 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewarding Curse: Analyze and Mitigate Reward Modeling Issues for LLM Reasoning
Mar 07, 2025Chain-of-thought (CoT) prompting demonstrates varying performance under different reasoning tasks. Previous work attempts to evaluate it but falls short in providing an in-depth analysis of patterns that influence the CoT. In this paper, we study the CoT performance from the perspective of effectiveness and faithfulness. For the former, we identify key factors that influence CoT effectiveness on performance improvement, including problem difficulty, information gain, and information flow. For the latter, we interpret the unfaithful CoT issue by conducting a joint analysis of the information interaction among the question, CoT, and answer. The result demonstrates that, when the LLM predicts answers, it can recall correct information missing in the CoT from the question, leading to the problem. Finally, we propose a novel algorithm to mitigate this issue, in which we recall extra information from the question to enhance the CoT generation and evaluate CoTs based on their information gain. Extensive experiments demonstrate that our approach enhances both the faithfulness and effectiveness of CoT.
LINKED: Eliciting, Filtering and Integrating Knowledge in Large Language Model for Commonsense Reasoning
Oct 12, 2024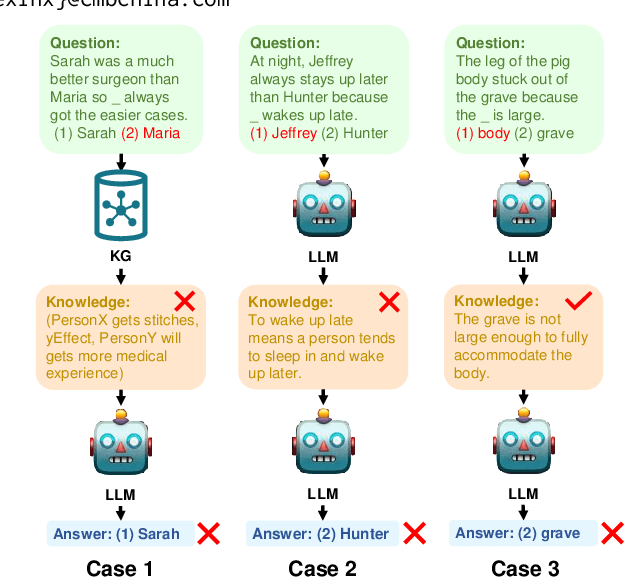

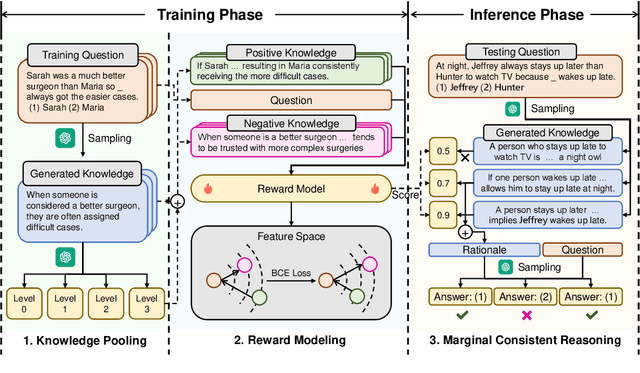

Large language models (LLMs) sometimes demonstrate poor performance on knowledge-intensive tasks, commonsense reasoning is one of them. Researchers typically address these issues by retrieving related knowledge from knowledge graphs or employing self-enhancement methods to elicit knowledge in LLMs. However, noisy knowledge and invalid reasoning issues hamper their ability to answer questions accurately. To this end, we propose a novel method named eliciting, filtering and integrating knowledge in large language model (LINKED). In it, we design a reward model to filter out the noisy knowledge and take the marginal consistent reasoning module to reduce invalid reasoning. With our comprehensive experiments on two complex commonsense reasoning benchmarks, our method outperforms SOTA baselines (up to 9.0% improvement of accuracy). Besides, to measure the positive and negative impact of the injected knowledge, we propose a new metric called effectiveness-preservation score for the knowledge enhancement works. Finally, through extensive experiments, we conduct an in-depth analysis and find many meaningful conclusions about LLMs in commonsense reasoning tasks.
SimuCourt: Building Judicial Decision-Making Agents with Real-world Judgement Documents
Mar 05, 2024



With the development of deep learning, natural language processing technology has effectively improved the efficiency of various aspects of the traditional judicial industry. However, most current efforts focus solely on individual judicial stage, overlooking cross-stage collaboration. As the autonomous agents powered by large language models are becoming increasingly smart and able to make complex decisions in real-world settings, offering new insights for judicial intelligence. In this paper, (1) we introduce SimuCourt, a judicial benchmark that encompasses 420 judgment documents from real-world, spanning the three most common types of judicial cases, and a novel task Judicial Decision-Making to evaluate the judicial analysis and decision-making power of agents. To support this task, we construct a large-scale judicial knowledge base, JudicialKB, with multiple legal knowledge. (2) we propose a novel multi-agent framework, AgentsCourt. Our framework follows the real-world classic court trial process, consisting of court debate simulation, legal information retrieval and judgement refinement to simulate the decision-making of judge. (3) we perform extensive experiments, the results demonstrate that, our framework outperforms the existing advanced methods in various aspects, especially in generating legal grounds, where our model achieves significant improvements of 8.6% and 9.1% F1 score in the first and second instance settings, respectively.
Cutting Off the Head Ends the Conflict: A Mechanism for Interpreting and Mitigating Knowledge Conflicts in Language Models
Feb 28, 2024Recently, retrieval augmentation and tool augmentation have demonstrated a remarkable capability to expand the internal memory boundaries of language models (LMs) by providing external context. However, internal memory and external context inevitably clash, leading to knowledge conflicts within LMs. In this paper, we aim to interpret the mechanism of knowledge conflicts through the lens of information flow, and then mitigate conflicts by precise interventions at the pivotal point. We find there are some attention heads with opposite effects in the later layers, where memory heads can recall knowledge from internal memory, and context heads can retrieve knowledge from external context. Moreover, we reveal that the pivotal point at which knowledge conflicts emerge in LMs is the integration of inconsistent information flows by memory heads and context heads. Inspired by the insights, we propose a novel method called Pruning Head via PatH PatcHing (PH3), which can efficiently mitigate knowledge conflicts by pruning conflicting attention heads without updating model parameters. PH3 can flexibly control eight LMs to use internal memory ($\uparrow$ 44.0%) or external context ($\uparrow$ 38.5%). Moreover, PH3 can also improve the performance of LMs on open-domain QA tasks. We also conduct extensive experiments to demonstrate the cross-model, cross-relation, and cross-format generalization of our method.
Tug-of-War Between Knowledge: Exploring and Resolving Knowledge Conflicts in Retrieval-Augmented Language Models
Feb 22, 2024Retrieval-augmented language models (RALMs) have demonstrated significant potential in refining and expanding their internal memory by retrieving evidence from external sources. However, RALMs will inevitably encounter knowledge conflicts when integrating their internal memory with external sources. Knowledge conflicts can ensnare RALMs in a tug-of-war between knowledge, limiting their practical applicability. In this paper, we focus on exploring and resolving knowledge conflicts in RALMs. First, we present an evaluation framework for assessing knowledge conflicts across various dimensions. Then, we investigate the behavior and preference of RALMs from the following two perspectives: (1) Conflicts between internal memory and external sources: We find that stronger RALMs emerge with the Dunning-Kruger effect, persistently favoring their faulty internal memory even when correct evidence is provided. Besides, RALMs exhibit an availability bias towards common knowledge; (2) Conflicts between truthful, irrelevant and misleading evidence: We reveal that RALMs follow the principle of majority rule, leaning towards placing trust in evidence that appears more frequently. Moreover, we find that RALMs exhibit confirmation bias, and are more willing to choose evidence that is consistent with their internal memory. To solve the challenge of knowledge conflicts, we propose a method called Conflict-Disentangle Contrastive Decoding (CD2) to better calibrate the model's confidence. Experimental results demonstrate that our CD2 can effectively resolve knowledge conflicts in RALMs.