 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrift Analysis with Fitness Levels for Elitist Evolutionary Algorithms
Sep 02, 2023



The fitness level method is a popular tool for analyzing the computation time of elitist evolutionary algorithms. Its idea is to divide the search space into multiple fitness levels and estimate lower and upper bounds on the computation time using transition probabilities between fitness levels. However, the lower bound generated from this method is often not tight. To improve the lower bound, this paper rigorously studies an open question about the fitness level method: what are the tightest lower and upper time bounds that can be constructed based on fitness levels? To answer this question, drift analysis with fitness levels is developed, and the tightest bound problem is formulated as a constrained multi-objective optimization problem subject to fitness level constraints. The tightest metric bounds from fitness levels are constructed and proven for the first time. Then the metric bounds are converted into linear bounds, where existing linear bounds are special cases. This paper establishes a general framework that can cover various linear bounds from trivial to best coefficients. It is generic and promising, as it can be used not only to draw the same bounds as existing ones, but also to draw tighter bounds, especially on fitness landscapes where shortcuts exist. This is demonstrated in the case study of the (1+1) EA maximizing the TwoPath function.
DsMtGCN: A Direction-sensitive Multi-task framework for Knowledge Graph Completion
Jun 17, 2023To solve the inherent incompleteness of knowledge graphs (KGs), numbers of knowledge graph completion (KGC) models have been proposed to predict missing links from known triples. Among those, several works have achieved more advanced results via exploiting the structure information on KGs with Graph Convolutional Networks (GCN). However, we observe that entity embeddings aggregated from neighbors in different directions are just simply averaged to complete single-tasks by existing GCN based models, ignoring the specific requirements of forward and backward sub-tasks. In this paper, we propose a Direction-sensitive Multi-task GCN (DsMtGCN) to make full use of the direction information, the multi-head self-attention is applied to specifically combine embeddings in different directions based on various entities and sub-tasks, the geometric constraints are imposed to adjust the distribution of embeddings, and the traditional binary cross-entropy loss is modified to reflect the triple uncertainty. Moreover, the competitive experiments results on several benchmark datasets verify the effectiveness of our model.
Contextual Dictionary Lookup for Knowledge Graph Completion
Jun 13, 2023Knowledge graph completion (KGC) aims to solve the incompleteness of knowledge graphs (KGs) by predicting missing links from known triples, numbers of knowledge graph embedding (KGE) models have been proposed to perform KGC by learning embeddings. Nevertheless, most existing embedding models map each relation into a unique vector, overlooking the specific fine-grained semantics of them under different entities. Additionally, the few available fine-grained semantic models rely on clustering algorithms, resulting in limited performance and applicability due to the cumbersome two-stage training process. In this paper, we present a novel method utilizing contextual dictionary lookup, enabling conventional embedding models to learn fine-grained semantics of relations in an end-to-end manner. More specifically, we represent each relation using a dictionary that contains multiple latent semantics. The composition of a given entity and the dictionary's central semantics serves as the context for generating a lookup, thus determining the fine-grained semantics of the relation adaptively. The proposed loss function optimizes both the central and fine-grained semantics simultaneously to ensure their semantic consistency. Besides, we introduce two metrics to assess the validity and accuracy of the dictionary lookup operation. We extend several KGE models with the method, resulting in substantial performance improvements on widely-used benchmark datasets.
Clustering and Analysis of GPS Trajectory Data using Distance-based Features
Dec 01, 2022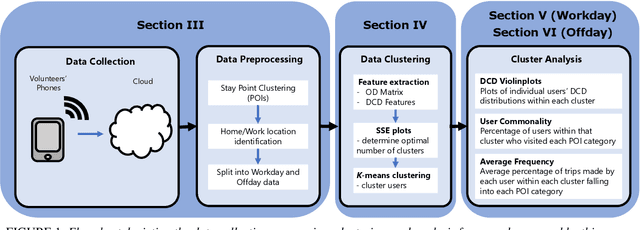
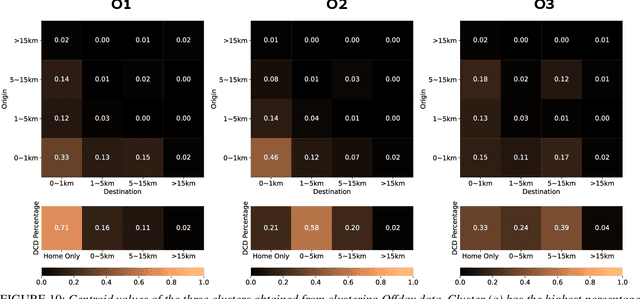
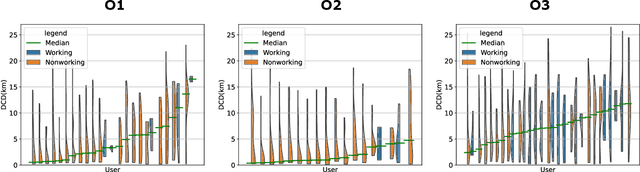
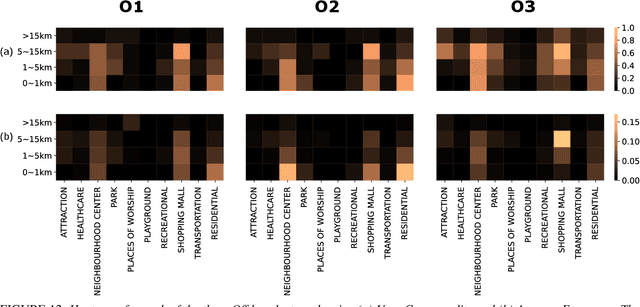
The proliferation of smartphones has accelerated mobility studies by largely increasing the type and volume of mobility data available. One such source of mobility data is from GPS technology, which is becoming increasingly common and helps the research community understand mobility patterns of people. However, there lacks a standardized framework for studying the different mobility patterns created by the non-Work, non-Home locations of Working and Nonworking users on Workdays and Offdays using machine learning methods. We propose a new mobility metric, Daily Characteristic Distance, and use it to generate features for each user together with Origin-Destination matrix features. We then use those features with an unsupervised machine learning method, $k$-means clustering, and obtain three clusters of users for each type of day (Workday and Offday). Finally, we propose two new metrics for the analysis of the clustering results, namely User Commonality and Average Frequency. By using the proposed metrics, interesting user behaviors can be discerned and it helps us to better understand the mobility patterns of the users.
Distributed Evolution Strategies for Black-box Stochastic Optimization
Apr 09, 2022
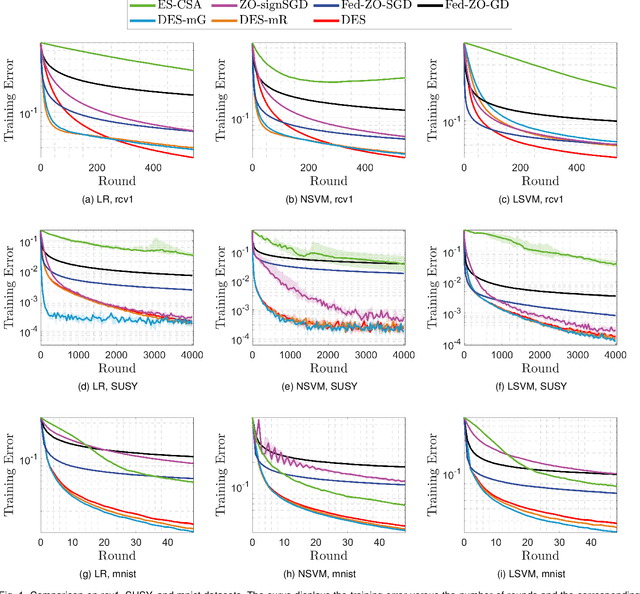
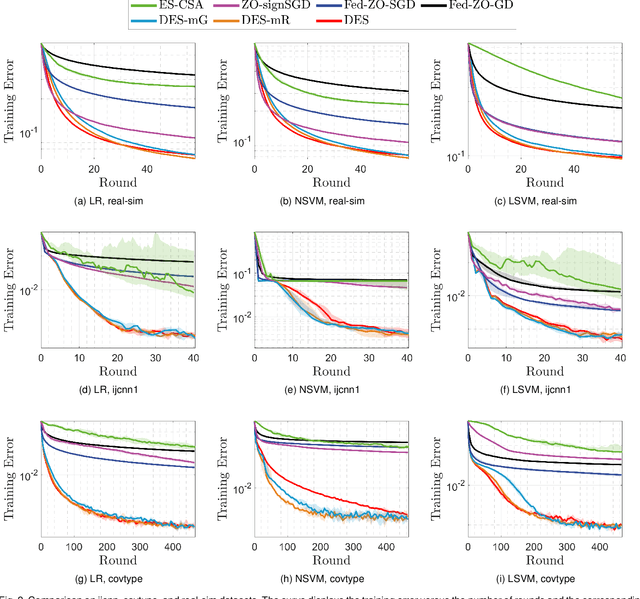
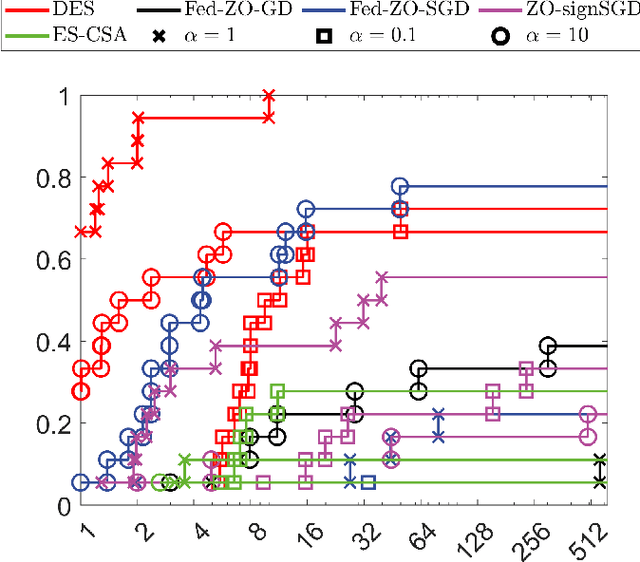
This work concerns the evolutionary approaches to distributed stochastic black-box optimization, in which each worker can individually solve an approximation of the problem with nature-inspired algorithms. We propose a distributed evolution strategy (DES) algorithm grounded on a proper modification to evolution strategies, a family of classic evolutionary algorithms, as well as a careful combination with existing distributed frameworks. On smooth and nonconvex landscapes, DES has a convergence rate competitive to existing zeroth-order methods, and can exploit the sparsity, if applicable, to match the rate of first-order methods. The DES method uses a Gaussian probability model to guide the search and avoids the numerical issue resulted from finite-difference techniques in existing zeroth-order methods. The DES method is also fully adaptive to the problem landscape, as its convergence is guaranteed with any parameter setting. We further propose two alternative sampling schemes which significantly improve the sampling efficiency while leading to similar performance. Simulation studies on several machine learning problems suggest that the proposed methods show much promise in reducing the convergence time and improving the robustness to parameter settings.
MMES: Mixture Model based Evolution Strategy for Large-Scale Optimization
Mar 15, 2022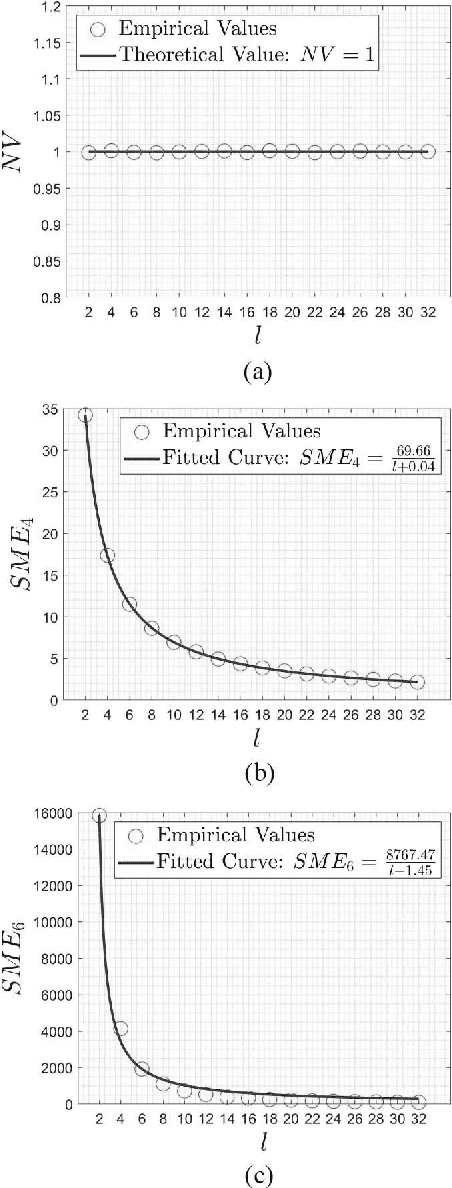
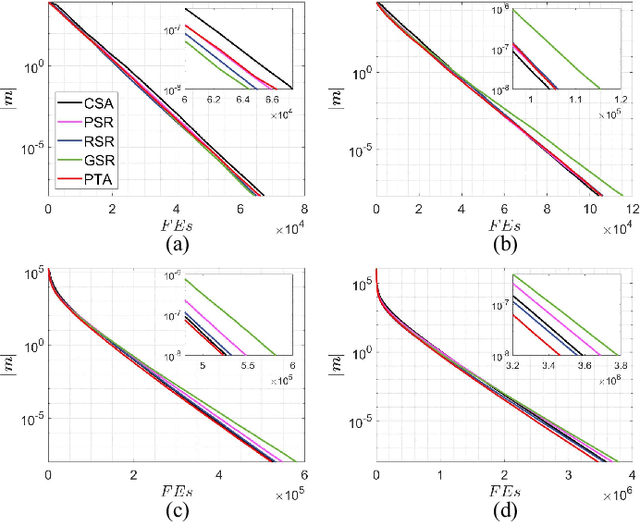
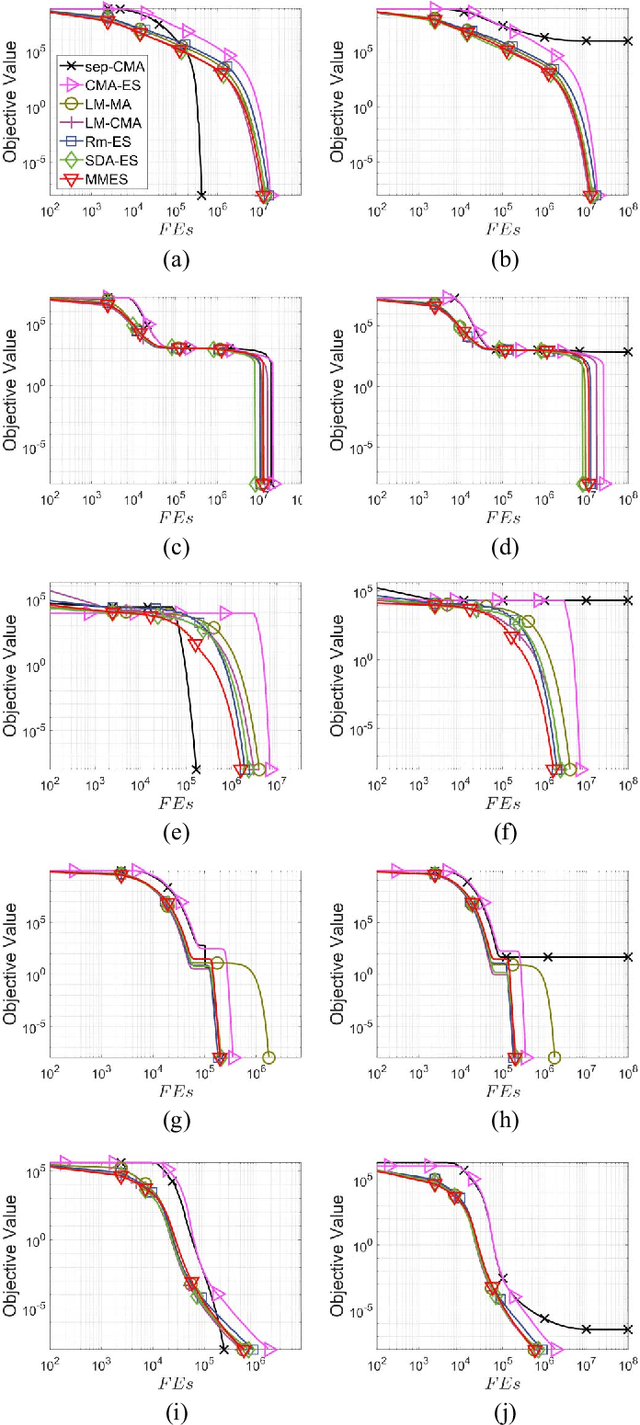
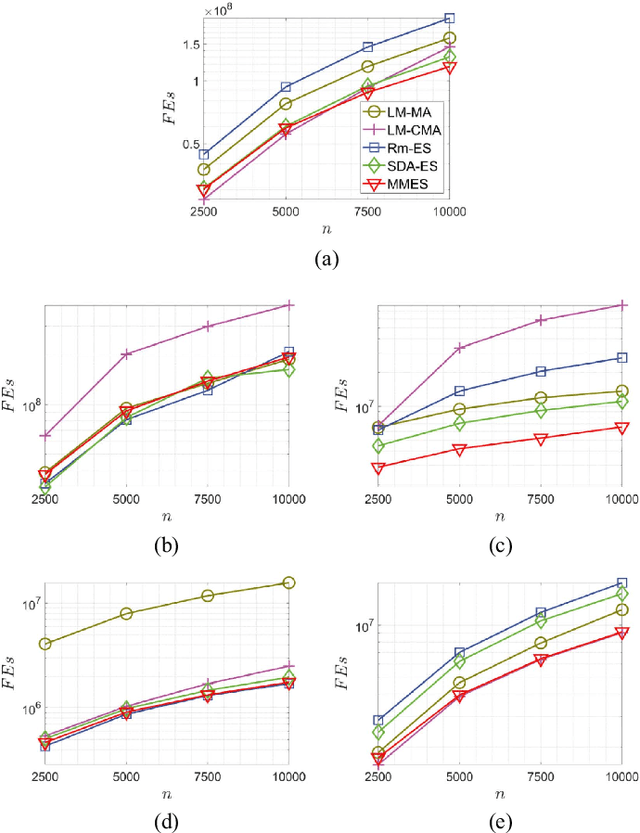
This work provides an efficient sampling method for the covariance matrix adaptation evolution strategy (CMA-ES) in large-scale settings. In contract to the Gaussian sampling in CMA-ES, the proposed method generates mutation vectors from a mixture model, which facilitates exploiting the rich variable correlations of the problem landscape within a limited time budget. We analyze the probability distribution of this mixture model and show that it approximates the Gaussian distribution of CMA-ES with a controllable accuracy. We use this sampling method, coupled with a novel method for mutation strength adaptation, to formulate the mixture model based evolution strategy (MMES) -- a CMA-ES variant for large-scale optimization. The numerical simulations show that, while significantly reducing the time complexity of CMA-ES, MMES preserves the rotational invariance, is scalable to high dimensional problems, and is competitive against the state-of-the-arts in performing global optimization.
WiFi Fingerprint Clustering for Urban Mobility Analysis
May 04, 2021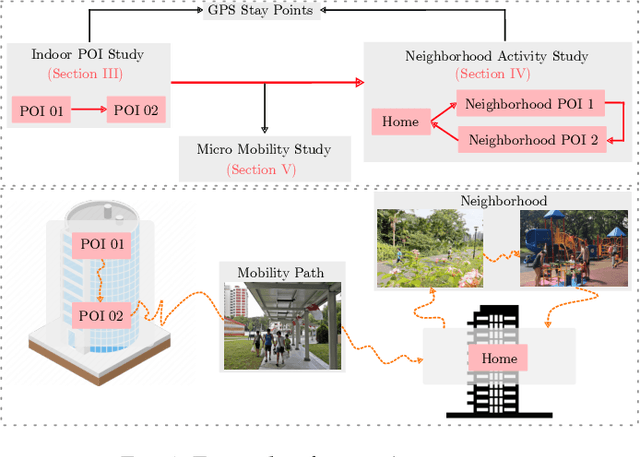
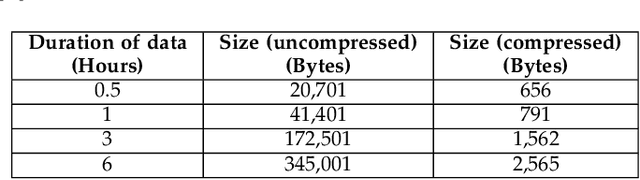
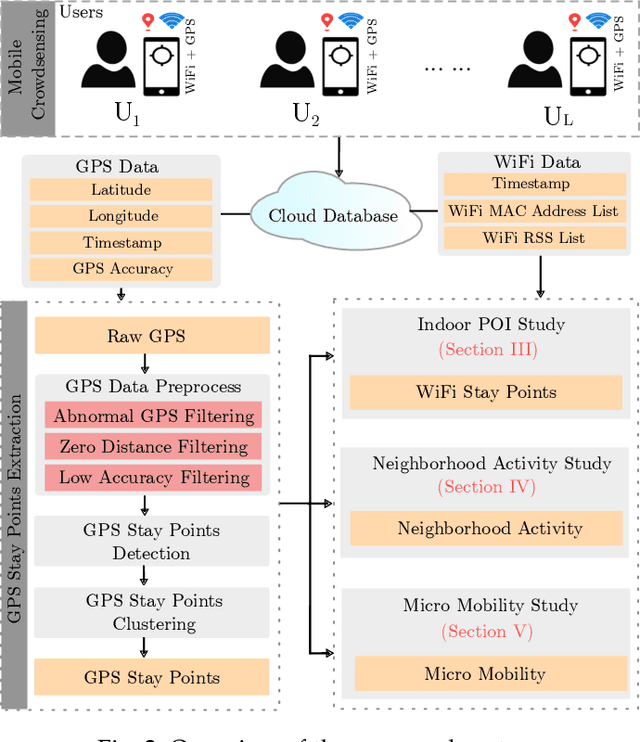

In this paper, we present an unsupervised learning approach to identify the user points of interest (POI) by exploiting WiFi measurements from smartphone application data. Due to the lack of GPS positioning accuracy in indoor, sheltered, and high rise building environments, we rely on widely available WiFi access points (AP) in contemporary urban areas to accurately identify POI and mobility patterns, by comparing the similarity in the WiFi measurements. We propose a system architecture to scan the surrounding WiFi AP, and perform unsupervised learning to demonstrate that it is possible to identify three major insights, namely the indoor POI within a building, neighbourhood activity, and micro-mobility of the users. Our results show that it is possible to identify the aforementioned insights, with the fusion of WiFi and GPS, which are not possible to identify by only using GPS.
There Once Was a Really Bad Poet, It Was Automated but You Didn't Know It
Mar 05, 2021
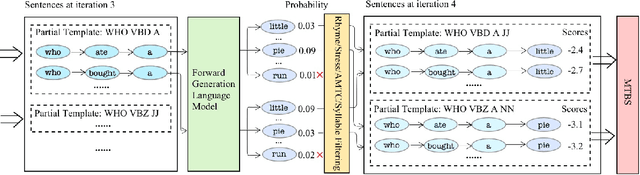
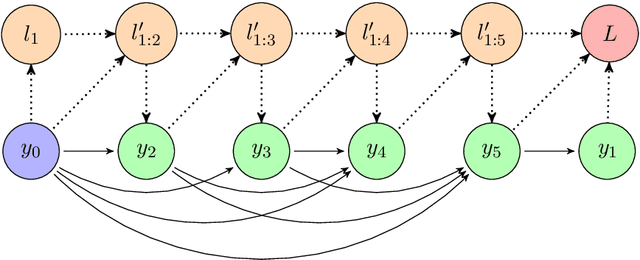

Limerick generation exemplifies some of the most difficult challenges faced in poetry generation, as the poems must tell a story in only five lines, with constraints on rhyme, stress, and meter. To address these challenges, we introduce LimGen, a novel and fully automated system for limerick generation that outperforms state-of-the-art neural network-based poetry models, as well as prior rule-based poetry models. LimGen consists of three important pieces: the Adaptive Multi-Templated Constraint algorithm that constrains our search to the space of realistic poems, the Multi-Templated Beam Search algorithm which searches efficiently through the space, and the probabilistic Storyline algorithm that provides coherent storylines related to a user-provided prompt word. The resulting limericks satisfy poetic constraints and have thematically coherent storylines, which are sometimes even funny (when we are lucky).
Multiple-Perspective Clustering of Passive Wi-Fi Sensing Trajectory Data
Dec 22, 2020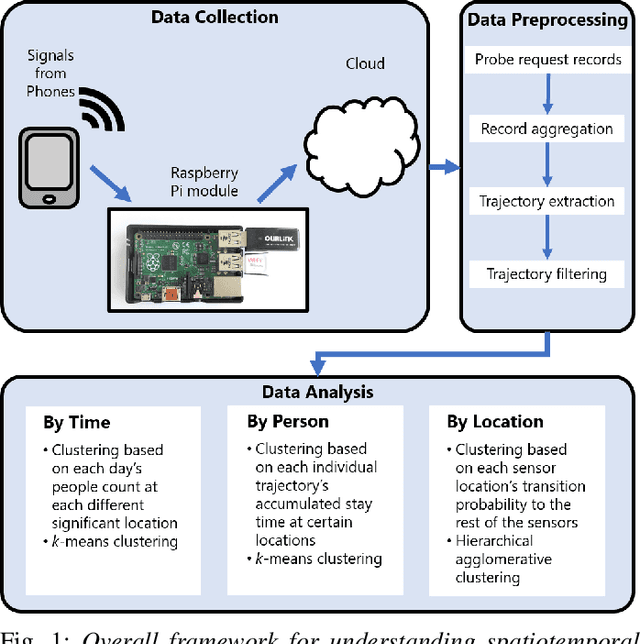
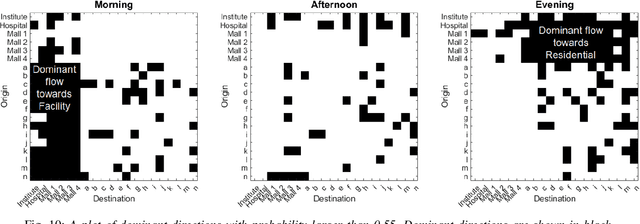
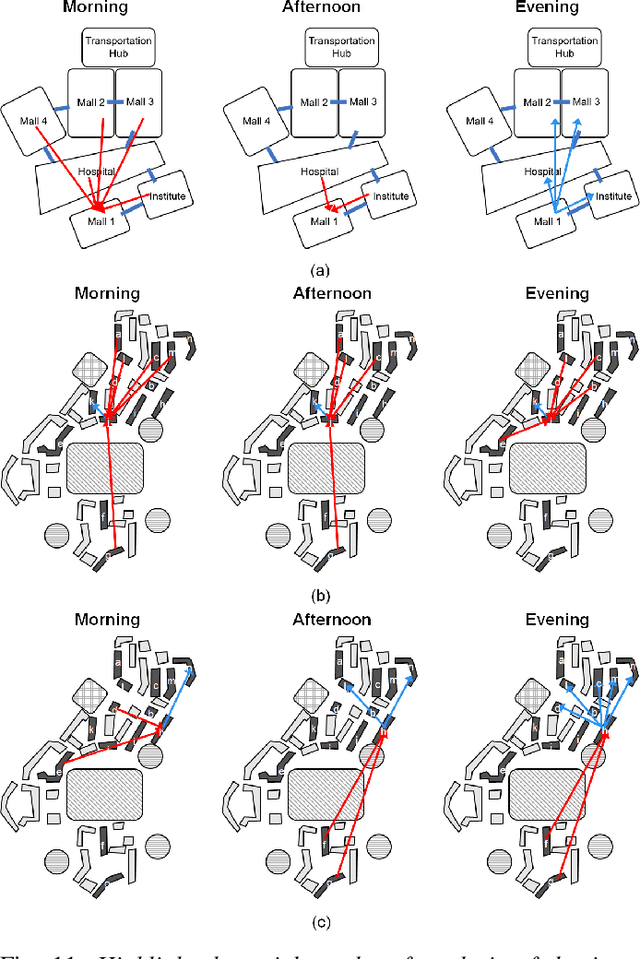
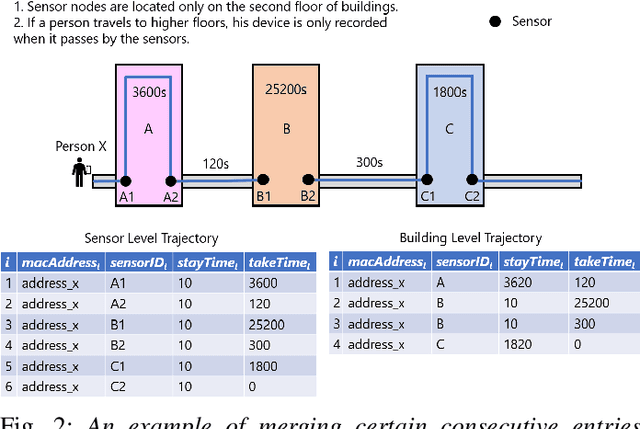
Information about the spatiotemporal flow of humans within an urban context has a wide plethora of applications. Currently, although there are many different approaches to collect such data, there lacks a standardized framework to analyze it. The focus of this paper is on the analysis of the data collected through passive Wi-Fi sensing, as such passively collected data can have a wide coverage at low cost. We propose a systematic approach by using unsupervised machine learning methods, namely k-means clustering and hierarchical agglomerative clustering (HAC) to analyze data collected through such a passive Wi-Fi sniffing method. We examine three aspects of clustering of the data, namely by time, by person, and by location, and we present the results obtained by applying our proposed approach on a real-world dataset collected over five months.
Stochastic Recursive Momentum for Policy Gradient Methods
Mar 09, 2020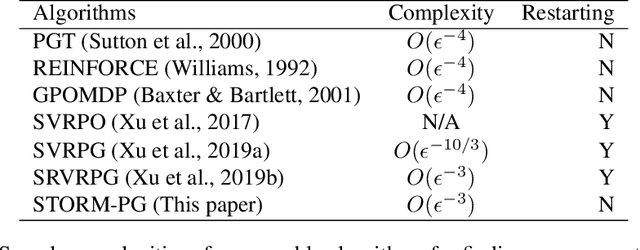
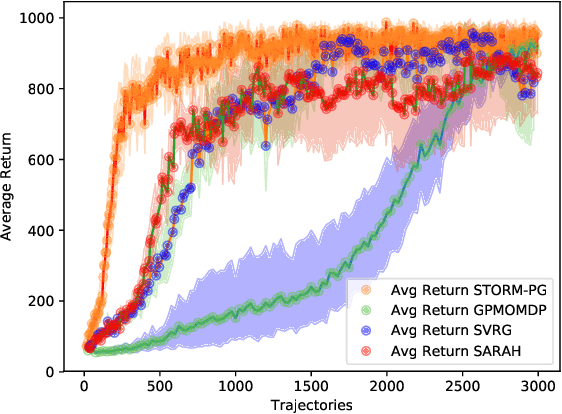
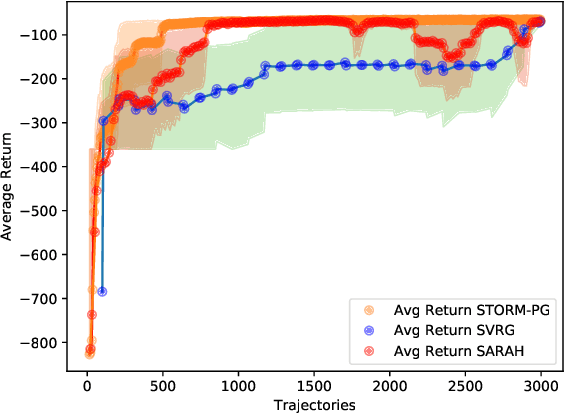
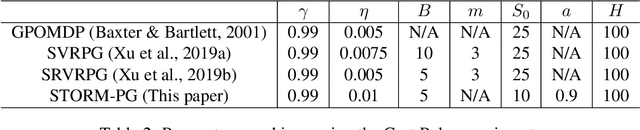
In this paper, we propose a novel algorithm named STOchastic Recursive Momentum for Policy Gradient (STORM-PG), which operates a SARAH-type stochastic recursive variance-reduced policy gradient in an exponential moving average fashion. STORM-PG enjoys a provably sharp $O(1/\epsilon^3)$ sample complexity bound for STORM-PG, matching the best-known convergence rate for policy gradient algorithm. In the mean time, STORM-PG avoids the alternations between large batches and small batches which persists in comparable variance-reduced policy gradient methods, allowing considerably simpler parameter tuning. Numerical experiments depicts the superiority of our algorithm over comparative policy gradient algorithms.