 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAR: Efficient Large Language Models via Module-aware Architecture Refinement
Jan 29, 2026Large Language Models (LLMs) excel across diverse domains but suffer from high energy costs due to quadratic attention and dense Feed-Forward Network (FFN) operations. To address these issues, we propose Module-aware Architecture Refinement (MAR), a two-stage framework that integrates State Space Models (SSMs) for linear-time sequence modeling and applies activation sparsification to reduce FFN costs. In addition, to mitigate low information density and temporal mismatch in integrating Spiking Neural Networks (SNNs) with SSMs, we design the Adaptive Ternary Multi-step Neuron (ATMN) and the Spike-aware Bidirectional Distillation Strategy (SBDS). Extensive experiments demonstrate that MAR effectively restores the performance of its dense counterpart under constrained resources while substantially reducing inference energy consumption. Furthermore, it outperforms efficient models of comparable or even larger scale, underscoring its potential for building efficient and practical LLMs.
Hebbian Learning with Global Direction
Jan 29, 2026Backpropagation algorithm has driven the remarkable success of deep neural networks, but its lack of biological plausibility and high computational costs have motivated the ongoing search for alternative training methods. Hebbian learning has attracted considerable interest as a biologically plausible alternative to backpropagation. Nevertheless, its exclusive reliance on local information, without consideration of global task objectives, fundamentally limits its scalability. Inspired by the biological synergy between neuromodulators and local plasticity, we introduce a novel model-agnostic Global-guided Hebbian Learning (GHL) framework, which seamlessly integrates local and global information to scale up across diverse networks and tasks. In specific, the local component employs Oja's rule with competitive learning to ensure stable and effective local updates. Meanwhile, the global component introduces a sign-based signal that guides the direction of local Hebbian plasticity updates. Extensive experiments demonstrate that our method consistently outperforms existing Hebbian approaches. Notably, on large-scale network and complex datasets like ImageNet, our framework achieves the competitive results and significantly narrows the gap with standard backpropagation.
Temporal-Guided Visual Foundation Models for Event-Based Vision
Nov 09, 2025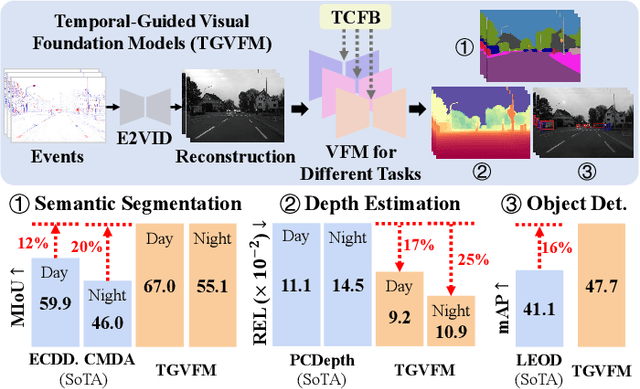
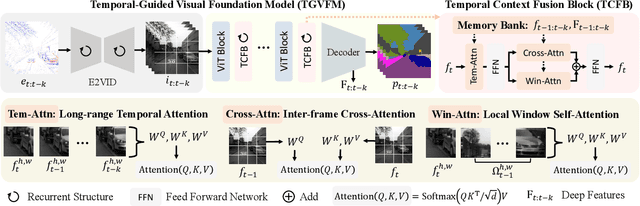


Event cameras offer unique advantages for vision tasks in challenging environments, yet processing asynchronous event streams remains an open challenge. While existing methods rely on specialized architectures or resource-intensive training, the potential of leveraging modern Visual Foundation Models (VFMs) pretrained on image data remains under-explored for event-based vision. To address this, we propose Temporal-Guided VFM (TGVFM), a novel framework that integrates VFMs with our temporal context fusion block seamlessly to bridge this gap. Our temporal block introduces three key components: (1) Long-Range Temporal Attention to model global temporal dependencies, (2) Dual Spatiotemporal Attention for multi-scale frame correlation, and (3) Deep Feature Guidance Mechanism to fuse semantic-temporal features. By retraining event-to-video models on real-world data and leveraging transformer-based VFMs, TGVFM preserves spatiotemporal dynamics while harnessing pretrained representations. Experiments demonstrate SoTA performance across semantic segmentation, depth estimation, and object detection, with improvements of 16%, 21%, and 16% over existing methods, respectively. Overall, this work unlocks the cross-modality potential of image-based VFMs for event-based vision with temporal reasoning. Code is available at https://github.com/XiaRho/TGVFM.
SpikingMamba: Towards Energy-Efficient Large Language Models via Knowledge Distillation from Mamba
Oct 06, 2025
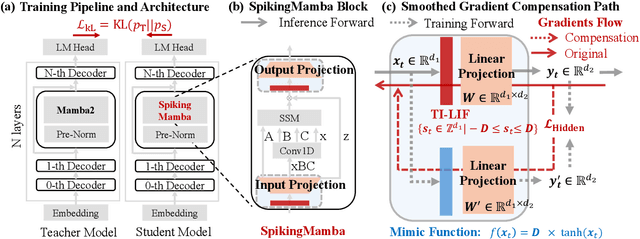


Large Language Models (LLMs) have achieved remarkable performance across tasks but remain energy-intensive due to dense matrix operations. Spiking neural networks (SNNs) improve energy efficiency by replacing dense matrix multiplications with sparse accumulations. Their sparse spike activity enables efficient LLMs deployment on edge devices. However, prior SNN-based LLMs often sacrifice performance for efficiency, and recovering accuracy typically requires full pretraining, which is costly and impractical. To address this, we propose SpikingMamba, an energy-efficient SNN-based LLMs distilled from Mamba that improves energy efficiency with minimal accuracy sacrifice. SpikingMamba integrates two key components: (a) TI-LIF, a ternary-integer spiking neuron that preserves semantic polarity through signed multi-level spike representations. (b) A training-exclusive Smoothed Gradient Compensation (SGC) path mitigating quantization loss while preserving spike-driven efficiency. We employ a single-stage distillation strategy to transfer the zero-shot ability of pretrained Mamba and further enhance it via reinforcement learning (RL). Experiments show that SpikingMamba-1.3B achieves a 4.76$\times$ energy benefit, with only a 4.78\% zero-shot accuracy gap compared to the original Mamba, and achieves a further 2.55\% accuracy improvement after RL.
Threshold Modulation for Online Test-Time Adaptation of Spiking Neural Networks
May 08, 2025



Recently, spiking neural networks (SNNs), deployed on neuromorphic chips, provide highly efficient solutions on edge devices in different scenarios. However, their ability to adapt to distribution shifts after deployment has become a crucial challenge. Online test-time adaptation (OTTA) offers a promising solution by enabling models to dynamically adjust to new data distributions without requiring source data or labeled target samples. Nevertheless, existing OTTA methods are largely designed for traditional artificial neural networks and are not well-suited for SNNs. To address this gap, we propose a low-power, neuromorphic chip-friendly online test-time adaptation framework, aiming to enhance model generalization under distribution shifts. The proposed approach is called Threshold Modulation (TM), which dynamically adjusts the firing threshold through neuronal dynamics-inspired normalization, being more compatible with neuromorphic hardware. Experimental results on benchmark datasets demonstrate the effectiveness of this method in improving the robustness of SNNs against distribution shifts while maintaining low computational cost. The proposed method offers a practical solution for online test-time adaptation of SNNs, providing inspiration for the design of future neuromorphic chips. The demo code is available at github.com/NneurotransmitterR/TM-OTTA-SNN.
Scaling Spike-driven Transformer with Efficient Spike Firing Approximation Training
Nov 25, 2024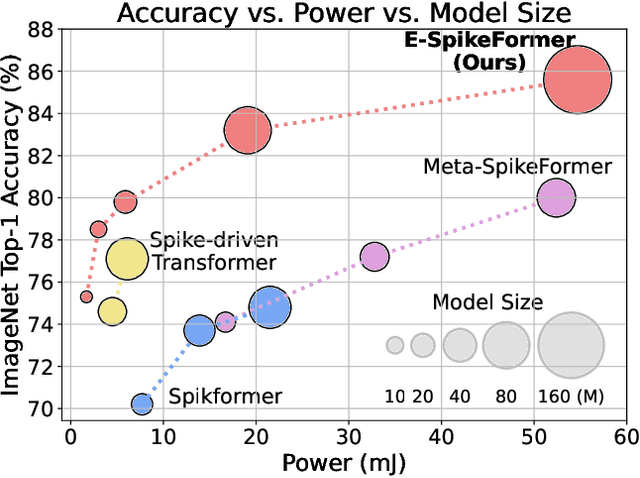
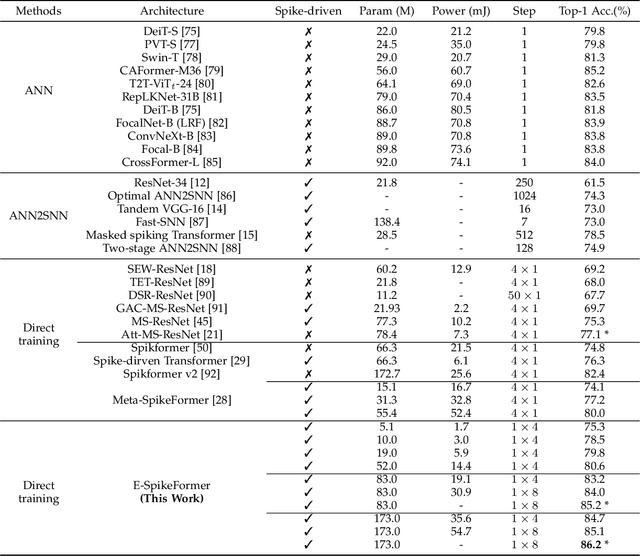
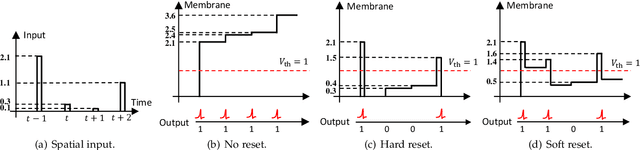
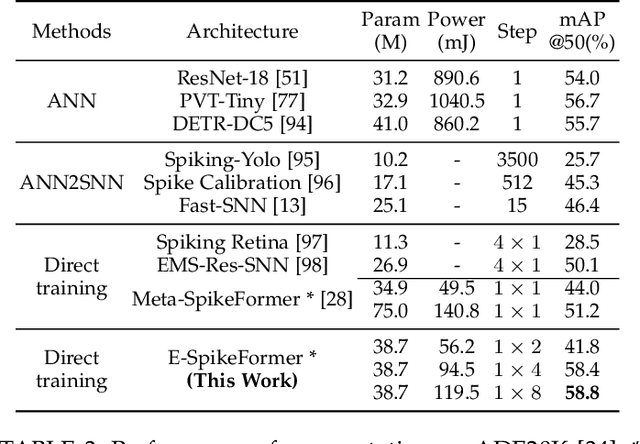
The ambition of brain-inspired Spiking Neural Networks (SNNs) is to become a low-power alternative to traditional Artificial Neural Networks (ANNs). This work addresses two major challenges in realizing this vision: the performance gap between SNNs and ANNs, and the high training costs of SNNs. We identify intrinsic flaws in spiking neurons caused by binary firing mechanisms and propose a Spike Firing Approximation (SFA) method using integer training and spike-driven inference. This optimizes the spike firing pattern of spiking neurons, enhancing efficient training, reducing power consumption, improving performance, enabling easier scaling, and better utilizing neuromorphic chips. We also develop an efficient spike-driven Transformer architecture and a spike-masked autoencoder to prevent performance degradation during SNN scaling. On ImageNet-1k, we achieve state-of-the-art top-1 accuracy of 78.5\%, 79.8\%, 84.0\%, and 86.2\% with models containing 10M, 19M, 83M, and 173M parameters, respectively. For instance, the 10M model outperforms the best existing SNN by 7.2\% on ImageNet, with training time acceleration and inference energy efficiency improved by 4.5$\times$ and 3.9$\times$, respectively. We validate the effectiveness and efficiency of the proposed method across various tasks, including object detection, semantic segmentation, and neuromorphic vision tasks. This work enables SNNs to match ANN performance while maintaining the low-power advantage, marking a significant step towards SNNs as a general visual backbone. Code is available at https://github.com/BICLab/Spike-Driven-Transformer-V3.
Spatial-Temporal Search for Spiking Neural Networks
Oct 24, 2024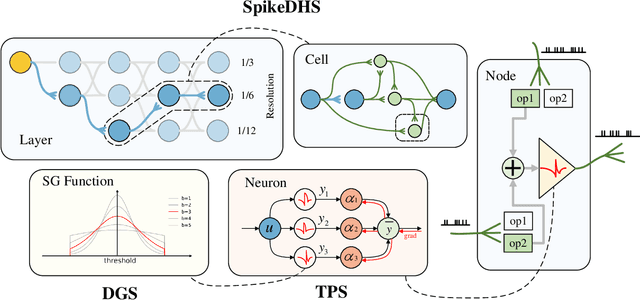

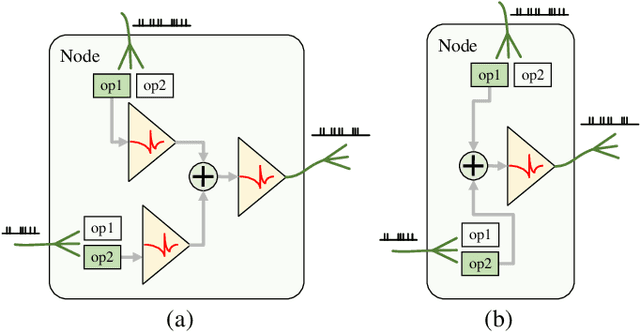
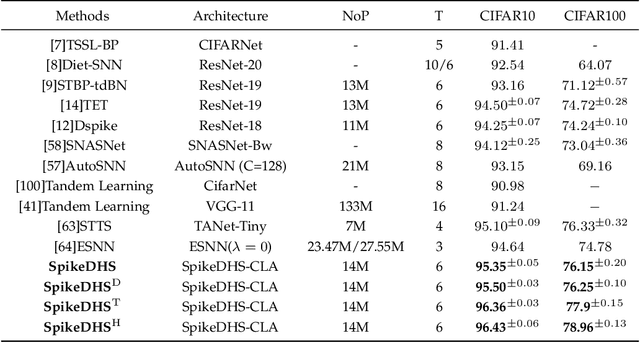
Spiking Neural Networks (SNNs) are considered as a potential candidate for the next generation of artificial intelligence with appealing characteristics such as sparse computation and inherent temporal dynamics. By adopting architectures of Artificial Neural Networks (ANNs), SNNs achieve competitive performances on benchmark tasks like image classification. However, successful architectures of ANNs are not optimal for SNNs. In this work, we apply Neural Architecture Search (NAS) to find suitable architectures for SNNs. Previous NAS methods for SNNs focus primarily on the spatial dimension, with a notable lack of consideration for the temporal dynamics that are of critical importance for SNNs. Drawing inspiration from the heterogeneity of biological neural networks, we propose a differentiable approach to optimize SNN on both spatial and temporal dimensions. At spatial level, we have developed a spike-based differentiable hierarchical search (SpikeDHS) framework, where spike-based operation is optimized on both the cell and the layer level under computational constraints. We further propose a differentiable surrogate gradient search (DGS) method to evolve local SG functions independently during training. At temporal level, we explore an optimal configuration of diverse temporal dynamics on different types of spiking neurons by evolving their time constants, based on which we further develop hybrid networks combining SNN and ANN, balancing both accuracy and efficiency. Our methods achieve comparable classification performance of CIFAR10/100 and ImageNet with accuracies of 96.43%, 78.96%, and 70.21%, respectively. On event-based deep stereo, our methods find optimal layer variation and surpass the accuracy of specially designed ANNs with 26$\times$ lower computational cost ($6.7\mathrm{mJ}$), demonstrating the potential of SNN in processing highly sparse and dynamic signals.
SpikingSSMs: Learning Long Sequences with Sparse and Parallel Spiking State Space Models
Aug 27, 2024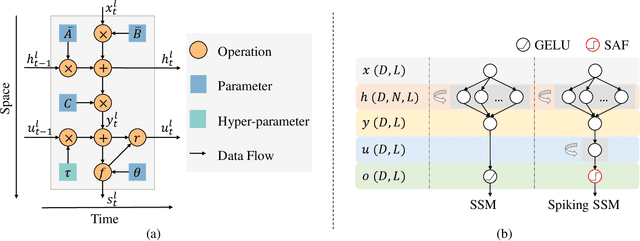
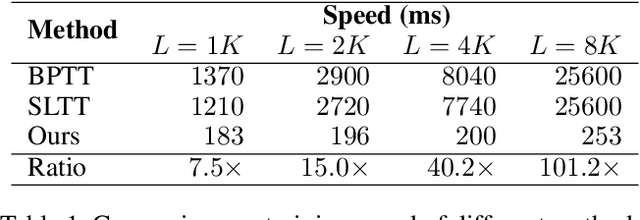
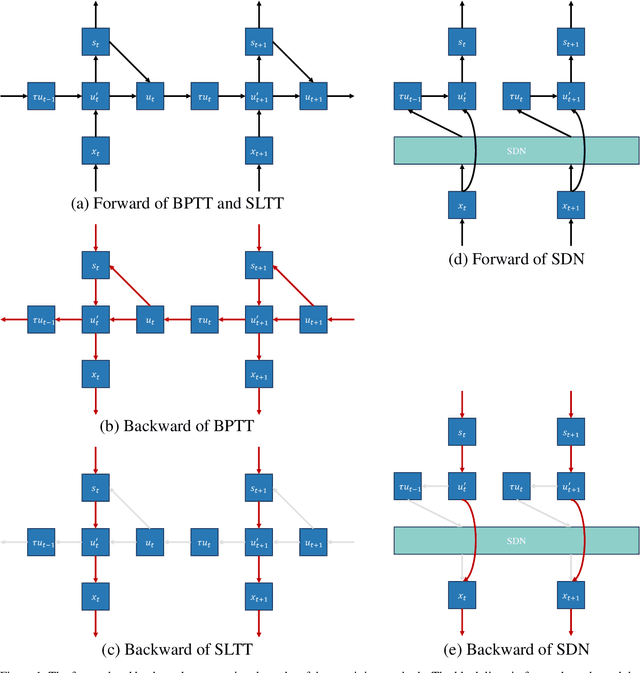
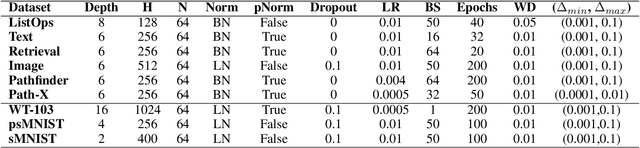
Known as low energy consumption networks, spiking neural networks (SNNs) have gained a lot of attention within the past decades. While SNNs are increasing competitive with artificial neural networks (ANNs) for vision tasks, they are rarely used for long sequence tasks, despite their intrinsic temporal dynamics. In this work, we develop spiking state space models (SpikingSSMs) for long sequence learning by leveraging on the sequence learning abilities of state space models (SSMs). Inspired by dendritic neuron structure, we hierarchically integrate neuronal dynamics with the original SSM block, meanwhile realizing sparse synaptic computation. Furthermore, to solve the conflict of event-driven neuronal dynamics with parallel computing, we propose a light-weight surrogate dynamic network which accurately predicts the after-reset membrane potential and compatible to learnable thresholds, enabling orders of acceleration in training speed compared with conventional iterative methods. On the long range arena benchmark task, SpikingSSM achieves competitive performance to state-of-the-art SSMs meanwhile realizing on average 90\% of network sparsity. On language modeling, our network significantly surpasses existing spiking large language models (spikingLLMs) on the WikiText-103 dataset with only a third of the model size, demonstrating its potential as backbone architecture for low computation cost LLMs.
Towards Scalable GPU-Accelerated SNN Training via Temporal Fusion
Aug 01, 2024



Drawing on the intricate structures of the brain, Spiking Neural Networks (SNNs) emerge as a transformative development in artificial intelligence, closely emulating the complex dynamics of biological neural networks. While SNNs show promising efficiency on specialized sparse-computational hardware, their practical training often relies on conventional GPUs. This reliance frequently leads to extended computation times when contrasted with traditional Artificial Neural Networks (ANNs), presenting significant hurdles for advancing SNN research. To navigate this challenge, we present a novel temporal fusion method, specifically designed to expedite the propagation dynamics of SNNs on GPU platforms, which serves as an enhancement to the current significant approaches for handling deep learning tasks with SNNs. This method underwent thorough validation through extensive experiments in both authentic training scenarios and idealized conditions, confirming its efficacy and adaptability for single and multi-GPU systems. Benchmarked against various existing SNN libraries/implementations, our method achieved accelerations ranging from $5\times$ to $40\times$ on NVIDIA A100 GPUs. Publicly available experimental codes can be found at https://github.com/EMI-Group/snn-temporal-fusion.
Evolutionary Spiking Neural Networks: A Survey
Jun 18, 2024Spiking neural networks (SNNs) are gaining increasing attention as potential computationally efficient alternatives to traditional artificial neural networks(ANNs). However, the unique information propagation mechanisms and the complexity of SNN neuron models pose challenges for adopting traditional methods developed for ANNs to SNNs. These challenges include both weight learning and architecture design. While surrogate gradient learning has shown some success in addressing the former challenge, the latter remains relatively unexplored. Recently, a novel paradigm utilizing evolutionary computation methods has emerged to tackle these challenges. This approach has resulted in the development of a variety of energy-efficient and high-performance SNNs across a wide range of machine learning benchmarks. In this paper, we present a survey of these works and initiate discussions on potential challenges ahead.