 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 12: Abductive Event Reasoning: Towards Real-World Event Causal Inference for Large Language Models
Mar 23, 2026Understanding why real-world events occur is important for both natural language processing and practical decision-making, yet direct-cause inference remains underexplored in evidence-rich settings. To address this gap, we organized SemEval-2026 Task 12: Abductive Event Reasoning (AER).\footnote{The task data is available at https://github.com/sooo66/semeval2026-task12-dataset.git} The task asks systems to identify the most plausible direct cause of a target event from supporting evidence. We formulate AER as an evidence-grounded multiple-choice benchmark that captures key challenges of real-world causal reasoning, including distributed evidence, indirect background factors, and semantically related but non-causal distractors. The shared task attracted 122 participants and received 518 submissions. This paper presents the task formulation, dataset construction pipeline, evaluation setup, and system results. AER provides a focused benchmark for abductive reasoning over real-world events and highlights challenges for future work on causal reasoning and multi-document understanding.
Think While Watching: Online Streaming Segment-Level Memory for Multi-Turn Video Reasoning in Multimodal Large Language Models
Mar 12, 2026Multimodal large language models (MLLMs) have shown strong performance on offline video understanding, but most are limited to offline inference or have weak online reasoning, making multi-turn interaction over continuously arriving video streams difficult. Existing streaming methods typically use an interleaved perception-generation paradigm, which prevents concurrent perception and generation and leads to early memory decay as streams grow, hurting long-range dependency modeling. We propose Think While Watching, a memory-anchored streaming video reasoning framework that preserves continuous segment-level memory during multi-turn interaction. We build a three-stage, multi-round chain-of-thought dataset and adopt a stage-matched training strategy, while enforcing strict causality through a segment-level streaming causal mask and streaming positional encoding. During inference, we introduce an efficient pipeline that overlaps watching and thinking and adaptively selects the best attention backend. Under both single-round and multi-round streaming input protocols, our method achieves strong results. Built on Qwen3-VL, it improves single-round accuracy by 2.6% on StreamingBench and by 3.79% on OVO-Bench. In the multi-round setting, it maintains performance while reducing output tokens by 56%. Code is available at: https://github.com/wl666hhh/Think_While_Watching/
MMR-Life: Piecing Together Real-life Scenes for Multimodal Multi-image Reasoning
Mar 02, 2026Recent progress in the reasoning capabilities of multimodal large language models (MLLMs) has empowered them to address more complex tasks such as scientific analysis and mathematical reasoning. Despite their promise, MLLMs' reasoning abilities across different scenarios in real life remain largely unexplored and lack standardized benchmarks for evaluation. To address this gap, we introduce MMR-Life, a comprehensive benchmark designed to evaluate the diverse multimodal multi-image reasoning capabilities of MLLMs across real-life scenarios. MMR-Life consists of 2,646 multiple-choice questions based on 19,108 images primarily sourced from real-world contexts, comprehensively covering seven reasoning types: abductive, analogical, causal, deductive, inductive, spatial, and temporal. Unlike existing reasoning benchmarks, MMR-Life does not rely on domain-specific expertise but instead requires models to integrate information across multiple images and apply diverse reasoning abilities. The evaluation of 37 advanced models highlights the substantial challenge posed by MMR-Life. Even top models like GPT-5 achieve only 58% accuracy and display considerable variance in performance across reasoning types. Moreover, we analyze the reasoning paradigms of existing MLLMs, exploring how factors such as thinking length, reasoning method, and reasoning type affect their performance. In summary, MMR-Life establishes a comprehensive foundation for evaluating, analyzing, and improving the next generation of multimodal reasoning systems.
Explore-on-Graph: Incentivizing Autonomous Exploration of Large Language Models on Knowledge Graphs with Path-refined Reward Modeling
Feb 25, 2026The reasoning process of Large Language Models (LLMs) is often plagued by hallucinations and missing facts in question-answering tasks. A promising solution is to ground LLMs' answers in verifiable knowledge sources, such as Knowledge Graphs (KGs). Prevailing KG-enhanced methods typically constrained LLM reasoning either by enforcing rules during generation or by imitating paths from a fixed set of demonstrations. However, they naturally confined the reasoning patterns of LLMs within the scope of prior experience or fine-tuning data, limiting their generalizability to out-of-distribution graph reasoning problems. To tackle this problem, in this paper, we propose Explore-on-Graph (EoG), a novel framework that encourages LLMs to autonomously explore a more diverse reasoning space on KGs. To incentivize exploration and discovery of novel reasoning paths, we propose to introduce reinforcement learning during training, whose reward is the correctness of the reasoning paths' final answers. To enhance the efficiency and meaningfulness of the exploration, we propose to incorporate path information as additional reward signals to refine the exploration process and reduce futile efforts. Extensive experiments on five KGQA benchmark datasets demonstrate that, to the best of our knowledge, our method achieves state-of-the-art performance, outperforming not only open-source but also even closed-source LLMs.
Animal Re-Identification on Microcontrollers
Dec 09, 2025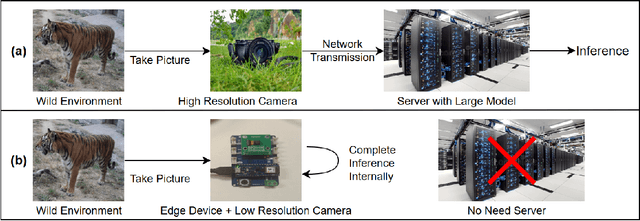



Camera-based animal re-identification (Animal Re-ID) can support wildlife monitoring and precision livestock management in large outdoor environments with limited wireless connectivity. In these settings, inference must run directly on collar tags or low-power edge nodes built around microcontrollers (MCUs), yet most Animal Re-ID models are designed for workstations or servers and are too large for devices with small memory and low-resolution inputs. We propose an on-device framework. First, we characterise the gap between state-of-the-art Animal Re-ID models and MCU-class hardware, showing that straightforward knowledge distillation from large teachers offers limited benefit once memory and input resolution are constrained. Second, guided by this analysis, we design a high-accuracy Animal Re-ID architecture by systematically scaling a CNN-based MobileNetV2 backbone for low-resolution inputs. Third, we evaluate the framework with a real-world dataset and introduce a data-efficient fine-tuning strategy to enable fast adaptation with just three images per animal identity at a new site. Across six public Animal Re-ID datasets, our compact model achieves competitive retrieval accuracy while reducing model size by over two orders of magnitude. On a self-collected cattle dataset, the deployed model performs fully on-device inference with only a small accuracy drop and unchanged Top-1 accuracy relative to its cluster version. We demonstrate that practical, adaptable Animal Re-ID is achievable on MCU-class devices, paving the way for scalable deployment in real field environments.
MotivGraph-SoIQ: Integrating Motivational Knowledge Graphs and Socratic Dialogue for Enhanced LLM Ideation
Sep 26, 2025



Large Language Models (LLMs) hold substantial potential for accelerating academic ideation but face critical challenges in grounding ideas and mitigating confirmation bias for further refinement. We propose integrating motivational knowledge graphs and socratic dialogue to address these limitations in enhanced LLM ideation (MotivGraph-SoIQ). This novel framework provides essential grounding and practical idea improvement steps for LLM ideation by integrating a Motivational Knowledge Graph (MotivGraph) with a Q-Driven Socratic Ideator. The MotivGraph structurally stores three key node types(problem, challenge and solution) to offer motivation grounding for the LLM ideation process. The Ideator is a dual-agent system utilizing Socratic questioning, which facilitates a rigorous refinement process that mitigates confirmation bias and improves idea quality across novelty, experimental rigor, and motivational rationality dimensions. On the ICLR25 paper topics dataset, MotivGraph-SoIQ exhibits clear advantages over existing state-of-the-art approaches across LLM-based scoring, ELO ranking, and human evaluation metrics.
RULE: Reinforcement UnLEarning Achieves Forget-Retain Pareto Optimality
Jun 08, 2025The widespread deployment of Large Language Models (LLMs) trained on massive, uncurated corpora has raised growing concerns about the inclusion of sensitive, copyrighted, or illegal content. This has led to increasing interest in LLM unlearning: the task of selectively removing specific information from a model without retraining from scratch or degrading overall utility. However, existing methods often rely on large-scale forget and retain datasets, and suffer from unnatural responses, poor generalization, or catastrophic utility loss. In this work, we propose Reinforcement UnLearning (RULE), an efficient framework that formulates unlearning as a refusal boundary optimization problem. RULE is trained with a small portion of the forget set and synthesized boundary queries, using a verifiable reward function that encourages safe refusal on forget--related queries while preserving helpful responses on permissible inputs. We provide both theoretical and empirical evidence demonstrating the effectiveness of RULE in achieving targeted unlearning without compromising model utility. Experimental results show that, with only $12%$ forget set and $8%$ synthesized boundary data, RULE outperforms existing baselines by up to $17.5%$ forget quality and $16.3%$ naturalness response while maintaining general utility, achieving forget--retain Pareto optimality. Remarkably, we further observe that RULE improves the naturalness of model outputs, enhances training efficiency, and exhibits strong generalization ability, generalizing refusal behavior to semantically related but unseen queries.
MMR-V: What's Left Unsaid? A Benchmark for Multimodal Deep Reasoning in Videos
Jun 04, 2025The sequential structure of videos poses a challenge to the ability of multimodal large language models (MLLMs) to locate multi-frame evidence and conduct multimodal reasoning. However, existing video benchmarks mainly focus on understanding tasks, which only require models to match frames mentioned in the question (hereafter referred to as "question frame") and perceive a few adjacent frames. To address this gap, we propose MMR-V: A Benchmark for Multimodal Deep Reasoning in Videos. The benchmark is characterized by the following features. (1) Long-range, multi-frame reasoning: Models are required to infer and analyze evidence frames that may be far from the question frame. (2) Beyond perception: Questions cannot be answered through direct perception alone but require reasoning over hidden information. (3) Reliability: All tasks are manually annotated, referencing extensive real-world user understanding to align with common perceptions. (4) Confusability: Carefully designed distractor annotation strategies to reduce model shortcuts. MMR-V consists of 317 videos and 1,257 tasks. Our experiments reveal that current models still struggle with multi-modal reasoning; even the best-performing model, o4-mini, achieves only 52.5% accuracy. Additionally, current reasoning enhancement strategies (Chain-of-Thought and scaling test-time compute) bring limited gains. Further analysis indicates that the CoT demanded for multi-modal reasoning differs from it in textual reasoning, which partly explains the limited performance gains. We hope that MMR-V can inspire further research into enhancing multi-modal reasoning capabilities.
Semantic Pivots Enable Cross-Lingual Transfer in Large Language Models
May 22, 2025Large language models (LLMs) demonstrate remarkable ability in cross-lingual tasks. Understanding how LLMs acquire this ability is crucial for their interpretability. To quantify the cross-lingual ability of LLMs accurately, we propose a Word-Level Cross-Lingual Translation Task. To find how LLMs learn cross-lingual ability, we trace the outputs of LLMs' intermediate layers in the word translation task. We identify and distinguish two distinct behaviors in the forward pass of LLMs: co-occurrence behavior and semantic pivot behavior. We attribute LLMs' two distinct behaviors to the co-occurrence frequency of words and find the semantic pivot from the pre-training dataset. Finally, to apply our findings to improve the cross-lingual ability of LLMs, we reconstruct a semantic pivot-aware pre-training dataset using documents with a high proportion of semantic pivots. Our experiments validate the effectiveness of our approach in enhancing cross-lingual ability. Our research contributes insights into the interpretability of LLMs and offers a method for improving LLMs' cross-lingual ability.
Revealing the Deceptiveness of Knowledge Editing: A Mechanistic Analysis of Superficial Editing
May 19, 2025Knowledge editing, which aims to update the knowledge encoded in language models, can be deceptive. Despite the fact that many existing knowledge editing algorithms achieve near-perfect performance on conventional metrics, the models edited by them are still prone to generating original knowledge. This paper introduces the concept of "superficial editing" to describe this phenomenon. Our comprehensive evaluation reveals that this issue presents a significant challenge to existing algorithms. Through systematic investigation, we identify and validate two key factors contributing to this issue: (1) the residual stream at the last subject position in earlier layers and (2) specific attention modules in later layers. Notably, certain attention heads in later layers, along with specific left singular vectors in their output matrices, encapsulate the original knowledge and exhibit a causal relationship with superficial editing. Furthermore, we extend our analysis to the task of superficial unlearning, where we observe consistent patterns in the behavior of specific attention heads and their corresponding left singular vectors, thereby demonstrating the robustness and broader applicability of our methodology and conclusions. Our code is available here.