 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocalOrder: Focal Preference Optimization for Reading Order Detection
Jan 12, 2026Reading order detection is the foundation of document understanding. Most existing methods rely on uniform supervision, implicitly assuming a constant difficulty distribution across layout regions. In this work, we challenge this assumption by revealing a critical flaw: \textbf{Positional Disparity}, a phenomenon where models demonstrate mastery over the deterministic start and end regions but suffer a performance collapse in the complex intermediate sections. This degradation arises because standard training allows the massive volume of easy patterns to drown out the learning signals from difficult layouts. To address this, we propose \textbf{FocalOrder}, a framework driven by \textbf{Focal Preference Optimization (FPO)}. Specifically, FocalOrder employs adaptive difficulty discovery with exponential moving average mechanism to dynamically pinpoint hard-to-learn transitions, while introducing a difficulty-calibrated pairwise ranking objective to enforce global logical consistency. Extensive experiments demonstrate that FocalOrder establishes new state-of-the-art results on OmniDocBench v1.0 and Comp-HRDoc. Our compact model not only outperforms competitive specialized baselines but also significantly surpasses large-scale general VLMs. These results demonstrate that aligning the optimization with intrinsic structural ambiguity of documents is critical for mastering complex document structures.
PARL: Position-Aware Relation Learning Network for Document Layout Analysis
Jan 12, 2026Document layout analysis aims to detect and categorize structural elements (e.g., titles, tables, figures) in scanned or digital documents. Popular methods often rely on high-quality Optical Character Recognition (OCR) to merge visual features with extracted text. This dependency introduces two major drawbacks: propagation of text recognition errors and substantial computational overhead, limiting the robustness and practical applicability of multimodal approaches. In contrast to the prevailing multimodal trend, we argue that effective layout analysis depends not on text-visual fusion, but on a deep understanding of documents' intrinsic visual structure. To this end, we propose PARL (Position-Aware Relation Learning Network), a novel OCR-free, vision-only framework that models layout through positional sensitivity and relational structure. Specifically, we first introduce a Bidirectional Spatial Position-Guided Deformable Attention module to embed explicit positional dependencies among layout elements directly into visual features. Second, we design a Graph Refinement Classifier (GRC) to refine predictions by modeling contextual relationships through a dynamically constructed layout graph. Extensive experiments show PARL achieves state-of-the-art results. It establishes a new benchmark for vision-only methods on DocLayNet and, notably, surpasses even strong multimodal models on M6Doc. Crucially, PARL (65M) is highly efficient, using roughly four times fewer parameters than large multimodal models (256M), demonstrating that sophisticated visual structure modeling can be both more efficient and robust than multimodal fusion.
Semantic Pivots Enable Cross-Lingual Transfer in Large Language Models
May 22, 2025Large language models (LLMs) demonstrate remarkable ability in cross-lingual tasks. Understanding how LLMs acquire this ability is crucial for their interpretability. To quantify the cross-lingual ability of LLMs accurately, we propose a Word-Level Cross-Lingual Translation Task. To find how LLMs learn cross-lingual ability, we trace the outputs of LLMs' intermediate layers in the word translation task. We identify and distinguish two distinct behaviors in the forward pass of LLMs: co-occurrence behavior and semantic pivot behavior. We attribute LLMs' two distinct behaviors to the co-occurrence frequency of words and find the semantic pivot from the pre-training dataset. Finally, to apply our findings to improve the cross-lingual ability of LLMs, we reconstruct a semantic pivot-aware pre-training dataset using documents with a high proportion of semantic pivots. Our experiments validate the effectiveness of our approach in enhancing cross-lingual ability. Our research contributes insights into the interpretability of LLMs and offers a method for improving LLMs' cross-lingual ability.
Transparentize the Internal and External Knowledge Utilization in LLMs with Trustworthy Citation
Apr 21, 2025While hallucinations of large language models could been alleviated through retrieval-augmented generation and citation generation, how the model utilizes internal knowledge is still opaque, and the trustworthiness of its generated answers remains questionable. In this work, we introduce Context-Prior Augmented Citation Generation task, requiring models to generate citations considering both external and internal knowledge while providing trustworthy references, with 5 evaluation metrics focusing on 3 aspects: answer helpfulness, citation faithfulness, and trustworthiness. We introduce RAEL, the paradigm for our task, and also design INTRALIGN, an integrated method containing customary data generation and an alignment algorithm. Our experimental results show that our method achieves a better cross-scenario performance with regard to other baselines. Our extended experiments further reveal that retrieval quality, question types, and model knowledge have considerable influence on the trustworthiness in citation generation.
A Multi-Agent Framework with Automated Decision Rule Optimization for Cross-Domain Misinformation Detection
Mar 30, 2025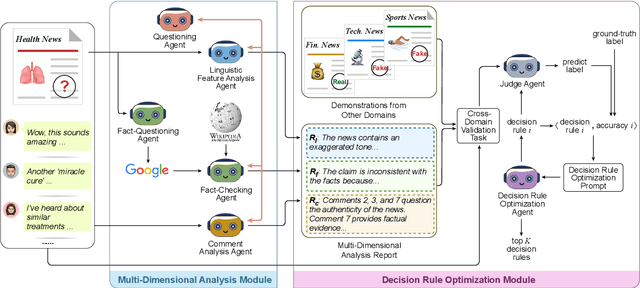
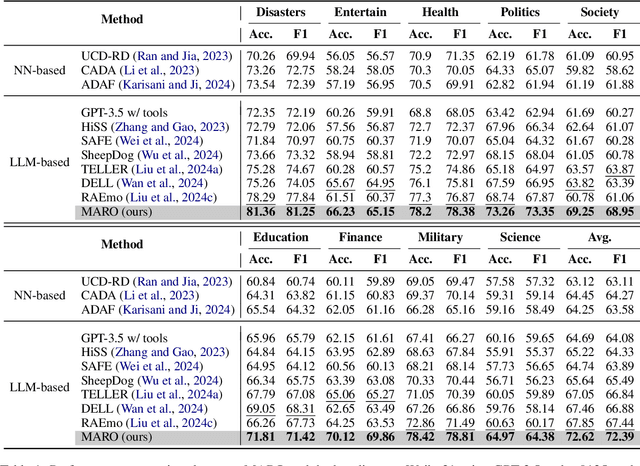
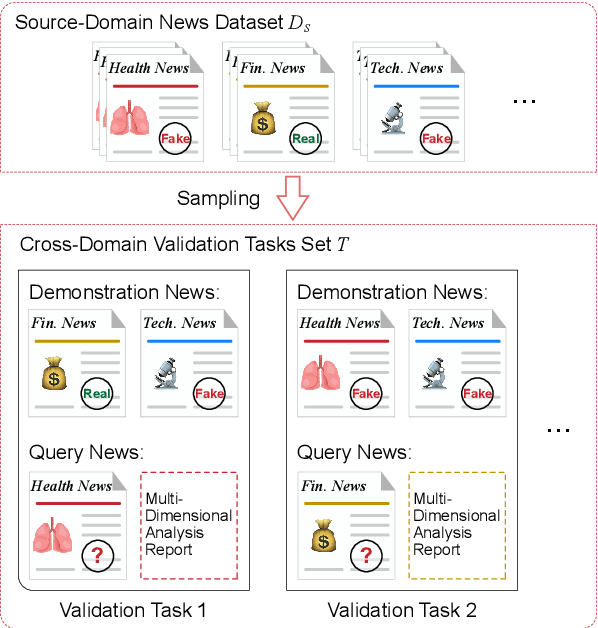
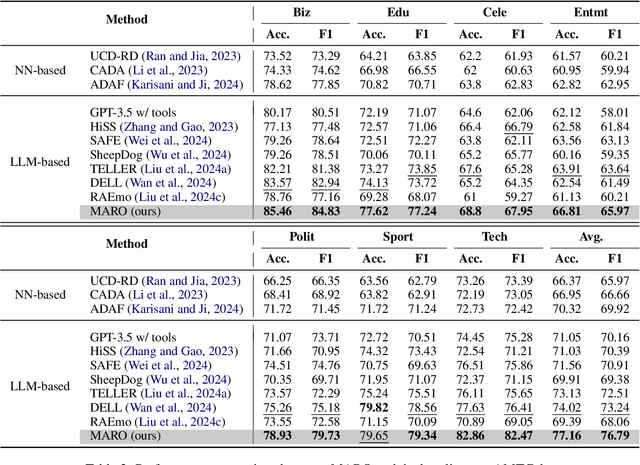
Misinformation spans various domains, but detection methods trained on specific domains often perform poorly when applied to others. With the rapid development of Large Language Models (LLMs), researchers have begun to utilize LLMs for cross-domain misinformation detection. However, existing LLM-based methods often fail to adequately analyze news in the target domain, limiting their detection capabilities. More importantly, these methods typically rely on manually designed decision rules, which are limited by domain knowledge and expert experience, thus limiting the generalizability of decision rules to different domains. To address these issues, we propose a MultiAgent Framework for cross-domain misinformation detection with Automated Decision Rule Optimization (MARO). Under this framework, we first employs multiple expert agents to analyze target-domain news. Subsequently, we introduce a question-reflection mechanism that guides expert agents to facilitate higherquality analysis. Furthermore, we propose a decision rule optimization approach based on carefully-designed cross-domain validation tasks to iteratively enhance the effectiveness of decision rules in different domains. Experimental results and in-depth analysis on commonlyused datasets demonstrate that MARO achieves significant improvements over existing methods.
Contextual Dictionary Lookup for Knowledge Graph Completion
Jun 13, 2023Knowledge graph completion (KGC) aims to solve the incompleteness of knowledge graphs (KGs) by predicting missing links from known triples, numbers of knowledge graph embedding (KGE) models have been proposed to perform KGC by learning embeddings. Nevertheless, most existing embedding models map each relation into a unique vector, overlooking the specific fine-grained semantics of them under different entities. Additionally, the few available fine-grained semantic models rely on clustering algorithms, resulting in limited performance and applicability due to the cumbersome two-stage training process. In this paper, we present a novel method utilizing contextual dictionary lookup, enabling conventional embedding models to learn fine-grained semantics of relations in an end-to-end manner. More specifically, we represent each relation using a dictionary that contains multiple latent semantics. The composition of a given entity and the dictionary's central semantics serves as the context for generating a lookup, thus determining the fine-grained semantics of the relation adaptively. The proposed loss function optimizes both the central and fine-grained semantics simultaneously to ensure their semantic consistency. Besides, we introduce two metrics to assess the validity and accuracy of the dictionary lookup operation. We extend several KGE models with the method, resulting in substantial performance improvements on widely-used benchmark datasets.
Knowledge Guided Metric Learning for Few-Shot Text Classification
Apr 04, 2020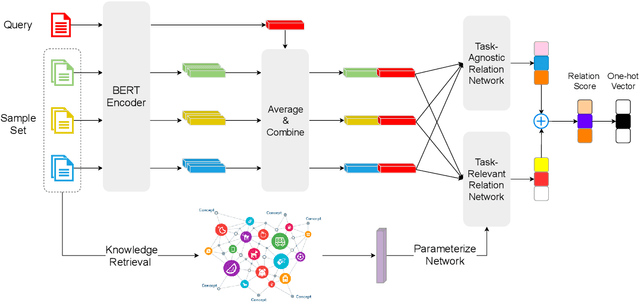
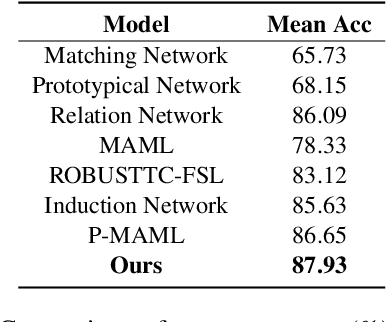
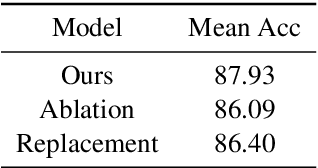
The training of deep-learning-based text classification models relies heavily on a huge amount of annotation data, which is difficult to obtain. When the labeled data is scarce, models tend to struggle to achieve satisfactory performance. However, human beings can distinguish new categories very efficiently with few examples. This is mainly due to the fact that human beings can leverage knowledge obtained from relevant tasks. Inspired by human intelligence, we propose to introduce external knowledge into few-shot learning to imitate human knowledge. A novel parameter generator network is investigated to this end, which is able to use the external knowledge to generate relation network parameters. Metrics can be transferred among tasks when equipped with these generated parameters, so that similar tasks use similar metrics while different tasks use different metrics. Through experiments, we demonstrate that our method outperforms the state-of-the-art few-shot text classification models.