 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Video Surveillance Applications
Jan 06, 2025


The rapid increase in video content production has resulted in enormous data volumes, creating significant challenges for efficient analysis and resource management. To address this, robust video analysis tools are essential. This paper presents an innovative proof of concept using Generative Artificial Intelligence (GenAI) in the form of Vision Language Models to enhance the downstream video analysis process. Our tool generates customized textual summaries based on user-defined queries, providing focused insights within extensive video datasets. Unlike traditional methods that offer generic summaries or limited action recognition, our approach utilizes Vision Language Models to extract relevant information, improving analysis precision and efficiency. The proposed method produces textual summaries from extensive CCTV footage, which can then be stored for an indefinite time in a very small storage space compared to videos, allowing users to quickly navigate and verify significant events without exhaustive manual review. Qualitative evaluations result in 80% and 70% accuracy in temporal and spatial quality and consistency of the pipeline respectively.
A Slow-Shifting Concerned Machine Learning Method for Short-term Traffic Flow Forecasting
Mar 31, 2023



The ability to predict traffic flow over time for crowded areas during rush hours is increasingly important as it can help authorities make informed decisions for congestion mitigation or scheduling of infrastructure development in an area. However, a crucial challenge in traffic flow forecasting is the slow shifting in temporal peaks between daily and weekly cycles, resulting in the nonstationarity of the traffic flow signal and leading to difficulty in accurate forecasting. To address this challenge, we propose a slow shifting concerned machine learning method for traffic flow forecasting, which includes two parts. First, we take advantage of Empirical Mode Decomposition as the feature engineering to alleviate the nonstationarity of traffic flow data, yielding a series of stationary components. Second, due to the superiority of Long-Short-Term-Memory networks in capturing temporal features, an advanced traffic flow forecasting model is developed by taking the stationary components as inputs. Finally, we apply this method on a benchmark of real-world data and provide a comparison with other existing methods. Our proposed method outperforms the state-of-art results by 14.55% and 62.56% using the metrics of root mean squared error and mean absolute percentage error, respectively.
Clustering and Analysis of GPS Trajectory Data using Distance-based Features
Dec 01, 2022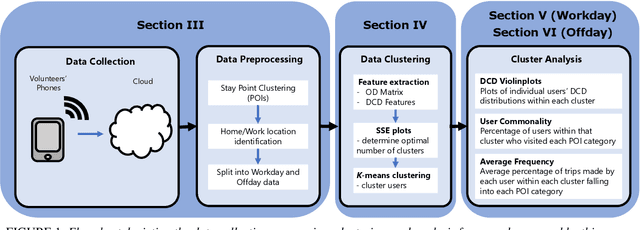
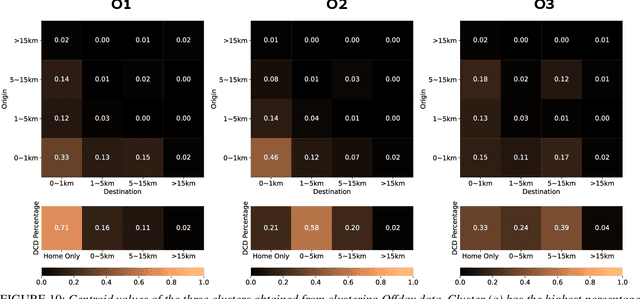
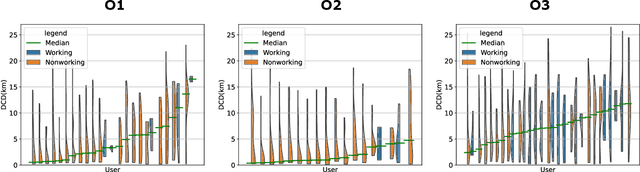
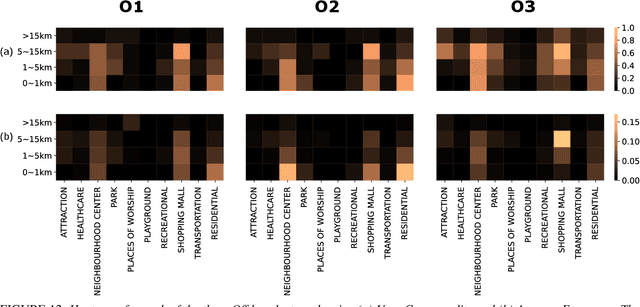
The proliferation of smartphones has accelerated mobility studies by largely increasing the type and volume of mobility data available. One such source of mobility data is from GPS technology, which is becoming increasingly common and helps the research community understand mobility patterns of people. However, there lacks a standardized framework for studying the different mobility patterns created by the non-Work, non-Home locations of Working and Nonworking users on Workdays and Offdays using machine learning methods. We propose a new mobility metric, Daily Characteristic Distance, and use it to generate features for each user together with Origin-Destination matrix features. We then use those features with an unsupervised machine learning method, $k$-means clustering, and obtain three clusters of users for each type of day (Workday and Offday). Finally, we propose two new metrics for the analysis of the clustering results, namely User Commonality and Average Frequency. By using the proposed metrics, interesting user behaviors can be discerned and it helps us to better understand the mobility patterns of the users.
Multiple-Perspective Clustering of Passive Wi-Fi Sensing Trajectory Data
Dec 22, 2020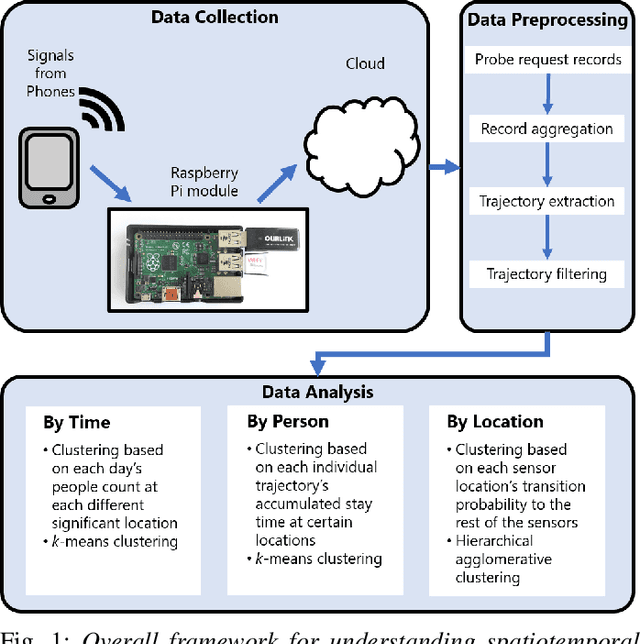
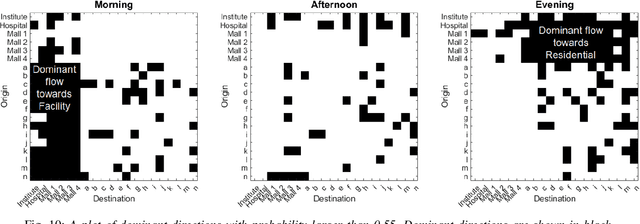
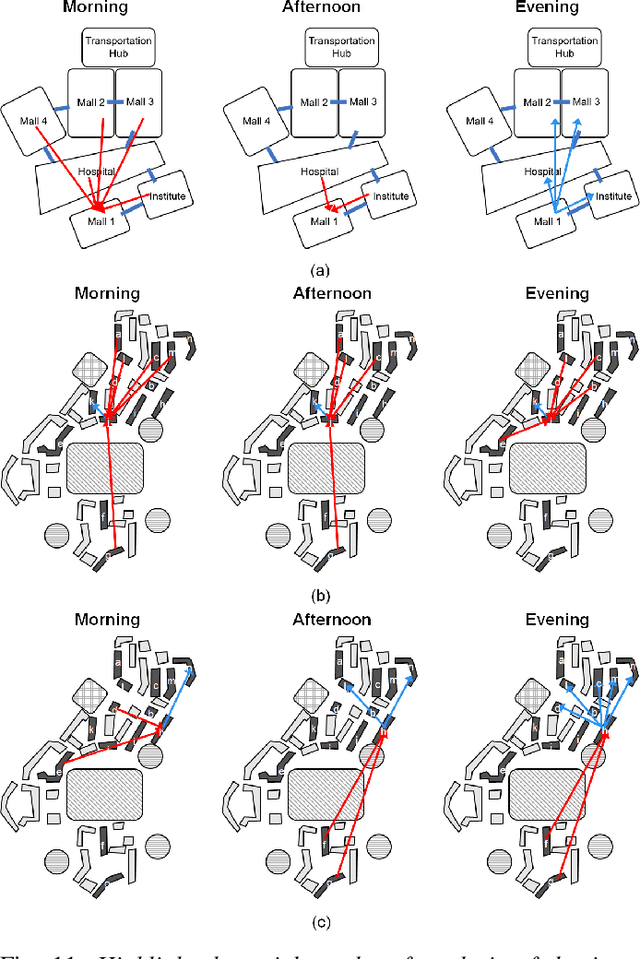
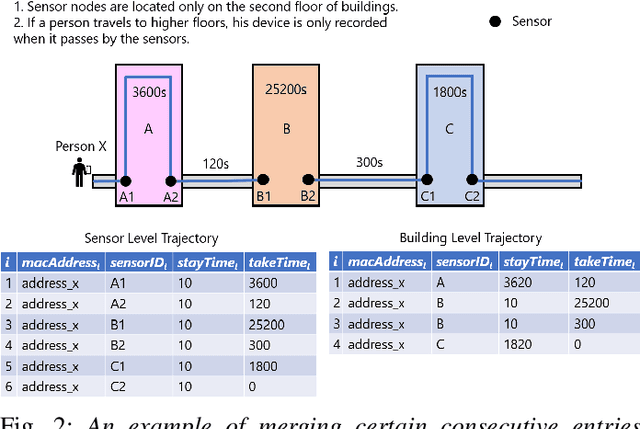
Information about the spatiotemporal flow of humans within an urban context has a wide plethora of applications. Currently, although there are many different approaches to collect such data, there lacks a standardized framework to analyze it. The focus of this paper is on the analysis of the data collected through passive Wi-Fi sensing, as such passively collected data can have a wide coverage at low cost. We propose a systematic approach by using unsupervised machine learning methods, namely k-means clustering and hierarchical agglomerative clustering (HAC) to analyze data collected through such a passive Wi-Fi sniffing method. We examine three aspects of clustering of the data, namely by time, by person, and by location, and we present the results obtained by applying our proposed approach on a real-world dataset collected over five months.
Understanding Crowd Behaviors in a Social Event by Passive WiFi Sensing and Data Mining
Feb 05, 2020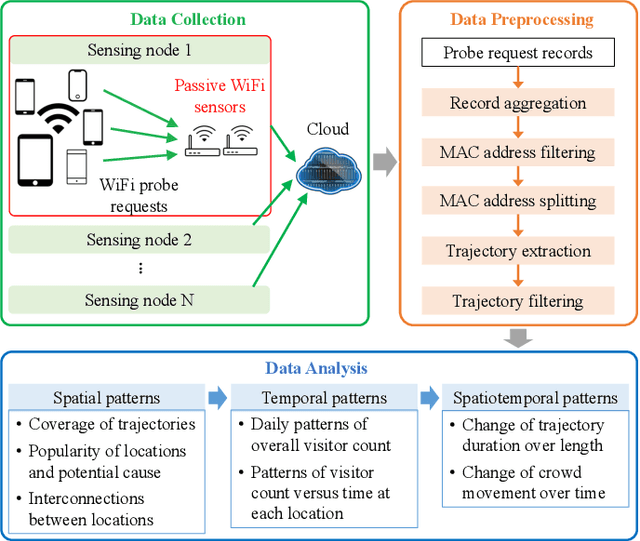
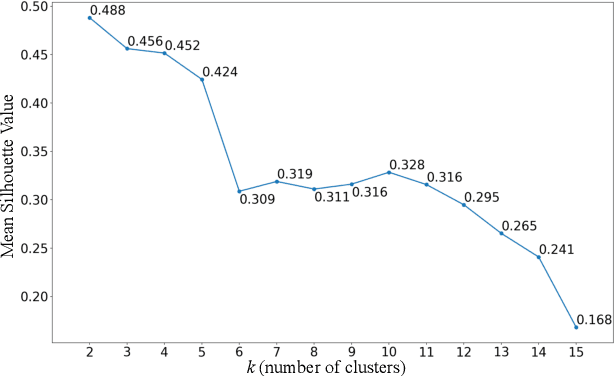
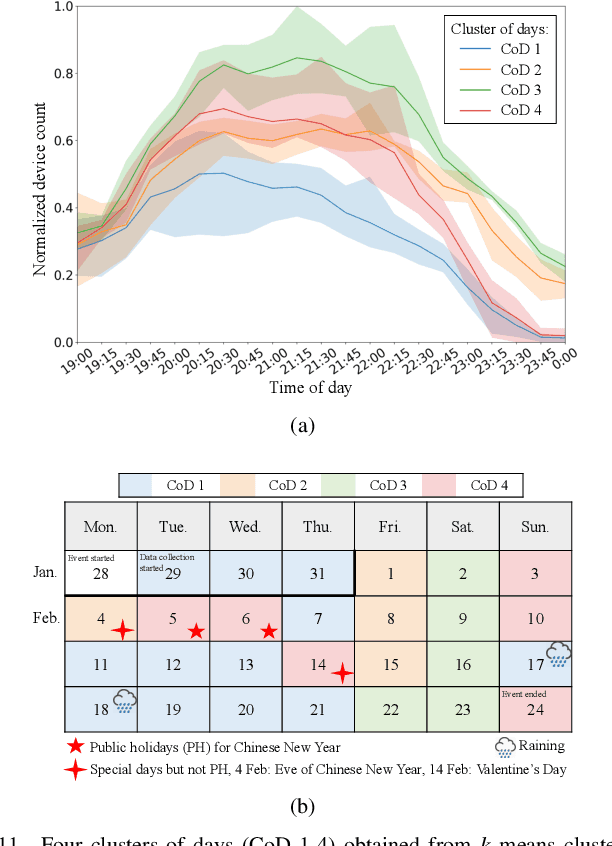
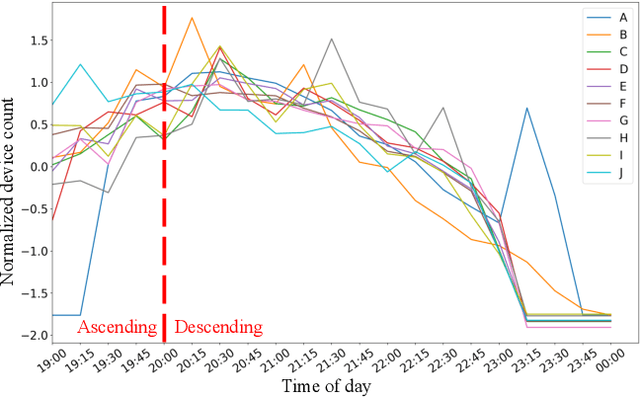
Understanding crowd behaviors in a large social event is crucial for event management. Passive WiFi sensing, by collecting WiFi probe requests sent from mobile devices, provides a better way to monitor crowds compared with people counters and cameras in terms of free interference, larger coverage, lower cost, and more information on people's movement. In existing studies, however, not enough attention has been paid to the thorough analysis and mining of collected data. Especially, the power of machine learning has not been fully exploited. In this paper, therefore, we propose a comprehensive data analysis framework to fully analyze the collected probe requests to extract three types of patterns related to crowd behaviors in a large social event, with the help of statistics, visualization, and unsupervised machine learning. First, trajectories of the mobile devices are extracted from probe requests and analyzed to reveal the spatial patterns of the crowds' movement. Hierarchical agglomerative clustering is adopted to find the interconnections between different locations. Next, k-means and k-shape clustering algorithms are applied to extract temporal visiting patterns of the crowds by days and locations, respectively. Finally, by combining with time, trajectories are transformed into spatiotemporal patterns, which reveal how trajectory duration changes over the length and how the overall trends of crowd movement change over time. The proposed data analysis framework is fully demonstrated using real-world data collected in a large social event. Results show that one can extract comprehensive patterns from data collected by a network of passive WiFi sensors.