 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorNEAT: A GPU-accelerated Library for NeuroEvolution of Augmenting Topologies
Apr 11, 2025



The NeuroEvolution of Augmenting Topologies (NEAT) algorithm has received considerable recognition in the field of neuroevolution. Its effectiveness is derived from initiating with simple networks and incrementally evolving both their topologies and weights. Although its capability across various challenges is evident, the algorithm's computational efficiency remains an impediment, limiting its scalability potential. To address these limitations, this paper introduces TensorNEAT, a GPU-accelerated library that applies tensorization to the NEAT algorithm. Tensorization reformulates NEAT's diverse network topologies and operations into uniformly shaped tensors, enabling efficient parallel execution across entire populations. TensorNEAT is built upon JAX, leveraging automatic function vectorization and hardware acceleration to significantly enhance computational efficiency. In addition to NEAT, the library supports variants such as CPPN and HyperNEAT, and integrates with benchmark environments like Gym, Brax, and gymnax. Experimental evaluations across various robotic control environments in Brax demonstrate that TensorNEAT delivers up to 500x speedups compared to existing implementations, such as NEAT-Python. The source code for TensorNEAT is publicly available at: https://github.com/EMI-Group/tensorneat.
Bridging Evolutionary Multiobjective Optimization and GPU Acceleration via Tensorization
Mar 27, 2025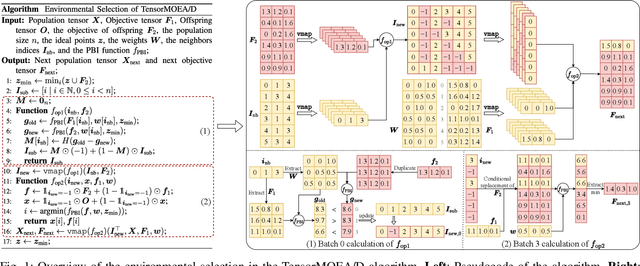

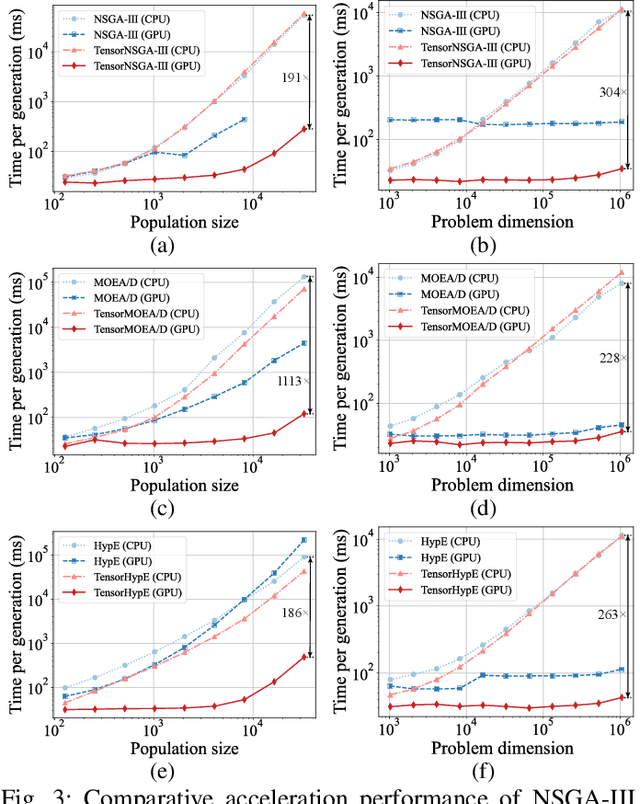
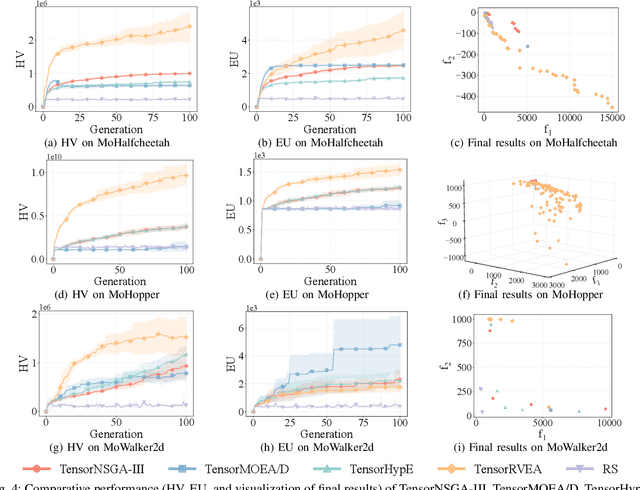
Evolutionary multiobjective optimization (EMO) has made significant strides over the past two decades. However, as problem scales and complexities increase, traditional EMO algorithms face substantial performance limitations due to insufficient parallelism and scalability. While most work has focused on algorithm design to address these challenges, little attention has been given to hardware acceleration, thereby leaving a clear gap between EMO algorithms and advanced computing devices, such as GPUs. To bridge the gap, we propose to parallelize EMO algorithms on GPUs via the tensorization methodology. By employing tensorization, the data structures and operations of EMO algorithms are transformed into concise tensor representations, which seamlessly enables automatic utilization of GPU computing. We demonstrate the effectiveness of our approach by applying it to three representative EMO algorithms: NSGA-III, MOEA/D, and HypE. To comprehensively assess our methodology, we introduce a multiobjective robot control benchmark using a GPU-accelerated physics engine. Our experiments show that the tensorized EMO algorithms achieve speedups of up to 1113x compared to their CPU-based counterparts, while maintaining solution quality and effectively scaling population sizes to hundreds of thousands. Furthermore, the tensorized EMO algorithms efficiently tackle complex multiobjective robot control tasks, producing high-quality solutions with diverse behaviors. Source codes are available at https://github.com/EMI-Group/evomo.
Towards Scalable GPU-Accelerated SNN Training via Temporal Fusion
Aug 01, 2024



Drawing on the intricate structures of the brain, Spiking Neural Networks (SNNs) emerge as a transformative development in artificial intelligence, closely emulating the complex dynamics of biological neural networks. While SNNs show promising efficiency on specialized sparse-computational hardware, their practical training often relies on conventional GPUs. This reliance frequently leads to extended computation times when contrasted with traditional Artificial Neural Networks (ANNs), presenting significant hurdles for advancing SNN research. To navigate this challenge, we present a novel temporal fusion method, specifically designed to expedite the propagation dynamics of SNNs on GPU platforms, which serves as an enhancement to the current significant approaches for handling deep learning tasks with SNNs. This method underwent thorough validation through extensive experiments in both authentic training scenarios and idealized conditions, confirming its efficacy and adaptability for single and multi-GPU systems. Benchmarked against various existing SNN libraries/implementations, our method achieved accelerations ranging from $5\times$ to $40\times$ on NVIDIA A100 GPUs. Publicly available experimental codes can be found at https://github.com/EMI-Group/snn-temporal-fusion.
GPU-accelerated Evolutionary Multiobjective Optimization Using Tensorized RVEA
Apr 11, 2024Evolutionary multiobjective optimization has witnessed remarkable progress during the past decades. However, existing algorithms often encounter computational challenges in large-scale scenarios, primarily attributed to the absence of hardware acceleration. In response, we introduce a Tensorized Reference Vector Guided Evolutionary Algorithm (TensorRVEA) for harnessing the advancements of GPU acceleration. In TensorRVEA, the key data structures and operators are fully transformed into tensor forms for leveraging GPU-based parallel computing. In numerical benchmark tests involving large-scale populations and problem dimensions, TensorRVEA consistently demonstrates high computational performance, achieving up to over 1000$\times$ speedups. Then, we applied TensorRVEA to the domain of multiobjective neuroevolution for addressing complex challenges in robotic control tasks. Furthermore, we assessed TensorRVEA's extensibility by altering several tensorized reproduction operators. Experimental results demonstrate promising scalability and robustness of TensorRVEA. Source codes are available at \url{https://github.com/EMI-Group/tensorrvea}.
Tensorized NeuroEvolution of Augmenting Topologies for GPU Acceleration
Apr 11, 2024

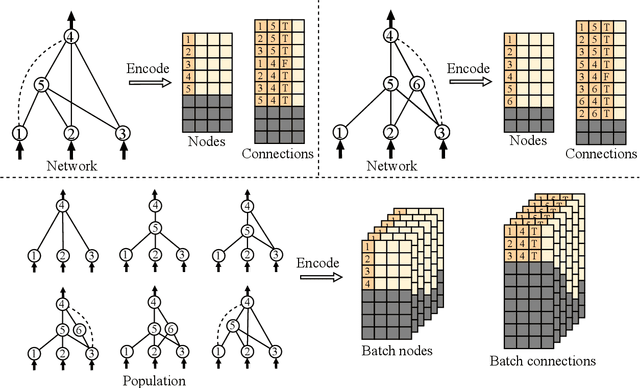

The NeuroEvolution of Augmenting Topologies (NEAT) algorithm has received considerable recognition in the field of neuroevolution. Its effectiveness is derived from initiating with simple networks and incrementally evolving both their topologies and weights. Although its capability across various challenges is evident, the algorithm's computational efficiency remains an impediment, limiting its scalability potential. In response, this paper introduces a tensorization method for the NEAT algorithm, enabling the transformation of its diverse network topologies and associated operations into uniformly shaped tensors for computation. This advancement facilitates the execution of the NEAT algorithm in a parallelized manner across the entire population. Furthermore, we develop TensorNEAT, a library that implements the tensorized NEAT algorithm and its variants, such as CPPN and HyperNEAT. Building upon JAX, TensorNEAT promotes efficient parallel computations via automated function vectorization and hardware acceleration. Moreover, the TensorNEAT library supports various benchmark environments including Gym, Brax, and gymnax. Through evaluations across a spectrum of robotics control environments in Brax, TensorNEAT achieves up to 500x speedups compared to the existing implementations such as NEAT-Python. Source codes are available at: https://github.com/EMI-Group/tensorneat.