustering tasks. In this paper, we realize mixture model-based clustering with a neural network where the final layer neurons, with the aid of an additional transformation, approximate cluster distribution outputs. The network parameters pose as the parameters of those distributions. The result is an elegant, much-generalized representation of clusters than a restricted mixture of hand-designed distributions. We train the network end-to-end via batch-wise EM iterations where the forward pass acts as the E-step and the backward pass acts as the M-step. In image clustering, the mixture-based EM objective can be used as the clustering objective along with existing representation learning methods. In particular, we show that when mixture-EM optimization is fused with consistency optimization, it improves the sole consistency optimization performance in clustering. Our trained networks outperform single-stage deep clustering methods that still depend on k-means, with unsupervised classification accuracy of 63.8% in STL10, 58% in CIFAR10, 25.9% in CIFAR100, and 98.9% in MNIST.
End-To-End Data-Dependent Routing in Multi-Path Neural Networks
Jul 06, 2021
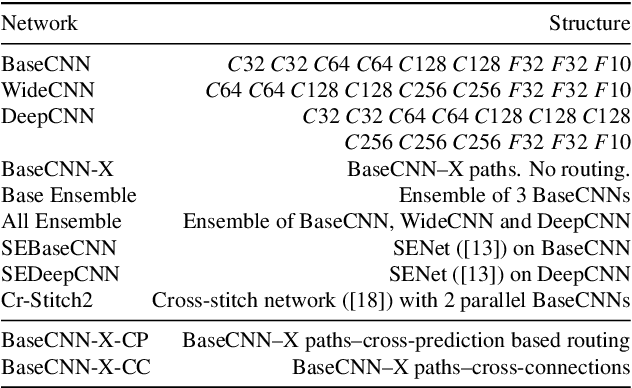

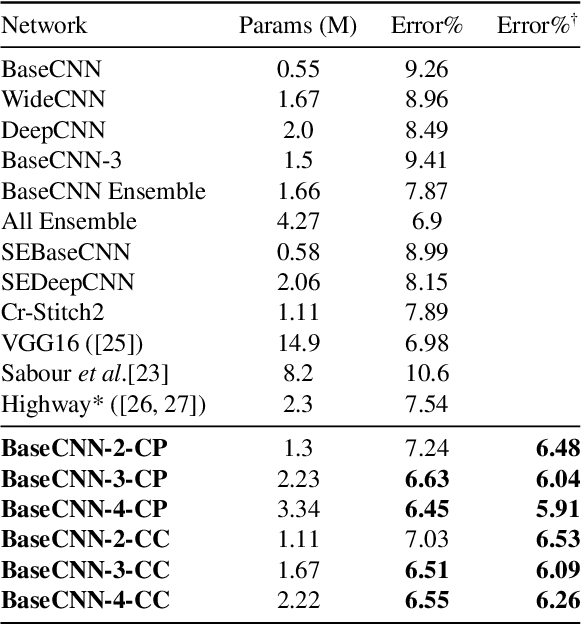
Neural networks are known to give better performance with increased depth due to their ability to learn more abstract features. Although the deepening of networks has been well established, there is still room for efficient feature extraction within a layer which would reduce the need for mere parameter increment. The conventional widening of networks by having more filters in each layer introduces a quadratic increment of parameters. Having multiple parallel convolutional/dense operations in each layer solves this problem, but without any context-dependent allocation of resources among these operations: the parallel computations tend to learn similar features making the widening process less effective. Therefore, we propose the use of multi-path neural networks with data-dependent resource allocation among parallel computations within layers, which also lets an input to be routed end-to-end through these parallel paths. To do this, we first introduce a cross-prediction based algorithm between parallel tensors of subsequent layers. Second, we further reduce the routing overhead by introducing feature-dependent cross-connections between parallel tensors of successive layers. Our multi-path networks show superior performance to existing widening and adaptive feature extraction, and even ensembles, and deeper networks at similar complexity in the image recognition task.
Transferring Domain Knowledge with an Adviser in Continuous Tasks
Feb 16, 2021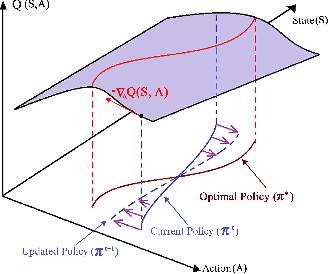
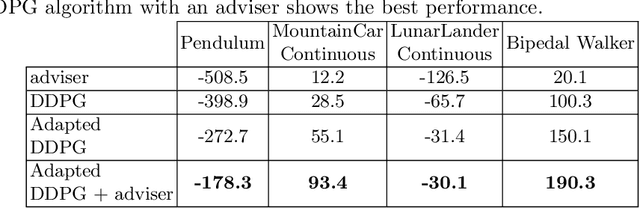
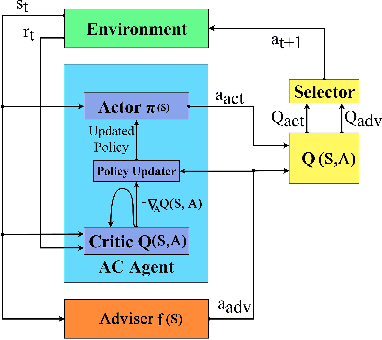

Recent advances in Reinforcement Learning (RL) have surpassed human-level performance in many simulated environments. However, existing reinforcement learning techniques are incapable of explicitly incorporating already known domain-specific knowledge into the learning process. Therefore, the agents have to explore and learn the domain knowledge independently through a trial and error approach, which consumes both time and resources to make valid responses. Hence, we adapt the Deep Deterministic Policy Gradient (DDPG) algorithm to incorporate an adviser, which allows integrating domain knowledge in the form of pre-learned policies or pre-defined relationships to enhance the agent's learning process. Our experiments on OpenAi Gym benchmark tasks show that integrating domain knowledge through advisers expedites the learning and improves the policy towards better optima.
Anomaly Detection using Deep Reconstruction and Forecasting for Autonomous Systems
Jun 25, 2020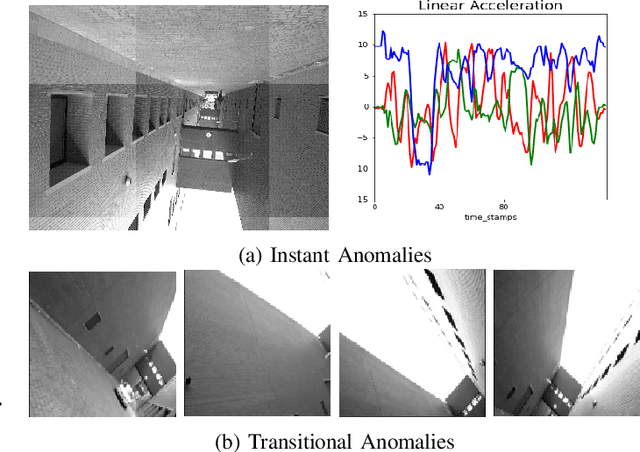

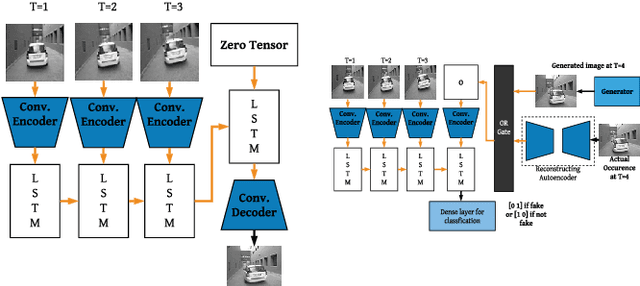

We propose self-supervised deep algorithms to detect anomalies in heterogeneous autonomous systems using frontal camera video and IMU readings. Given that the video and IMU data are not synchronized, each of them are analyzed separately. The vision-based system, which utilizes a conditional GAN, analyzes immediate-past three frames and attempts to predict the next frame. The frame is classified as either an anomalous case or a normal case based on the degree of difference estimated using the prediction error and a threshold. The IMU-based system utilizes two approaches to classify the timestamps; the first being an LSTM autoencoder which reconstructs three consecutive IMU vectors and the second being an LSTM forecaster which is utilized to predict the next vector using the previous three IMU vectors. Based on the reconstruction error, the prediction error, and a threshold, the timestamp is classified as either an anomalous case or a normal case. The composition of algorithms won runners up at the IEEE Signal Processing Cup anomaly detection challenge 2020. In the competition dataset of camera frames consisting of both normal and anomalous cases, we achieve a test accuracy of 94% and an F1-score of 0.95. Furthermore, we achieve an accuracy of 100% on a test set containing normal IMU data, and an F1-score of 0.98 on the test set of abnormal IMU data.
Feature-dependent Cross-Connections in Multi-Path Neural Networks
Jun 24, 2020
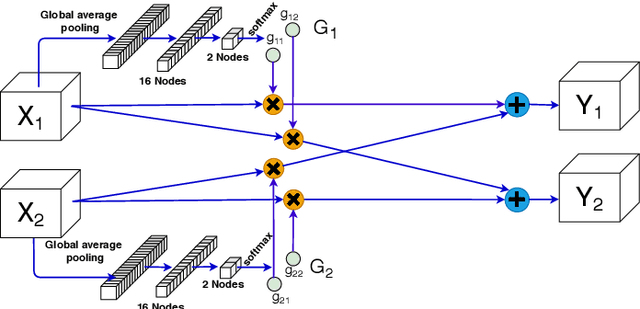
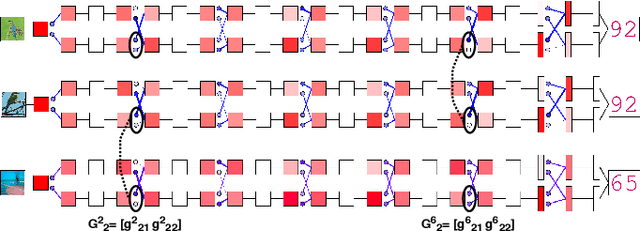

Learning a particular task from a dataset, samples in which originate from diverse contexts, is challenging, and usually addressed by deepening or widening standard neural networks. As opposed to conventional network widening, multi-path architectures restrict the quadratic increment of complexity to a linear scale. However, existing multi-column/path networks or model ensembling methods do not consider any feature-dependent allocation of parallel resources, and therefore, tend to learn redundant features. Given a layer in a multi-path network, if we restrict each path to learn a context-specific set of features and introduce a mechanism to intelligently allocate incoming feature maps to such paths, each path can specialize in a certain context, reducing the redundancy and improving the quality of extracted features. This eventually leads to better-optimized usage of parallel resources. To do this, we propose inserting feature-dependent cross-connections between parallel sets of feature maps in successive layers. The weights of these cross-connections are learned based on the input features of the particular layer. Our multi-path networks show improved image recognition accuracy at a similar complexity compared to conventional and state-of-the-art methods for deepening, widening and adaptive feature extracting, in both small and large scale datasets.
Context-Aware Multipath Networks
Jul 26, 2019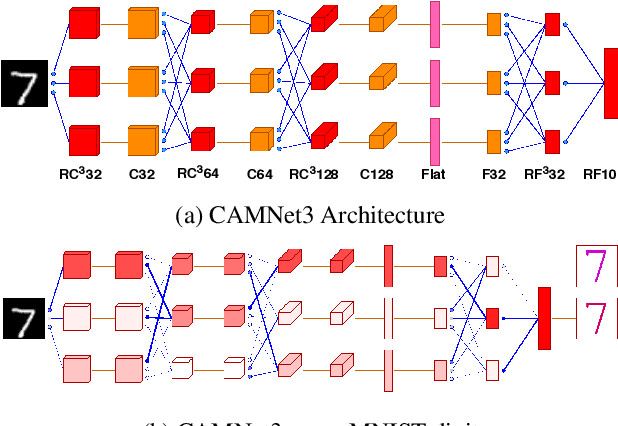

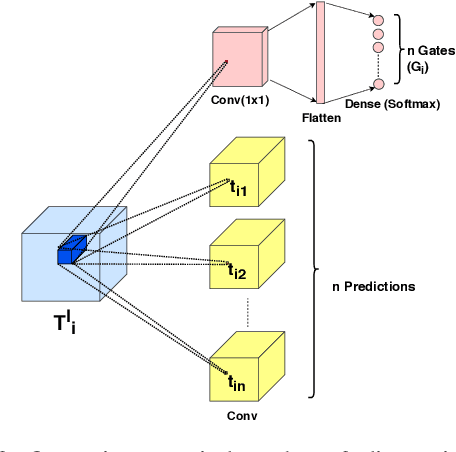
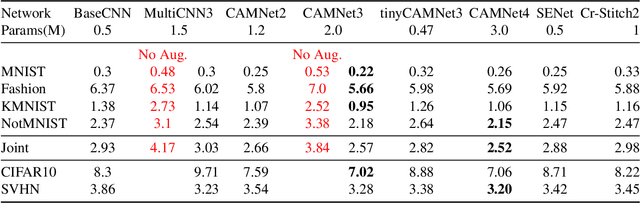
Making a single network effectively address diverse contexts---learning the variations within a dataset or multiple datasets---is an intriguing step towards achieving generalized intelligence. Existing approaches of deepening, widening, and assembling networks are not cost effective in general. In view of this, networks which can allocate resources according to the context of the input and regulate flow of information across the network are effective. In this paper, we present Context-Aware Multipath Network (CAMNet), a multi-path neural network with data-dependant routing between parallel tensors. We show that our model performs as a generalized model capturing variations in individual datasets and multiple different datasets, both simultaneously and sequentially. CAMNet surpasses the performance of classification and pixel-labeling tasks in comparison with the equivalent single-path, multi-path, and deeper single-path networks, considering datasets individually, sequentially, and in combination. The data-dependent routing between tensors in CAMNet enables the model to control the flow of information end-to-end, deciding which resources to be common or domain-specific.
Context-Aware Automatic Occlusion Removal
May 07, 2019

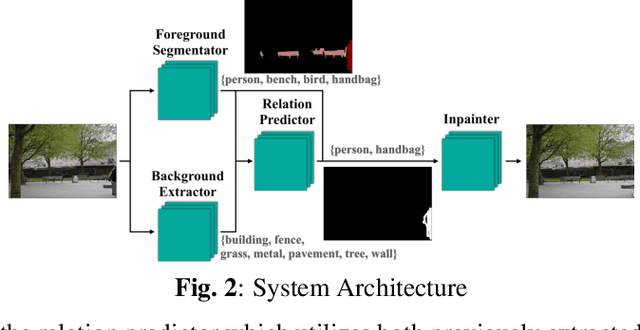

Occlusion removal is an interesting application of image enhancement, for which, existing work suggests manually-annotated or domain-specific occlusion removal. No work tries to address automatic occlusion detection and removal as a context-aware generic problem. In this paper, we present a novel methodology to identify objects that do not relate to the image context as occlusions and remove them, reconstructing the space occupied coherently. The proposed system detects occlusions by considering the relation between foreground and background object classes represented as vector embeddings, and removes them through inpainting. We test our system on COCO-Stuff dataset and conduct a user study to establish a baseline in context-aware automatic occlusion removal.