 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Summarisation with Incident and Context Information using Generative AI
Jan 08, 2025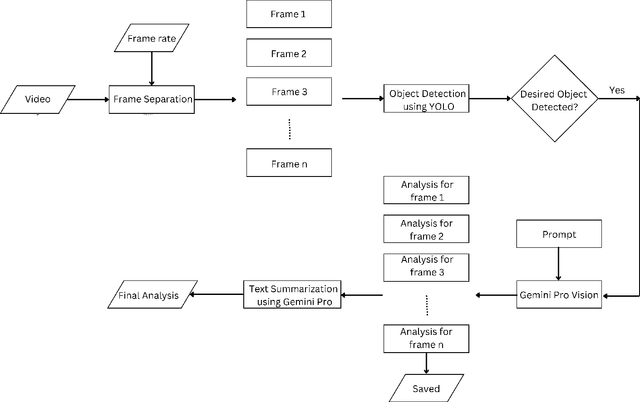

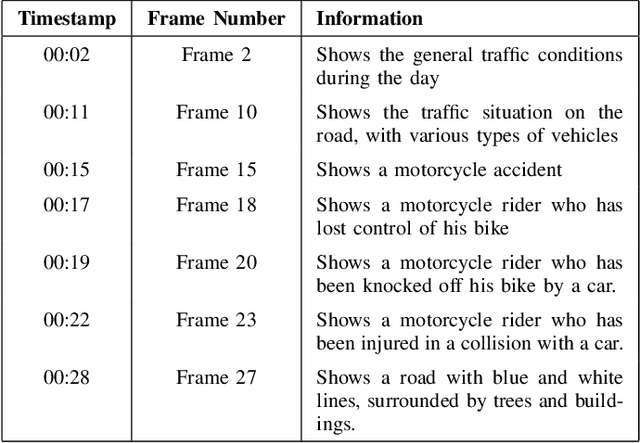

The proliferation of video content production has led to vast amounts of data, posing substantial challenges in terms of analysis efficiency and resource utilization. Addressing this issue calls for the development of robust video analysis tools. This paper proposes a novel approach leveraging Generative Artificial Intelligence (GenAI) to facilitate streamlined video analysis. Our tool aims to deliver tailored textual summaries of user-defined queries, offering a focused insight amidst extensive video datasets. Unlike conventional frameworks that offer generic summaries or limited action recognition, our method harnesses the power of GenAI to distil relevant information, enhancing analysis precision and efficiency. Employing YOLO-V8 for object detection and Gemini for comprehensive video and text analysis, our solution achieves heightened contextual accuracy. By combining YOLO with Gemini, our approach furnishes textual summaries extracted from extensive CCTV footage, enabling users to swiftly navigate and verify pertinent events without the need for exhaustive manual review. The quantitative evaluation revealed a similarity of 72.8%, while the qualitative assessment rated an accuracy of 85%, demonstrating the capability of the proposed method.
Large Language Models for Video Surveillance Applications
Jan 06, 2025


The rapid increase in video content production has resulted in enormous data volumes, creating significant challenges for efficient analysis and resource management. To address this, robust video analysis tools are essential. This paper presents an innovative proof of concept using Generative Artificial Intelligence (GenAI) in the form of Vision Language Models to enhance the downstream video analysis process. Our tool generates customized textual summaries based on user-defined queries, providing focused insights within extensive video datasets. Unlike traditional methods that offer generic summaries or limited action recognition, our approach utilizes Vision Language Models to extract relevant information, improving analysis precision and efficiency. The proposed method produces textual summaries from extensive CCTV footage, which can then be stored for an indefinite time in a very small storage space compared to videos, allowing users to quickly navigate and verify significant events without exhaustive manual review. Qualitative evaluations result in 80% and 70% accuracy in temporal and spatial quality and consistency of the pipeline respectively.
A Scalable Decentralized Reinforcement Learning Framework for UAV Target Localization Using Recurrent PPO
Dec 09, 2024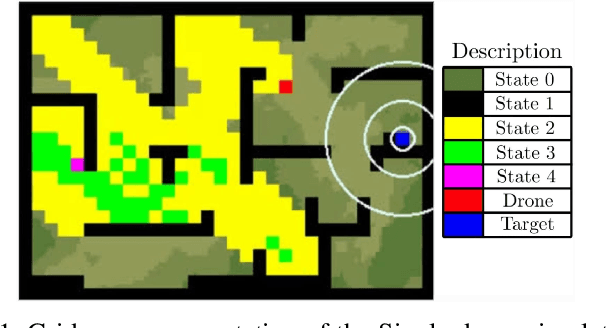
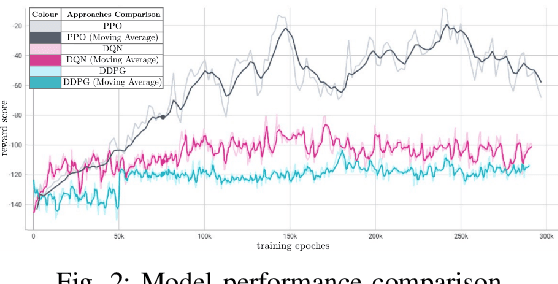
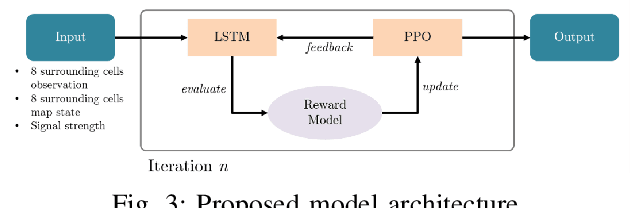
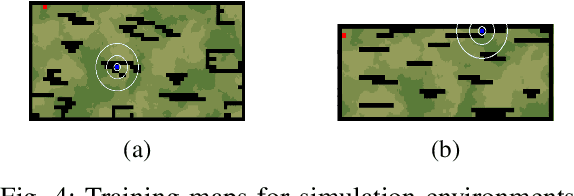
The rapid advancements in unmanned aerial vehicles (UAVs) have unlocked numerous applications, including environmental monitoring, disaster response, and agricultural surveying. Enhancing the collective behavior of multiple decentralized UAVs can significantly improve these applications through more efficient and coordinated operations. In this study, we explore a Recurrent PPO model for target localization in perceptually degraded environments like places without GNSS/GPS signals. We first developed a single-drone approach for target identification, followed by a decentralized two-drone model. Our approach can utilize two types of sensors on the UAVs, a detection sensor and a target signal sensor. The single-drone model achieved an accuracy of 93%, while the two-drone model achieved an accuracy of 86%, with the latter requiring fewer average steps to locate the target. This demonstrates the potential of our method in UAV swarms, offering efficient and effective localization of radiant targets in complex environmental conditions.