 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models for Brain Signals: A Critical Review of Current Progress and Future Directions
Jul 15, 2025Patterns of electrical brain activity recorded via electroencephalography (EEG) offer immense value for scientific and clinical investigations. The inability of supervised EEG encoders to learn robust EEG patterns and their over-reliance on expensive signal annotations have sparked a transition towards general-purpose self-supervised EEG encoders, i.e., EEG foundation models (EEG-FMs), for robust and scalable EEG feature extraction. However, the real-world readiness of early EEG-FMs and the rubric for long-term research progress remain unclear. A systematic and comprehensive review of first-generation EEG-FMs is therefore necessary to understand the current state-of-the-art and identify key directions for future EEG-FMs. To that end, this study reviews 10 early EEG-FMs and presents a critical synthesis of their methodology, empirical findings, and outstanding research gaps. We find that most EEG-FMs adopt a sequence-based modeling scheme that relies on transformer-based backbones and the reconstruction of masked sequences for self-supervision. However, model evaluations remain heterogeneous and largely limited, making it challenging to assess their practical off-the-shelf utility. In addition to adopting standardized and realistic evaluations, future work should demonstrate more substantial scaling effects and make principled and trustworthy choices throughout the EEG representation learning pipeline. We believe that developing benchmarks, software tools, technical methodologies, and applications in collaboration with domain experts may further advance the translational utility and real-world adoption of EEG-FMs.
Generalizing to Unseen Domains in Diabetic Retinopathy Classification
Oct 27, 2023



Diabetic retinopathy (DR) is caused by long-standing diabetes and is among the fifth leading cause for visual impairments. The process of early diagnosis and treatments could be helpful in curing the disease, however, the detection procedure is rather challenging and mostly tedious. Therefore, automated diabetic retinopathy classification using deep learning techniques has gained interest in the medical imaging community. Akin to several other real-world applications of deep learning, the typical assumption of i.i.d data is also violated in DR classification that relies on deep learning. Therefore, developing DR classification methods robust to unseen distributions is of great value. In this paper, we study the problem of generalizing a model to unseen distributions or domains (a.k.a domain generalization) in DR classification. To this end, we propose a simple and effective domain generalization (DG) approach that achieves self-distillation in vision transformers (ViT) via a novel prediction softening mechanism. This prediction softening is an adaptive convex combination one-hot labels with the model's own knowledge. We perform extensive experiments on challenging open-source DR classification datasets under both multi-source and single-source DG settings with three different ViT backbones to establish the efficacy and applicability of our approach against competing methods. For the first time, we report the performance of several state-of-the-art DG methods on open-source DR classification datasets after conducting thorough experiments. Finally, our method is also capable of delivering improved calibration performance than other methods, showing its suitability for safety-critical applications, including healthcare. We hope that our contributions would investigate more DG research across the medical imaging community.
Realistic, Animatable Human Reconstructions for Virtual Fit-On
Oct 16, 2022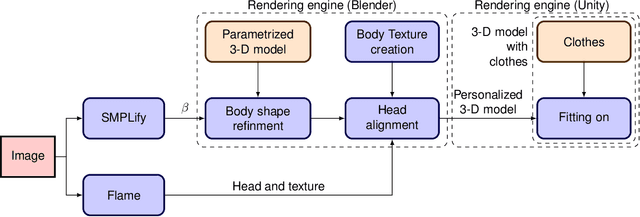
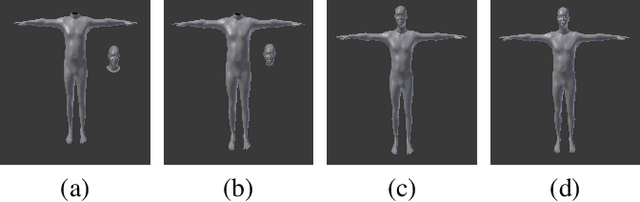
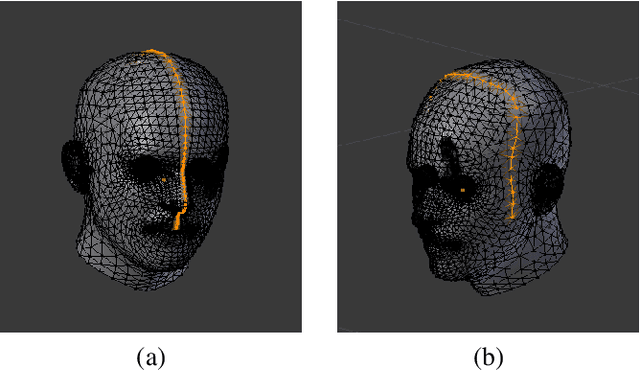

We present an end-to-end virtual try-on pipeline, that can fit different clothes on a personalized 3-D human model, reconstructed using a single RGB image. Our main idea is to construct an animatable 3-D human model and try-on different clothes in a 3-D virtual environment. The existing frame by frame volumetric reconstruction of 3-D human models are highly resource-demanding and do not allow clothes switching. Moreover, existing virtual fit-on systems also lack realism due to predominantly being 2-D or not using user's features in the reconstruction. These shortcomings are due to either the human body or clothing model being 2-D or not having the user's facial features in the dressed model. We solve these problems by manipulating a parametric representation of the 3-D human body model and stitching a head model reconstructed from the actual image. Fitting the 3-D clothing models on the parameterized human model is also adjustable to the body shape of the input image. Our reconstruction results, in comparison with recent existing work, are more visually-pleasing.