 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized Information Flow for Transformer Tracking
Feb 13, 2024



One-stream Transformer trackers have shown outstanding performance in challenging benchmark datasets over the last three years, as they enable interaction between the target template and search region tokens to extract target-oriented features with mutual guidance. Previous approaches allow free bidirectional information flow between template and search tokens without investigating their influence on the tracker's discriminative capability. In this study, we conducted a detailed study on the information flow of the tokens and based on the findings, we propose a novel Optimized Information Flow Tracking (OIFTrack) framework to enhance the discriminative capability of the tracker. The proposed OIFTrack blocks the interaction from all search tokens to target template tokens in early encoder layers, as the large number of non-target tokens in the search region diminishes the importance of target-specific features. In the deeper encoder layers of the proposed tracker, search tokens are partitioned into target search tokens and non-target search tokens, allowing bidirectional flow from target search tokens to template tokens to capture the appearance changes of the target. In addition, since the proposed tracker incorporates dynamic background cues, distractor objects are successfully avoided by capturing the surrounding information of the target. The OIFTrack demonstrated outstanding performance in challenging benchmarks, particularly excelling in the one-shot tracking benchmark GOT-10k, achieving an average overlap of 74.6\%. The code, models, and results of this work are available at \url{https://github.com/JananiKugaa/OIFTrack}
Transformers in Single Object Tracking: An Experimental Survey
Feb 23, 2023



Single object tracking is a well-known and challenging research topic in computer vision. Over the last two decades, numerous researchers have proposed various algorithms to solve this problem and achieved promising results. Recently, Transformer-based tracking approaches have ushered in a new era in single object tracking due to their superior tracking robustness. Although several survey studies have been conducted to analyze the performance of trackers, there is a need for another survey study after the introduction of Transformers in single object tracking. In this survey, we aim to analyze the literature and performances of Transformer tracking approaches. Therefore, we conduct an in-depth literature analysis of Transformer tracking approaches and evaluate their tracking robustness and computational efficiency on challenging benchmark datasets. In addition, we have measured their performances on different tracking scenarios to find their strength and weaknesses. Our survey provides insights into the underlying principles of Transformer tracking approaches, the challenges they face, and their future directions.
Neural Mixture Models with Expectation-Maximization for End-to-end Deep Clustering
Jul 06, 2021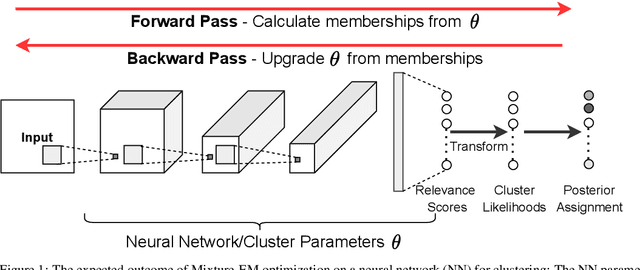

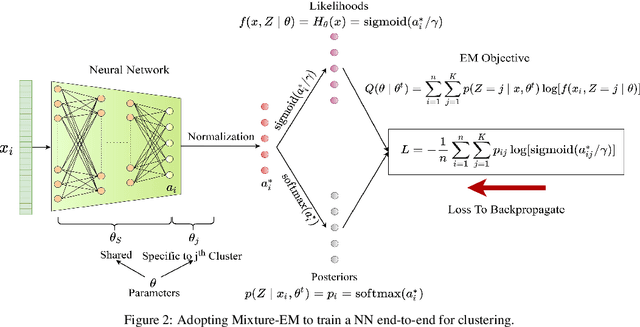

Any clustering algorithm must synchronously learn to model the clusters and allocate data to those clusters in the absence of labels. Mixture model-based methods model clusters with pre-defined statistical distributions and allocate data to those clusters based on the cluster likelihoods. They iteratively refine those distribution parameters and member assignments following the Expectation-Maximization (EM) algorithm. However, the cluster representability of such hand-designed distributions that employ a limited amount of parameters is not adequate for most real-world clustering tasks. In this paper, we realize mixture model-based clustering with a neural network where the final layer neurons, with the aid of an additional transformation, approximate cluster distribution outputs. The network parameters pose as the parameters of those distributions. The result is an elegant, much-generalized representation of clusters than a restricted mixture of hand-designed distributions. We train the network end-to-end via batch-wise EM iterations where the forward pass acts as the E-step and the backward pass acts as the M-step. In image clustering, the mixture-based EM objective can be used as the clustering objective along with existing representation learning methods. In particular, we show that when mixture-EM optimization is fused with consistency optimization, it improves the sole consistency optimization performance in clustering. Our trained networks outperform single-stage deep clustering methods that still depend on k-means, with unsupervised classification accuracy of 63.8% in STL10, 58% in CIFAR10, 25.9% in CIFAR100, and 98.9% in MNIST.
End-To-End Data-Dependent Routing in Multi-Path Neural Networks
Jul 06, 2021
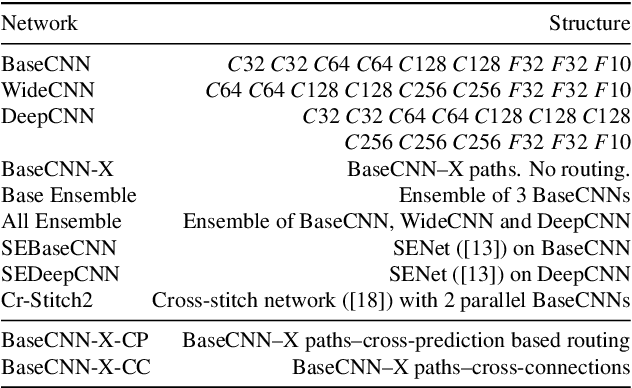

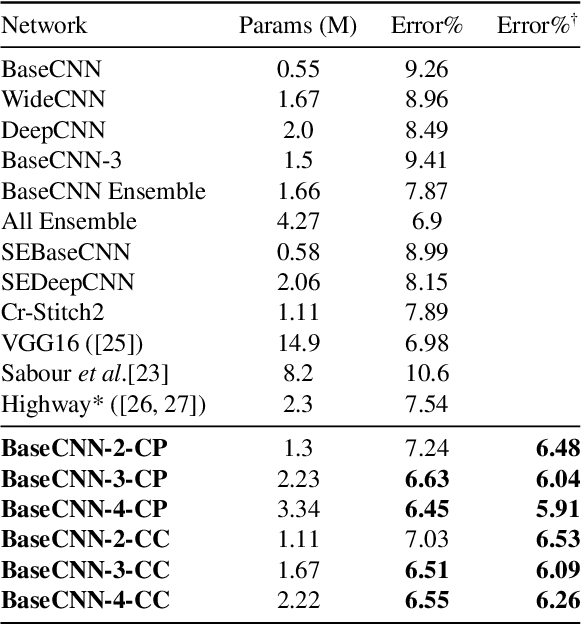
Neural networks are known to give better performance with increased depth due to their ability to learn more abstract features. Although the deepening of networks has been well established, there is still room for efficient feature extraction within a layer which would reduce the need for mere parameter increment. The conventional widening of networks by having more filters in each layer introduces a quadratic increment of parameters. Having multiple parallel convolutional/dense operations in each layer solves this problem, but without any context-dependent allocation of resources among these operations: the parallel computations tend to learn similar features making the widening process less effective. Therefore, we propose the use of multi-path neural networks with data-dependent resource allocation among parallel computations within layers, which also lets an input to be routed end-to-end through these parallel paths. To do this, we first introduce a cross-prediction based algorithm between parallel tensors of subsequent layers. Second, we further reduce the routing overhead by introducing feature-dependent cross-connections between parallel tensors of successive layers. Our multi-path networks show superior performance to existing widening and adaptive feature extraction, and even ensembles, and deeper networks at similar complexity in the image recognition task.
Optimizing robotic swarm based construction tasks
Jun 17, 2021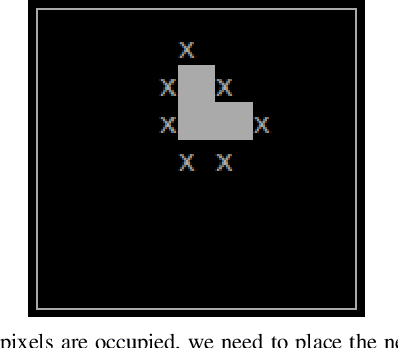
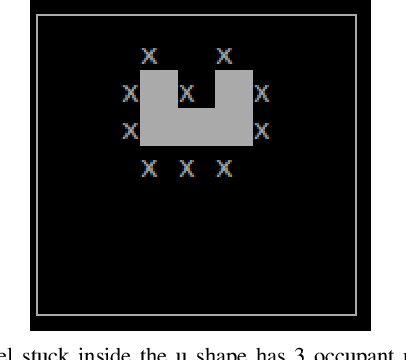
Social insects in nature such as ants, termites and bees construct their colonies collaboratively in a very efficient process. In these swarms, each insect contributes to the construction task individually showing redundant and parallel behavior of individual entities. But the robotics adaptations of these swarm's behaviors haven't yet made it to the real world at a large enough scale of commonly being used due to the limitations in the existing approaches to the swarm robotics construction. This paper presents an approach that combines the existing swarm construction approaches which results in a swarm robotic system, capable of constructing a given 2 dimensional shape in an optimized manner.
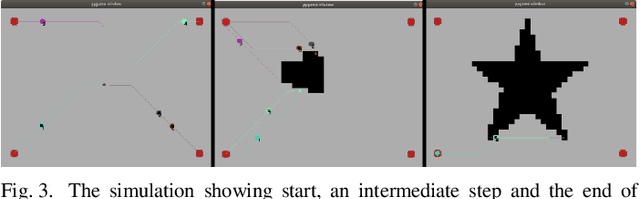
Transferring Domain Knowledge with an Adviser in Continuous Tasks
Feb 16, 2021
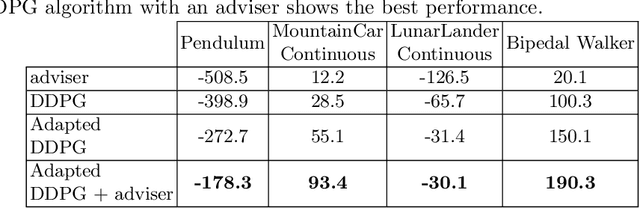
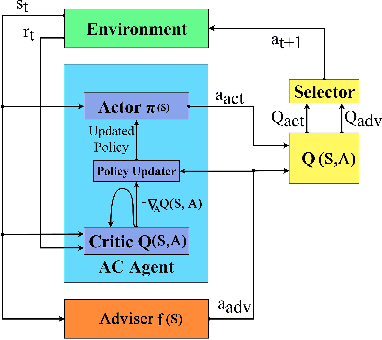

Recent advances in Reinforcement Learning (RL) have surpassed human-level performance in many simulated environments. However, existing reinforcement learning techniques are incapable of explicitly incorporating already known domain-specific knowledge into the learning process. Therefore, the agents have to explore and learn the domain knowledge independently through a trial and error approach, which consumes both time and resources to make valid responses. Hence, we adapt the Deep Deterministic Policy Gradient (DDPG) algorithm to incorporate an adviser, which allows integrating domain knowledge in the form of pre-learned policies or pre-defined relationships to enhance the agent's learning process. Our experiments on OpenAi Gym benchmark tasks show that integrating domain knowledge through advisers expedites the learning and improves the policy towards better optima.
Feature-dependent Cross-Connections in Multi-Path Neural Networks
Jun 24, 2020
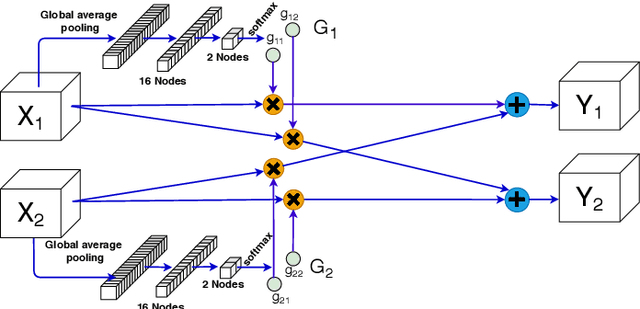
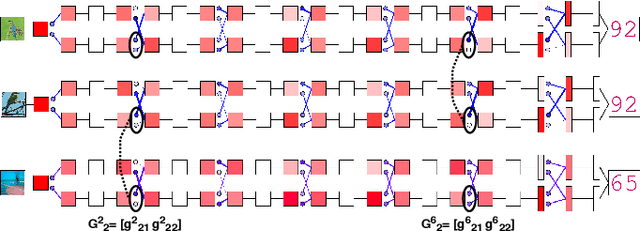

Learning a particular task from a dataset, samples in which originate from diverse contexts, is challenging, and usually addressed by deepening or widening standard neural networks. As opposed to conventional network widening, multi-path architectures restrict the quadratic increment of complexity to a linear scale. However, existing multi-column/path networks or model ensembling methods do not consider any feature-dependent allocation of parallel resources, and therefore, tend to learn redundant features. Given a layer in a multi-path network, if we restrict each path to learn a context-specific set of features and introduce a mechanism to intelligently allocate incoming feature maps to such paths, each path can specialize in a certain context, reducing the redundancy and improving the quality of extracted features. This eventually leads to better-optimized usage of parallel resources. To do this, we propose inserting feature-dependent cross-connections between parallel sets of feature maps in successive layers. The weights of these cross-connections are learned based on the input features of the particular layer. Our multi-path networks show improved image recognition accuracy at a similar complexity compared to conventional and state-of-the-art methods for deepening, widening and adaptive feature extracting, in both small and large scale datasets.
Context-Aware Multipath Networks
Jul 26, 2019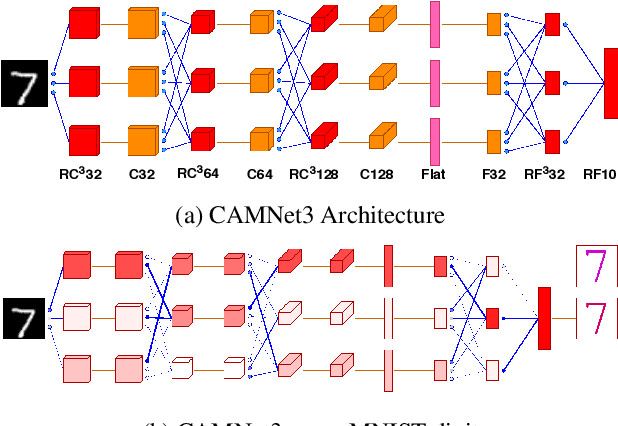

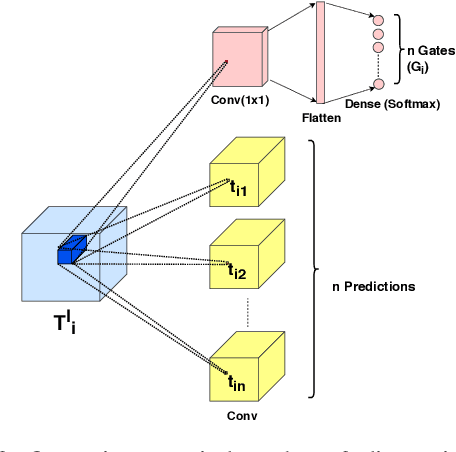
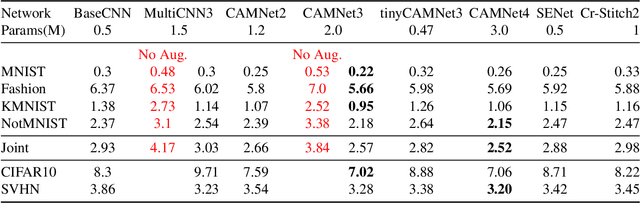
Making a single network effectively address diverse contexts---learning the variations within a dataset or multiple datasets---is an intriguing step towards achieving generalized intelligence. Existing approaches of deepening, widening, and assembling networks are not cost effective in general. In view of this, networks which can allocate resources according to the context of the input and regulate flow of information across the network are effective. In this paper, we present Context-Aware Multipath Network (CAMNet), a multi-path neural network with data-dependant routing between parallel tensors. We show that our model performs as a generalized model capturing variations in individual datasets and multiple different datasets, both simultaneously and sequentially. CAMNet surpasses the performance of classification and pixel-labeling tasks in comparison with the equivalent single-path, multi-path, and deeper single-path networks, considering datasets individually, sequentially, and in combination. The data-dependent routing between tensors in CAMNet enables the model to control the flow of information end-to-end, deciding which resources to be common or domain-specific.