 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Modulation for Semi-Supervised Domain Generalization without Domain Labels
Mar 26, 2025



Semi-supervised domain generalization (SSDG) leverages a small fraction of labeled data alongside unlabeled data to enhance model generalization. Most of the existing SSDG methods rely on pseudo-labeling (PL) for unlabeled data, often assuming access to domain labels-a privilege not always available. However, domain shifts introduce domain noise, leading to inconsistent PLs that degrade model performance. Methods derived from FixMatch suffer particularly from lower PL accuracy, reducing the effectiveness of unlabeled data. To address this, we tackle the more challenging domain-label agnostic SSDG, where domain labels for unlabeled data are not available during training. First, we propose a feature modulation strategy that enhances class-discriminative features while suppressing domain-specific information. This modulation shifts features toward Similar Average Representations-a modified version of class prototypes-that are robust across domains, encouraging the classifier to distinguish between closely related classes and feature extractor to form tightly clustered, domain-invariant representations. Second, to mitigate domain noise and improve pseudo-label accuracy, we introduce a loss-scaling function that dynamically lowers the fixed confidence threshold for pseudo-labels, optimizing the use of unlabeled data. With these key innovations, our approach achieves significant improvements on four major domain generalization benchmarks-even without domain labels. We will make the code available.
Video Summarisation with Incident and Context Information using Generative AI
Jan 08, 2025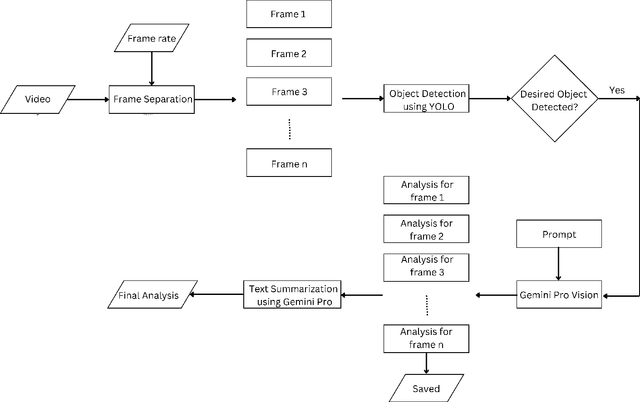

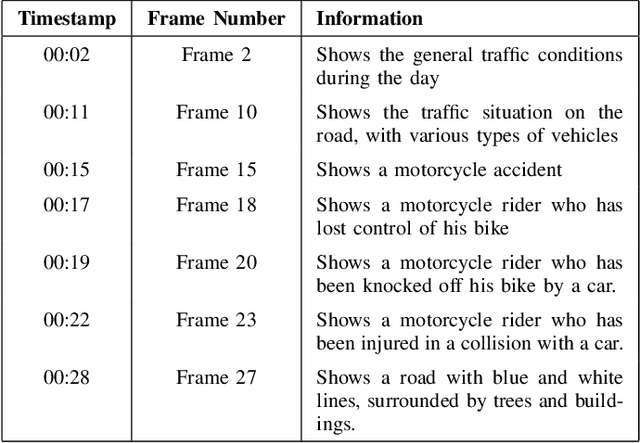

The proliferation of video content production has led to vast amounts of data, posing substantial challenges in terms of analysis efficiency and resource utilization. Addressing this issue calls for the development of robust video analysis tools. This paper proposes a novel approach leveraging Generative Artificial Intelligence (GenAI) to facilitate streamlined video analysis. Our tool aims to deliver tailored textual summaries of user-defined queries, offering a focused insight amidst extensive video datasets. Unlike conventional frameworks that offer generic summaries or limited action recognition, our method harnesses the power of GenAI to distil relevant information, enhancing analysis precision and efficiency. Employing YOLO-V8 for object detection and Gemini for comprehensive video and text analysis, our solution achieves heightened contextual accuracy. By combining YOLO with Gemini, our approach furnishes textual summaries extracted from extensive CCTV footage, enabling users to swiftly navigate and verify pertinent events without the need for exhaustive manual review. The quantitative evaluation revealed a similarity of 72.8%, while the qualitative assessment rated an accuracy of 85%, demonstrating the capability of the proposed method.