 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMSRARec: Summarization and Retrieval Augumented Sequential Recommendation Based on Multimodal Large Language Model
Dec 24, 2025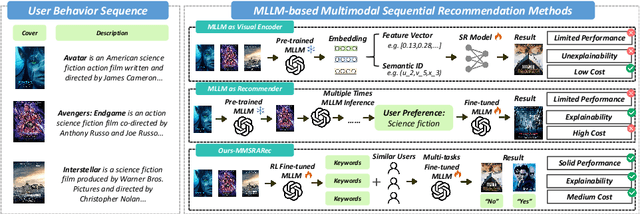



Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated significant potential in recommendation systems. However, the effective application of MLLMs to multimodal sequential recommendation remains unexplored: A) Existing methods primarily leverage the multimodal semantic understanding capabilities of pre-trained MLLMs to generate item embeddings or semantic IDs, thereby enhancing traditional recommendation models. These approaches generate item representations that exhibit limited interpretability, and pose challenges when transferring to language model-based recommendation systems. B) Other approaches convert user behavior sequence into image-text pairs and perform recommendation through multiple MLLM inference, incurring prohibitive computational and time costs. C) Current MLLM-based recommendation systems generally neglect the integration of collaborative signals. To address these limitations while balancing recommendation performance, interpretability, and computational cost, this paper proposes MultiModal Summarization-and-Retrieval-Augmented Sequential Recommendation. Specifically, we first employ MLLM to summarize items into concise keywords and fine-tune the model using rewards that incorporate summary length, information loss, and reconstruction difficulty, thereby enabling adaptive adjustment of the summarization policy. Inspired by retrieval-augmented generation, we then transform collaborative signals into corresponding keywords and integrate them as supplementary context. Finally, we apply supervised fine-tuning with multi-task learning to align the MLLM with the multimodal sequential recommendation. Extensive evaluations on common recommendation datasets demonstrate the effectiveness of MMSRARec, showcasing its capability to efficiently and interpretably understand user behavior histories and item information for accurate recommendations.
DsMtGCN: A Direction-sensitive Multi-task framework for Knowledge Graph Completion
Jun 17, 2023To solve the inherent incompleteness of knowledge graphs (KGs), numbers of knowledge graph completion (KGC) models have been proposed to predict missing links from known triples. Among those, several works have achieved more advanced results via exploiting the structure information on KGs with Graph Convolutional Networks (GCN). However, we observe that entity embeddings aggregated from neighbors in different directions are just simply averaged to complete single-tasks by existing GCN based models, ignoring the specific requirements of forward and backward sub-tasks. In this paper, we propose a Direction-sensitive Multi-task GCN (DsMtGCN) to make full use of the direction information, the multi-head self-attention is applied to specifically combine embeddings in different directions based on various entities and sub-tasks, the geometric constraints are imposed to adjust the distribution of embeddings, and the traditional binary cross-entropy loss is modified to reflect the triple uncertainty. Moreover, the competitive experiments results on several benchmark datasets verify the effectiveness of our model.
Contextual Dictionary Lookup for Knowledge Graph Completion
Jun 13, 2023Knowledge graph completion (KGC) aims to solve the incompleteness of knowledge graphs (KGs) by predicting missing links from known triples, numbers of knowledge graph embedding (KGE) models have been proposed to perform KGC by learning embeddings. Nevertheless, most existing embedding models map each relation into a unique vector, overlooking the specific fine-grained semantics of them under different entities. Additionally, the few available fine-grained semantic models rely on clustering algorithms, resulting in limited performance and applicability due to the cumbersome two-stage training process. In this paper, we present a novel method utilizing contextual dictionary lookup, enabling conventional embedding models to learn fine-grained semantics of relations in an end-to-end manner. More specifically, we represent each relation using a dictionary that contains multiple latent semantics. The composition of a given entity and the dictionary's central semantics serves as the context for generating a lookup, thus determining the fine-grained semantics of the relation adaptively. The proposed loss function optimizes both the central and fine-grained semantics simultaneously to ensure their semantic consistency. Besides, we introduce two metrics to assess the validity and accuracy of the dictionary lookup operation. We extend several KGE models with the method, resulting in substantial performance improvements on widely-used benchmark datasets.