 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVC-FeS: Viewpoint-Conditioned Feature Selection for Vehicle Re-identification in Thermal Vision
May 06, 2026Identification of less-articulated objects using single-channel images, such as thermal images, is important in many applications, such as surveillance. However, in this domain, existing methods show poor performance due to high similarity among objects of the same category in the absence of color information (overlooking shape information) and de-emphasized texture information. Furthermore, variability in viewpoint adds more complexity as the features vary from side to side. We address these issues by constructing viewpoint-conditioned feature vectors and area-specific feature comparisons in separate feature spaces. These interventions enable leveraging the advancements of existing RGB-pre-trained ViT feature extractors while effectively adapting them to address the challenges specific to the thermal domain. We test our system with RGBNT100 (IR) vehicle dataset and a thermal maritime dataset acquired by us. Our results surpass the state-of-the-art methods by 19.7% and 12.8% for the above datasets in mAP scores, respectively. We also plan to make our thermal dataset available, the first of its kind for maritime vessel identification.
SemAlign: Language Guided Semi-supervised Domain Generalization
Jan 16, 2026Semi-supervised Domain Generalization (SSDG) addresses the challenge of generalizing to unseen target domains with limited labeled data. Existing SSDG methods highlight the importance of achieving high pseudo-labeling (PL) accuracy and preventing model overfitting as the main challenges in SSDG. In this light, we show that the SSDG literature's excessive focus on PL accuracy, without consideration for maximum data utilization during training, limits potential performance improvements. We propose a novel approach to the SSDG problem by aligning the intermediate features of our model with the semantically rich and generalized feature space of a Vision Language Model (VLM) in a way that promotes domain-invariance. The above approach is enhanced with effective image-level augmentation and output-level regularization strategies to improve data utilization and minimize overfitting. Extensive experimentation across four benchmarks against existing SSDG baselines suggests that our method achieves SOTA results both qualitatively and quantitatively. The code will be made publicly available.
SENCA-st: Integrating Spatial Transcriptomics and Histopathology with Cross Attention Shared Encoder for Region Identification in Cancer Pathology
Nov 11, 2025Spatial transcriptomics is an emerging field that enables the identification of functional regions based on the spatial distribution of gene expression. Integrating this functional information present in transcriptomic data with structural data from histopathology images is an active research area with applications in identifying tumor substructures associated with cancer drug resistance. Current histopathology-spatial-transcriptomic region segmentation methods suffer due to either making spatial transcriptomics prominent by using histopathology features just to assist processing spatial transcriptomics data or using vanilla contrastive learning that make histopathology images prominent due to only promoting common features losing functional information. In both extremes, the model gets either lost in the noise of spatial transcriptomics or overly smoothed, losing essential information. Thus, we propose our novel architecture SENCA-st (Shared Encoder with Neighborhood Cross Attention) that preserves the features of both modalities. More importantly, it emphasizes regions that are structurally similar in histopathology but functionally different on spatial transcriptomics using cross-attention. We demonstrate the superior performance of our model that surpasses state-of-the-art methods in detecting tumor heterogeneity and tumor micro-environment regions, a clinically crucial aspect.
A-TPT: Angular Diversity Calibration Properties for Test-Time Prompt Tuning of Vision-Language Models
Oct 30, 2025Test-time prompt tuning (TPT) has emerged as a promising technique for adapting large vision-language models (VLMs) to unseen tasks without relying on labeled data. However, the lack of dispersion between textual features can hurt calibration performance, which raises concerns about VLMs' reliability, trustworthiness, and safety. Current TPT approaches primarily focus on improving prompt calibration by either maximizing average textual feature dispersion or enforcing orthogonality constraints to encourage angular separation. However, these methods may not always have optimal angular separation between class-wise textual features, which implies overlooking the critical role of angular diversity. To address this, we propose A-TPT, a novel TPT framework that introduces angular diversity to encourage uniformity in the distribution of normalized textual features induced by corresponding learnable prompts. This uniformity is achieved by maximizing the minimum pairwise angular distance between features on the unit hypersphere. We show that our approach consistently surpasses state-of-the-art TPT methods in reducing the aggregate average calibration error while maintaining comparable accuracy through extensive experiments with various backbones on different datasets. Notably, our approach exhibits superior zero-shot calibration performance on natural distribution shifts and generalizes well to medical datasets. We provide extensive analyses, including theoretical aspects, to establish the grounding of A-TPT. These results highlight the potency of promoting angular diversity to achieve well-dispersed textual features, significantly improving VLM calibration during test-time adaptation. Our code will be made publicly available.
Uncertainty Awareness Enables Efficient Labeling for Cancer Subtyping in Digital Pathology
Jun 13, 2025



Machine-learning-assisted cancer subtyping is a promising avenue in digital pathology. Cancer subtyping models, however, require careful training using expert annotations so that they can be inferred with a degree of known certainty (or uncertainty). To this end, we introduce the concept of uncertainty awareness into a self-supervised contrastive learning model. This is achieved by computing an evidence vector at every epoch, which assesses the model's confidence in its predictions. The derived uncertainty score is then utilized as a metric to selectively label the most crucial images that require further annotation, thus iteratively refining the training process. With just 1-10% of strategically selected annotations, we attain state-of-the-art performance in cancer subtyping on benchmark datasets. Our method not only strategically guides the annotation process to minimize the need for extensive labeled datasets, but also improves the precision and efficiency of classifications. This development is particularly beneficial in settings where the availability of labeled data is limited, offering a promising direction for future research and application in digital pathology.
Feature Modulation for Semi-Supervised Domain Generalization without Domain Labels
Mar 26, 2025



Semi-supervised domain generalization (SSDG) leverages a small fraction of labeled data alongside unlabeled data to enhance model generalization. Most of the existing SSDG methods rely on pseudo-labeling (PL) for unlabeled data, often assuming access to domain labels-a privilege not always available. However, domain shifts introduce domain noise, leading to inconsistent PLs that degrade model performance. Methods derived from FixMatch suffer particularly from lower PL accuracy, reducing the effectiveness of unlabeled data. To address this, we tackle the more challenging domain-label agnostic SSDG, where domain labels for unlabeled data are not available during training. First, we propose a feature modulation strategy that enhances class-discriminative features while suppressing domain-specific information. This modulation shifts features toward Similar Average Representations-a modified version of class prototypes-that are robust across domains, encouraging the classifier to distinguish between closely related classes and feature extractor to form tightly clustered, domain-invariant representations. Second, to mitigate domain noise and improve pseudo-label accuracy, we introduce a loss-scaling function that dynamically lowers the fixed confidence threshold for pseudo-labels, optimizing the use of unlabeled data. With these key innovations, our approach achieves significant improvements on four major domain generalization benchmarks-even without domain labels. We will make the code available.
DARB-Splatting: Generalizing Splatting with Decaying Anisotropic Radial Basis Functions
Jan 21, 2025



Splatting-based 3D reconstruction methods have gained popularity with the advent of 3D Gaussian Splatting, efficiently synthesizing high-quality novel views. These methods commonly resort to using exponential family functions, such as the Gaussian function, as reconstruction kernels due to their anisotropic nature, ease of projection, and differentiability in rasterization. However, the field remains restricted to variations within the exponential family, leaving generalized reconstruction kernels largely underexplored, partly due to the lack of easy integrability in 3D to 2D projections. In this light, we show that a class of decaying anisotropic radial basis functions (DARBFs), which are non-negative functions of the Mahalanobis distance, supports splatting by approximating the Gaussian function's closed-form integration advantage. With this fresh perspective, we demonstrate up to 34% faster convergence during training and a 15% reduction in memory consumption across various DARB reconstruction kernels, while maintaining comparable PSNR, SSIM, and LPIPS results. We will make the code available.
Test-Time Optimization for Domain Adaptive Open Vocabulary Segmentation
Jan 08, 2025



We present Seg-TTO, a novel framework for zero-shot, open-vocabulary semantic segmentation (OVSS), designed to excel in specialized domain tasks. While current open vocabulary approaches show impressive performance on standard segmentation benchmarks under zero-shot settings, they fall short of supervised counterparts on highly domain-specific datasets. We focus on segmentation-specific test-time optimization to address this gap. Segmentation requires an understanding of multiple concepts within a single image while retaining the locality and spatial structure of representations. We propose a novel self-supervised objective adhering to these requirements and use it to align the model parameters with input images at test time. In the textual modality, we learn multiple embeddings for each category to capture diverse concepts within an image, while in the visual modality, we calculate pixel-level losses followed by embedding aggregation operations specific to preserving spatial structure. Our resulting framework termed Seg-TTO is a plug-in-play module. We integrate Seg-TTO with three state-of-the-art OVSS approaches and evaluate across 22 challenging OVSS tasks covering a range of specialized domains. Our Seg-TTO demonstrates clear performance improvements across these establishing new state-of-the-art. Code: https://github.com/UlinduP/SegTTO.
A Feature Generator for Few-Shot Learning
Sep 21, 2024

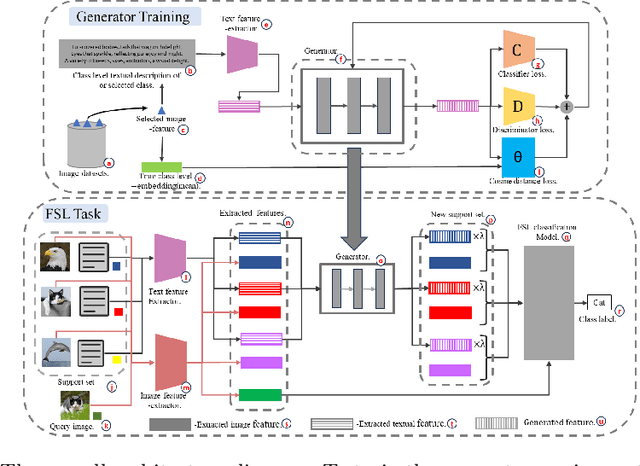

Few-shot learning (FSL) aims to enable models to recognize novel objects or classes with limited labelled data. Feature generators, which synthesize new data points to augment limited datasets, have emerged as a promising solution to this challenge. This paper investigates the effectiveness of feature generators in enhancing the embedding process for FSL tasks. To address the issue of inaccurate embeddings due to the scarcity of images per class, we introduce a feature generator that creates visual features from class-level textual descriptions. By training the generator with a combination of classifier loss, discriminator loss, and distance loss between the generated features and true class embeddings, we ensure the generation of accurate same-class features and enhance the overall feature representation. Our results show a significant improvement in accuracy over baseline methods, with our approach outperforming the baseline model by 10% in 1-shot and around 5% in 5-shot approaches. Additionally, both visual-only and visual + textual generators have also been tested in this paper.
LiverUSRecon: Automatic 3D Reconstruction and Volumetry of the Liver with a Few Partial Ultrasound Scans
Jun 27, 20243D reconstruction of the liver for volumetry is important for qualitative analysis and disease diagnosis. Liver volumetry using ultrasound (US) scans, although advantageous due to less acquisition time and safety, is challenging due to the inherent noisiness in US scans, blurry boundaries, and partial liver visibility. We address these challenges by using the segmentation masks of a few incomplete sagittal-plane US scans of the liver in conjunction with a statistical shape model (SSM) built using a set of CT scans of the liver. We compute the shape parameters needed to warp this canonical SSM to fit the US scans through a parametric regression network. The resulting 3D liver reconstruction is accurate and leads to automatic liver volume calculation. We evaluate the accuracy of the estimated liver volumes with respect to CT segmentation volumes using RMSE. Our volume computation is statistically much closer to the volume estimated using CT scans than the volume computed using Childs' method by radiologists: p-value of 0.094 (>0.05) says that there is no significant difference between CT segmentation volumes and ours in contrast to Childs' method. We validate our method using investigations (ablation studies) on the US image resolution, the number of CT scans used for SSM, the number of principal components, and the number of input US scans. To the best of our knowledge, this is the first automatic liver volumetry system using a few incomplete US scans given a set of CT scans of livers for SSM.