 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMR-V: What's Left Unsaid? A Benchmark for Multimodal Deep Reasoning in Videos
Jun 04, 2025The sequential structure of videos poses a challenge to the ability of multimodal large language models (MLLMs) to locate multi-frame evidence and conduct multimodal reasoning. However, existing video benchmarks mainly focus on understanding tasks, which only require models to match frames mentioned in the question (hereafter referred to as "question frame") and perceive a few adjacent frames. To address this gap, we propose MMR-V: A Benchmark for Multimodal Deep Reasoning in Videos. The benchmark is characterized by the following features. (1) Long-range, multi-frame reasoning: Models are required to infer and analyze evidence frames that may be far from the question frame. (2) Beyond perception: Questions cannot be answered through direct perception alone but require reasoning over hidden information. (3) Reliability: All tasks are manually annotated, referencing extensive real-world user understanding to align with common perceptions. (4) Confusability: Carefully designed distractor annotation strategies to reduce model shortcuts. MMR-V consists of 317 videos and 1,257 tasks. Our experiments reveal that current models still struggle with multi-modal reasoning; even the best-performing model, o4-mini, achieves only 52.5% accuracy. Additionally, current reasoning enhancement strategies (Chain-of-Thought and scaling test-time compute) bring limited gains. Further analysis indicates that the CoT demanded for multi-modal reasoning differs from it in textual reasoning, which partly explains the limited performance gains. We hope that MMR-V can inspire further research into enhancing multi-modal reasoning capabilities.
Rewarding Curse: Analyze and Mitigate Reward Modeling Issues for LLM Reasoning
Mar 07, 2025Chain-of-thought (CoT) prompting demonstrates varying performance under different reasoning tasks. Previous work attempts to evaluate it but falls short in providing an in-depth analysis of patterns that influence the CoT. In this paper, we study the CoT performance from the perspective of effectiveness and faithfulness. For the former, we identify key factors that influence CoT effectiveness on performance improvement, including problem difficulty, information gain, and information flow. For the latter, we interpret the unfaithful CoT issue by conducting a joint analysis of the information interaction among the question, CoT, and answer. The result demonstrates that, when the LLM predicts answers, it can recall correct information missing in the CoT from the question, leading to the problem. Finally, we propose a novel algorithm to mitigate this issue, in which we recall extra information from the question to enhance the CoT generation and evaluate CoTs based on their information gain. Extensive experiments demonstrate that our approach enhances both the faithfulness and effectiveness of CoT.
Near-Optimal Private Learning in Linear Contextual Bandits
Feb 18, 2025We analyze the problem of private learning in generalized linear contextual bandits. Our approach is based on a novel method of re-weighted regression, yielding an efficient algorithm with regret of order $\sqrt{T}+\frac{1}{\alpha}$ and $\sqrt{T}/\alpha$ in the joint and local model of $\alpha$-privacy, respectively. Further, we provide near-optimal private procedures that achieve dimension-independent rates in private linear models and linear contextual bandits. In particular, our results imply that joint privacy is almost "for free" in all the settings we consider, partially addressing the open problem posed by Azize and Basu (2024).
MIRAGE: Evaluating and Explaining Inductive Reasoning Process in Language Models
Oct 12, 2024



Inductive reasoning is an essential capability for large language models (LLMs) to achieve higher intelligence, which requires the model to generalize rules from observed facts and then apply them to unseen examples. We present {\scshape Mirage}, a synthetic dataset that addresses the limitations of previous work, specifically the lack of comprehensive evaluation and flexible test data. In it, we evaluate LLMs' capabilities in both the inductive and deductive stages, allowing for flexible variation in input distribution, task scenario, and task difficulty to analyze the factors influencing LLMs' inductive reasoning. Based on these multi-faceted evaluations, we demonstrate that the LLM is a poor rule-based reasoner. In many cases, when conducting inductive reasoning, they do not rely on a correct rule to answer the unseen case. From the perspectives of different prompting methods, observation numbers, and task forms, models tend to consistently conduct correct deduction without correct inductive rules. Besides, we find that LLMs are good neighbor-based reasoners. In the inductive reasoning process, the model tends to focus on observed facts that are close to the current test example in feature space. By leveraging these similar examples, the model maintains strong inductive capabilities within a localized region, significantly improving its deductive performance.
LINKED: Eliciting, Filtering and Integrating Knowledge in Large Language Model for Commonsense Reasoning
Oct 12, 2024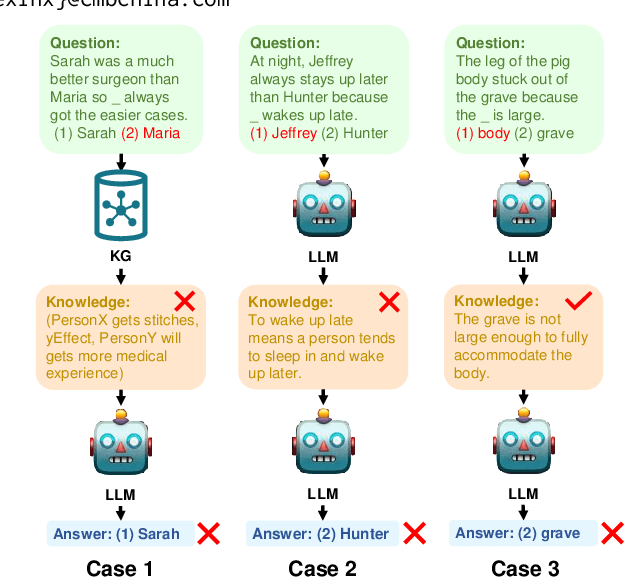

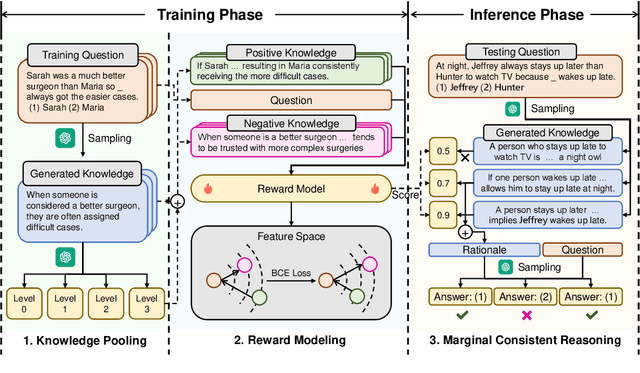

Large language models (LLMs) sometimes demonstrate poor performance on knowledge-intensive tasks, commonsense reasoning is one of them. Researchers typically address these issues by retrieving related knowledge from knowledge graphs or employing self-enhancement methods to elicit knowledge in LLMs. However, noisy knowledge and invalid reasoning issues hamper their ability to answer questions accurately. To this end, we propose a novel method named eliciting, filtering and integrating knowledge in large language model (LINKED). In it, we design a reward model to filter out the noisy knowledge and take the marginal consistent reasoning module to reduce invalid reasoning. With our comprehensive experiments on two complex commonsense reasoning benchmarks, our method outperforms SOTA baselines (up to 9.0% improvement of accuracy). Besides, to measure the positive and negative impact of the injected knowledge, we propose a new metric called effectiveness-preservation score for the knowledge enhancement works. Finally, through extensive experiments, we conduct an in-depth analysis and find many meaningful conclusions about LLMs in commonsense reasoning tasks.
The Power of Adaptivity in Experimental Design
Oct 10, 2024Given n experiment subjects with potentially heterogeneous covariates and two possible treatments, namely active treatment and control, this paper addresses the fundamental question of determining the optimal accuracy in estimating the treatment effect. Furthermore, we propose an experimental design that approaches this optimal accuracy, giving a (non-asymptotic) answer to this fundamental yet still open question. The methodological contribution is listed as following. First, we establish an idealized optimal estimator with minimal variance as benchmark, and then demonstrate that adaptive experiment is necessary to achieve near-optimal estimation accuracy. Secondly, by incorporating the concept of doubly robust method into sequential experimental design, we frame the optimal estimation problem as an online bandit learning problem, bridging the two fields of statistical estimation and bandit learning. Using tools and ideas from both bandit algorithm design and adaptive statistical estimation, we propose a general low switching adaptive experiment framework, which could be a generic research paradigm for a wide range of adaptive experimental design. Through information-theoretic lower bound combined with Bayes risk analysis, we demonstrate the optimality of our proposed experiment. Numerical result indicates that the estimation accuracy approaches optimal with as few as two or three policy updates.
Towards Scalable GPU-Accelerated SNN Training via Temporal Fusion
Aug 01, 2024



Drawing on the intricate structures of the brain, Spiking Neural Networks (SNNs) emerge as a transformative development in artificial intelligence, closely emulating the complex dynamics of biological neural networks. While SNNs show promising efficiency on specialized sparse-computational hardware, their practical training often relies on conventional GPUs. This reliance frequently leads to extended computation times when contrasted with traditional Artificial Neural Networks (ANNs), presenting significant hurdles for advancing SNN research. To navigate this challenge, we present a novel temporal fusion method, specifically designed to expedite the propagation dynamics of SNNs on GPU platforms, which serves as an enhancement to the current significant approaches for handling deep learning tasks with SNNs. This method underwent thorough validation through extensive experiments in both authentic training scenarios and idealized conditions, confirming its efficacy and adaptability for single and multi-GPU systems. Benchmarked against various existing SNN libraries/implementations, our method achieved accelerations ranging from $5\times$ to $40\times$ on NVIDIA A100 GPUs. Publicly available experimental codes can be found at https://github.com/EMI-Group/snn-temporal-fusion.
RWKU: Benchmarking Real-World Knowledge Unlearning for Large Language Models
Jun 16, 2024Large language models (LLMs) inevitably memorize sensitive, copyrighted, and harmful knowledge from the training corpus; therefore, it is crucial to erase this knowledge from the models. Machine unlearning is a promising solution for efficiently removing specific knowledge by post hoc modifying models. In this paper, we propose a Real-World Knowledge Unlearning benchmark (RWKU) for LLM unlearning. RWKU is designed based on the following three key factors: (1) For the task setting, we consider a more practical and challenging unlearning setting, where neither the forget corpus nor the retain corpus is accessible. (2) For the knowledge source, we choose 200 real-world famous people as the unlearning targets and show that such popular knowledge is widely present in various LLMs. (3) For the evaluation framework, we design the forget set and the retain set to evaluate the model's capabilities across various real-world applications. Regarding the forget set, we provide four four membership inference attack (MIA) methods and nine kinds of adversarial attack probes to rigorously test unlearning efficacy. Regarding the retain set, we assess locality and utility in terms of neighbor perturbation, general ability, reasoning ability, truthfulness, factuality, and fluency. We conduct extensive experiments across two unlearning scenarios, two models and six baseline methods and obtain some meaningful findings. We release our benchmark and code publicly at http://rwku-bench.github.io for future work.
Towards Faithful Chain-of-Thought: Large Language Models are Bridging Reasoners
May 29, 2024Large language models (LLMs) suffer from serious unfaithful chain-of-thought (CoT) issues. Previous work attempts to measure and explain it but lacks in-depth analysis within CoTs and does not consider the interactions among all reasoning components jointly. In this paper, we first study the CoT faithfulness issue at the granularity of CoT steps, identify two reasoning paradigms: centralized reasoning and distributed reasoning, and find their relationship with faithfulness. Subsequently, we conduct a joint analysis of the causal relevance among the context, CoT, and answer during reasoning. The result proves that, when the LLM predicts answers, it can recall correct information missing in the CoT from the context, leading to unfaithfulness issues. Finally, we propose the inferential bridging method to mitigate this issue, in which we use the attribution method to recall information as hints for CoT generation and filter out noisy CoTs based on their semantic consistency and attribution scores. Extensive experiments demonstrate that our approach effectively alleviates the unfaithful CoT problem.
On the Optimal Regret of Locally Private Linear Contextual Bandit
Apr 15, 2024Contextual bandit with linear reward functions is among one of the most extensively studied models in bandit and online learning research. Recently, there has been increasing interest in designing \emph{locally private} linear contextual bandit algorithms, where sensitive information contained in contexts and rewards is protected against leakage to the general public. While the classical linear contextual bandit algorithm admits cumulative regret upper bounds of $\tilde O(\sqrt{T})$ via multiple alternative methods, it has remained open whether such regret bounds are attainable in the presence of local privacy constraints, with the state-of-the-art result being $\tilde O(T^{3/4})$. In this paper, we show that it is indeed possible to achieve an $\tilde O(\sqrt{T})$ regret upper bound for locally private linear contextual bandit. Our solution relies on several new algorithmic and analytical ideas, such as the analysis of mean absolute deviation errors and layered principal component regression in order to achieve small mean absolute deviation errors.