 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Photometric Uncertainty in Gaussian Splatting for Novel View Synthesis
Mar 24, 2026Recent advances in 3D Gaussian Splatting have enabled impressive photorealistic novel view synthesis. However, to transition from a pure rendering engine to a reliable spatial map for autonomous agents and safety-critical applications, knowing where the representation is uncertain is as important as the rendering fidelity itself. We bridge this critical gap by introducing a lightweight, plug-and-play framework for pixel-wise, view-dependent predictive uncertainty estimation. Our post-hoc method formulates uncertainty as a Bayesian-regularized linear least-squares optimization over reconstruction residuals. This architecture-agnostic approach extracts a per-primitive uncertainty channel without modifying the underlying scene representation or degrading baseline visual fidelity. Crucially, we demonstrate that providing this actionable reliability signal successfully translates 3D Gaussian splatting into a trustworthy spatial map, further improving state-of-the-art performance across three critical downstream perception tasks: active view selection, pose-agnostic scene change detection, and pose-agnostic anomaly detection.
Changes in Real Time: Online Scene Change Detection with Multi-View Fusion
Nov 15, 2025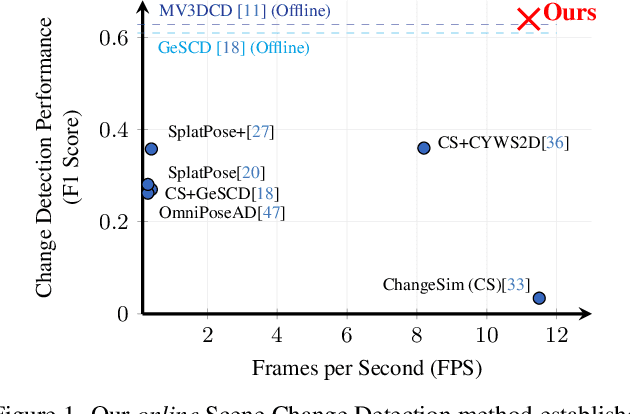
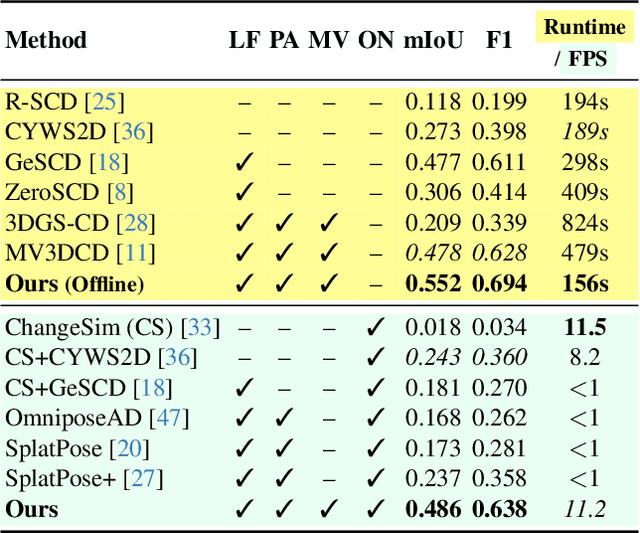

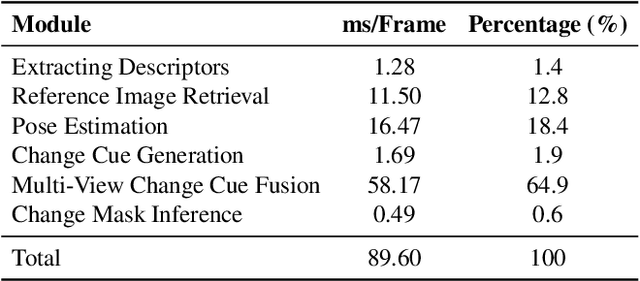
Online Scene Change Detection (SCD) is an extremely challenging problem that requires an agent to detect relevant changes on the fly while observing the scene from unconstrained viewpoints. Existing online SCD methods are significantly less accurate than offline approaches. We present the first online SCD approach that is pose-agnostic, label-free, and ensures multi-view consistency, while operating at over 10 FPS and achieving new state-of-the-art performance, surpassing even the best offline approaches. Our method introduces a new self-supervised fusion loss to infer scene changes from multiple cues and observations, PnP-based fast pose estimation against the reference scene, and a fast change-guided update strategy for the 3D Gaussian Splatting scene representation. Extensive experiments on complex real-world datasets demonstrate that our approach outperforms both online and offline baselines.
Uncertainty Awareness Enables Efficient Labeling for Cancer Subtyping in Digital Pathology
Jun 13, 2025



Machine-learning-assisted cancer subtyping is a promising avenue in digital pathology. Cancer subtyping models, however, require careful training using expert annotations so that they can be inferred with a degree of known certainty (or uncertainty). To this end, we introduce the concept of uncertainty awareness into a self-supervised contrastive learning model. This is achieved by computing an evidence vector at every epoch, which assesses the model's confidence in its predictions. The derived uncertainty score is then utilized as a metric to selectively label the most crucial images that require further annotation, thus iteratively refining the training process. With just 1-10% of strategically selected annotations, we attain state-of-the-art performance in cancer subtyping on benchmark datasets. Our method not only strategically guides the annotation process to minimize the need for extensive labeled datasets, but also improves the precision and efficiency of classifications. This development is particularly beneficial in settings where the availability of labeled data is limited, offering a promising direction for future research and application in digital pathology.
Feature Modulation for Semi-Supervised Domain Generalization without Domain Labels
Mar 26, 2025



Semi-supervised domain generalization (SSDG) leverages a small fraction of labeled data alongside unlabeled data to enhance model generalization. Most of the existing SSDG methods rely on pseudo-labeling (PL) for unlabeled data, often assuming access to domain labels-a privilege not always available. However, domain shifts introduce domain noise, leading to inconsistent PLs that degrade model performance. Methods derived from FixMatch suffer particularly from lower PL accuracy, reducing the effectiveness of unlabeled data. To address this, we tackle the more challenging domain-label agnostic SSDG, where domain labels for unlabeled data are not available during training. First, we propose a feature modulation strategy that enhances class-discriminative features while suppressing domain-specific information. This modulation shifts features toward Similar Average Representations-a modified version of class prototypes-that are robust across domains, encouraging the classifier to distinguish between closely related classes and feature extractor to form tightly clustered, domain-invariant representations. Second, to mitigate domain noise and improve pseudo-label accuracy, we introduce a loss-scaling function that dynamically lowers the fixed confidence threshold for pseudo-labels, optimizing the use of unlabeled data. With these key innovations, our approach achieves significant improvements on four major domain generalization benchmarks-even without domain labels. We will make the code available.
Multi-View Pose-Agnostic Change Localization with Zero Labels
Dec 05, 2024Autonomous agents often require accurate methods for detecting and localizing changes in their environment, particularly when observations are captured from unconstrained and inconsistent viewpoints. We propose a novel label-free, pose-agnostic change detection method that integrates information from multiple viewpoints to construct a change-aware 3D Gaussian Splatting (3DGS) representation of the scene. With as few as 5 images of the post-change scene, our approach can learn additional change channels in a 3DGS and produce change masks that outperform single-view techniques. Our change-aware 3D scene representation additionally enables the generation of accurate change masks for unseen viewpoints. Experimental results demonstrate state-of-the-art performance in complex multi-object scenes, achieving a 1.7$\times$ and 1.6$\times$ improvement in Mean Intersection Over Union and F1 score respectively over other baselines. We also contribute a new real-world dataset to benchmark change detection in diverse challenging scenes in the presence of lighting variations.
Towards Generalizing to Unseen Domains with Few Labels
Mar 19, 2024



We approach the challenge of addressing semi-supervised domain generalization (SSDG). Specifically, our aim is to obtain a model that learns domain-generalizable features by leveraging a limited subset of labelled data alongside a substantially larger pool of unlabeled data. Existing domain generalization (DG) methods which are unable to exploit unlabeled data perform poorly compared to semi-supervised learning (SSL) methods under SSDG setting. Nevertheless, SSL methods have considerable room for performance improvement when compared to fully-supervised DG training. To tackle this underexplored, yet highly practical problem of SSDG, we make the following core contributions. First, we propose a feature-based conformity technique that matches the posterior distributions from the feature space with the pseudo-label from the model's output space. Second, we develop a semantics alignment loss to learn semantically-compatible representations by regularizing the semantic structure in the feature space. Our method is plug-and-play and can be readily integrated with different SSL-based SSDG baselines without introducing any additional parameters. Extensive experimental results across five challenging DG benchmarks with four strong SSL baselines suggest that our method provides consistent and notable gains in two different SSDG settings.
Generalizing to Unseen Domains in Diabetic Retinopathy Classification
Oct 27, 2023



Diabetic retinopathy (DR) is caused by long-standing diabetes and is among the fifth leading cause for visual impairments. The process of early diagnosis and treatments could be helpful in curing the disease, however, the detection procedure is rather challenging and mostly tedious. Therefore, automated diabetic retinopathy classification using deep learning techniques has gained interest in the medical imaging community. Akin to several other real-world applications of deep learning, the typical assumption of i.i.d data is also violated in DR classification that relies on deep learning. Therefore, developing DR classification methods robust to unseen distributions is of great value. In this paper, we study the problem of generalizing a model to unseen distributions or domains (a.k.a domain generalization) in DR classification. To this end, we propose a simple and effective domain generalization (DG) approach that achieves self-distillation in vision transformers (ViT) via a novel prediction softening mechanism. This prediction softening is an adaptive convex combination one-hot labels with the model's own knowledge. We perform extensive experiments on challenging open-source DR classification datasets under both multi-source and single-source DG settings with three different ViT backbones to establish the efficacy and applicability of our approach against competing methods. For the first time, we report the performance of several state-of-the-art DG methods on open-source DR classification datasets after conducting thorough experiments. Finally, our method is also capable of delivering improved calibration performance than other methods, showing its suitability for safety-critical applications, including healthcare. We hope that our contributions would investigate more DG research across the medical imaging community.