 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTele-Omni: a Unified Multimodal Framework for Video Generation and Editing
Feb 10, 2026Recent advances in diffusion-based video generation have substantially improved visual fidelity and temporal coherence. However, most existing approaches remain task-specific and rely primarily on textual instructions, limiting their ability to handle multimodal inputs, contextual references, and diverse video generation and editing scenarios within a unified framework. Moreover, many video editing methods depend on carefully engineered pipelines tailored to individual operations, which hinders scalability and composability. In this paper, we propose Tele-Omni, a unified multimodal framework for video generation and editing that follows multimodal instructions, including text, images, and reference videos, within a single model. Tele-Omni leverages pretrained multimodal large language models to parse heterogeneous instructions and infer structured generation or editing intents, while diffusion-based generators perform high-quality video synthesis conditioned on these structured signals. To enable joint training across heterogeneous video tasks, we introduce a task-aware data processing pipeline that unifies multimodal inputs into a structured instruction format while preserving task-specific constraints. Tele-Omni supports a wide range of video-centric tasks, including text-to-video generation, image-to-video generation, first-last-frame video generation, in-context video generation, and in-context video editing. By decoupling instruction parsing from video synthesis and combining it with task-aware data design, Tele-Omni achieves flexible multimodal control while maintaining strong temporal coherence and visual consistency. Experimental results demonstrate that Tele-Omni achieves competitive performance across multiple tasks.
Bridging Information Asymmetry: A Hierarchical Framework for Deterministic Blind Face Restoration
Jan 27, 2026Blind face restoration remains a persistent challenge due to the inherent ill-posedness of reconstructing holistic structures from severely constrained observations. Current generative approaches, while capable of synthesizing realistic textures, often suffer from information asymmetry -- the intrinsic disparity between the information-sparse low quality inputs and the information-dense high quality outputs. This imbalance leads to a one-to-many mapping, where insufficient constraints result in stochastic uncertainty and hallucinatory artifacts. To bridge this gap, we present \textbf{Pref-Restore}, a hierarchical framework that integrates discrete semantic logic with continuous texture generation to achieve deterministic, preference-aligned restoration. Our methodology fundamentally addresses this information disparity through two complementary strategies: (1) Augmenting Input Density: We employ an auto-regressive integrator to reformulate textual instructions into dense latent queries, injecting high-level semantic stability to constrain the degraded signals; (2) Pruning Output Distribution: We pioneer the integration of on-policy reinforcement learning directly into the diffusion restoration loop. By transforming human preferences into differentiable constraints, we explicitly penalize stochastic deviations, thereby sharpening the posterior distribution toward the desired high-fidelity outcomes. Extensive experiments demonstrate that Pref-Restore achieves state-of-the-art performance across synthetic and real-world benchmarks. Furthermore, empirical analysis confirms that our preference-aligned strategy significantly reduces solution entropy, establishing a robust pathway toward reliable and deterministic blind restoration.
AdaTok: Adaptive Token Compression with Object-Aware Representations for Efficient Multimodal LLMs
Nov 18, 2025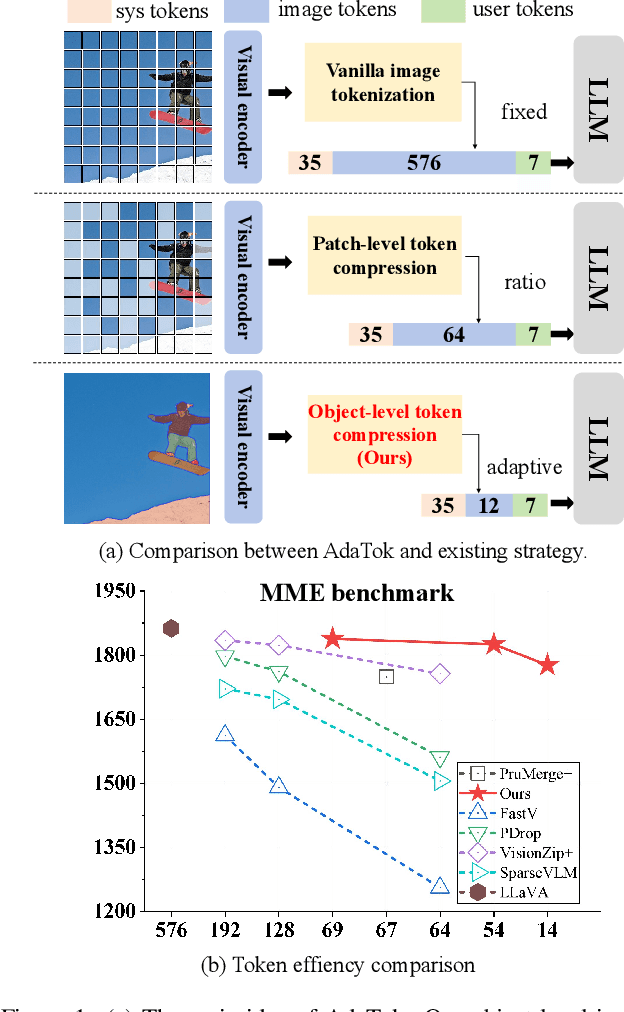
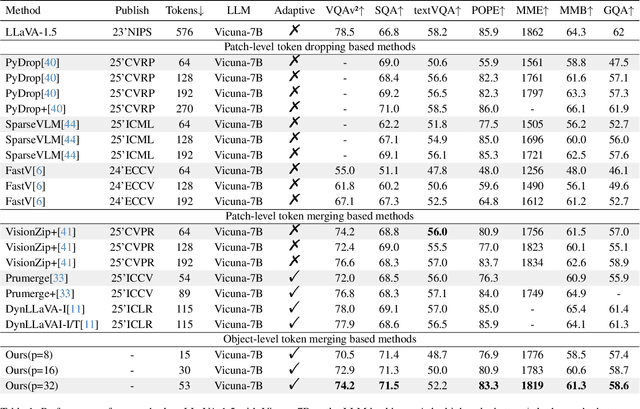
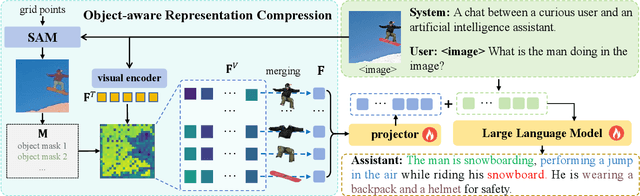
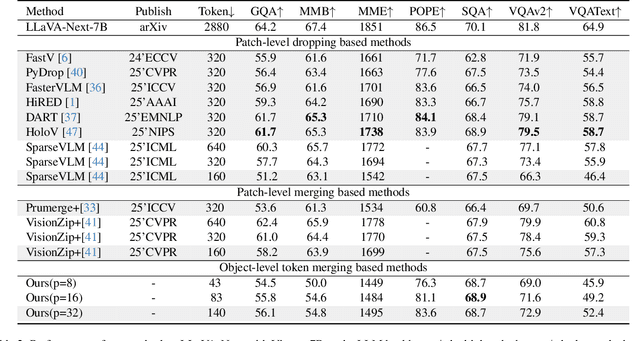
Multimodal Large Language Models (MLLMs) have demonstrated substantial value in unified text-image understanding and reasoning, primarily by converting images into sequences of patch-level tokens that align with their architectural paradigm. However, patch-level tokenization leads to a quadratic growth in image tokens, burdening MLLMs' understanding and reasoning with enormous computation and memory. Additionally, the traditional patch-wise scanning tokenization workflow misaligns with the human vision cognition system, further leading to hallucination and computational redundancy. To address this issue, we propose an object-level token merging strategy for Adaptive Token compression, revealing the consistency with human vision system. The experiments are conducted on multiple comprehensive benchmarks, which show that our approach averagely, utilizes only 10% tokens while achieving almost 96% of the vanilla model's performance. More extensive experimental results in comparison with relevant works demonstrate the superiority of our method in balancing compression ratio and performance. Our code will be available.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Spike2Former: Efficient Spiking Transformer for High-performance Image Segmentation
Dec 19, 2024



Spiking Neural Networks (SNNs) have a low-power advantage but perform poorly in image segmentation tasks. The reason is that directly converting neural networks with complex architectural designs for segmentation tasks into spiking versions leads to performance degradation and non-convergence. To address this challenge, we first identify the modules in the architecture design that lead to the severe reduction in spike firing, make targeted improvements, and propose Spike2Former architecture. Second, we propose normalized integer spiking neurons to solve the training stability problem of SNNs with complex architectures. We set a new state-of-the-art for SNNs in various semantic segmentation datasets, with a significant improvement of +12.7% mIoU and 5.0 efficiency on ADE20K, +14.3% mIoU and 5.2 efficiency on VOC2012, and +9.1% mIoU and 6.6 efficiency on CityScapes.
TexGaussian: Generating High-quality PBR Material via Octree-based 3D Gaussian Splatting
Nov 29, 2024
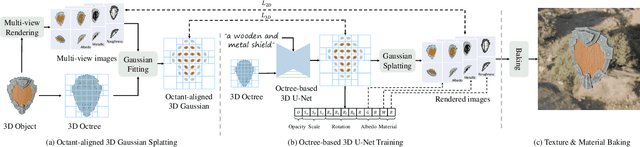


Physically Based Rendering (PBR) materials play a crucial role in modern graphics, enabling photorealistic rendering across diverse environment maps. Developing an effective and efficient algorithm that is capable of automatically generating high-quality PBR materials rather than RGB texture for 3D meshes can significantly streamline the 3D content creation. Most existing methods leverage pre-trained 2D diffusion models for multi-view image synthesis, which often leads to severe inconsistency between the generated textures and input 3D meshes. This paper presents TexGaussian, a novel method that uses octant-aligned 3D Gaussian Splatting for rapid PBR material generation. Specifically, we place each 3D Gaussian on the finest leaf node of the octree built from the input 3D mesh to render the multiview images not only for the albedo map but also for roughness and metallic. Moreover, our model is trained in a regression manner instead of diffusion denoising, capable of generating the PBR material for a 3D mesh in a single feed-forward process. Extensive experiments on publicly available benchmarks demonstrate that our method synthesizes more visually pleasing PBR materials and runs faster than previous methods in both unconditional and text-conditional scenarios, which exhibit better consistency with the given geometry. Our code and trained models are available at https://3d-aigc.github.io/TexGaussian.
Scaling Spike-driven Transformer with Efficient Spike Firing Approximation Training
Nov 25, 2024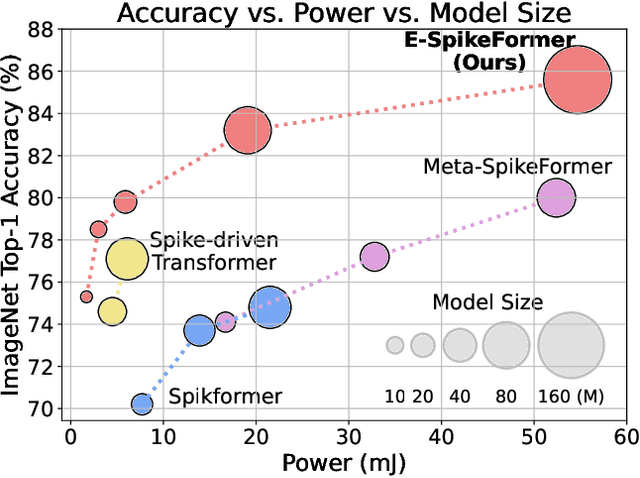
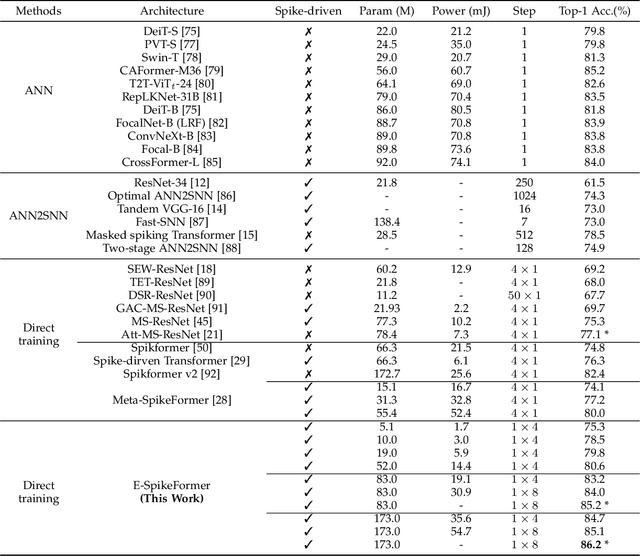
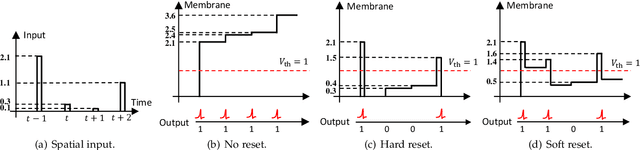
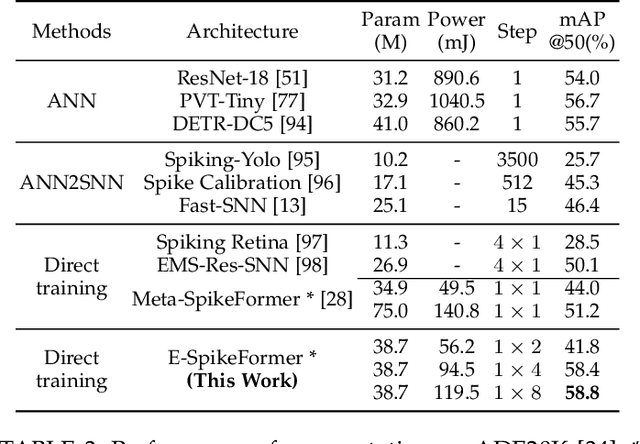
The ambition of brain-inspired Spiking Neural Networks (SNNs) is to become a low-power alternative to traditional Artificial Neural Networks (ANNs). This work addresses two major challenges in realizing this vision: the performance gap between SNNs and ANNs, and the high training costs of SNNs. We identify intrinsic flaws in spiking neurons caused by binary firing mechanisms and propose a Spike Firing Approximation (SFA) method using integer training and spike-driven inference. This optimizes the spike firing pattern of spiking neurons, enhancing efficient training, reducing power consumption, improving performance, enabling easier scaling, and better utilizing neuromorphic chips. We also develop an efficient spike-driven Transformer architecture and a spike-masked autoencoder to prevent performance degradation during SNN scaling. On ImageNet-1k, we achieve state-of-the-art top-1 accuracy of 78.5\%, 79.8\%, 84.0\%, and 86.2\% with models containing 10M, 19M, 83M, and 173M parameters, respectively. For instance, the 10M model outperforms the best existing SNN by 7.2\% on ImageNet, with training time acceleration and inference energy efficiency improved by 4.5$\times$ and 3.9$\times$, respectively. We validate the effectiveness and efficiency of the proposed method across various tasks, including object detection, semantic segmentation, and neuromorphic vision tasks. This work enables SNNs to match ANN performance while maintaining the low-power advantage, marking a significant step towards SNNs as a general visual backbone. Code is available at https://github.com/BICLab/Spike-Driven-Transformer-V3.
Inherent Redundancy in Spiking Neural Networks
Aug 16, 2023



Spiking Neural Networks (SNNs) are well known as a promising energy-efficient alternative to conventional artificial neural networks. Subject to the preconceived impression that SNNs are sparse firing, the analysis and optimization of inherent redundancy in SNNs have been largely overlooked, thus the potential advantages of spike-based neuromorphic computing in accuracy and energy efficiency are interfered. In this work, we pose and focus on three key questions regarding the inherent redundancy in SNNs. We argue that the redundancy is induced by the spatio-temporal invariance of SNNs, which enhances the efficiency of parameter utilization but also invites lots of noise spikes. Further, we analyze the effect of spatio-temporal invariance on the spatio-temporal dynamics and spike firing of SNNs. Then, motivated by these analyses, we propose an Advance Spatial Attention (ASA) module to harness SNNs' redundancy, which can adaptively optimize their membrane potential distribution by a pair of individual spatial attention sub-modules. In this way, noise spike features are accurately regulated. Experimental results demonstrate that the proposed method can significantly drop the spike firing with better performance than state-of-the-art SNN baselines. Our code is available in \url{https://github.com/BICLab/ASA-SNN}.
Spike-driven Transformer
Jul 04, 2023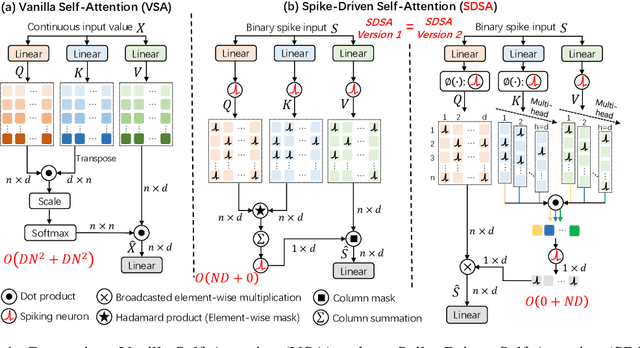
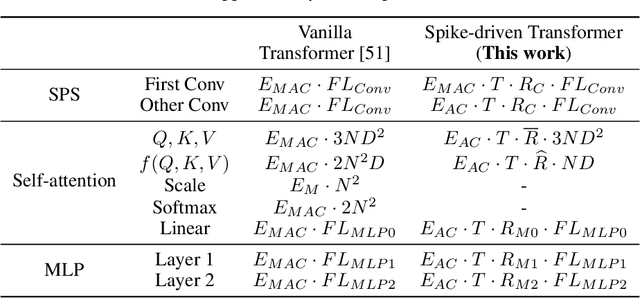
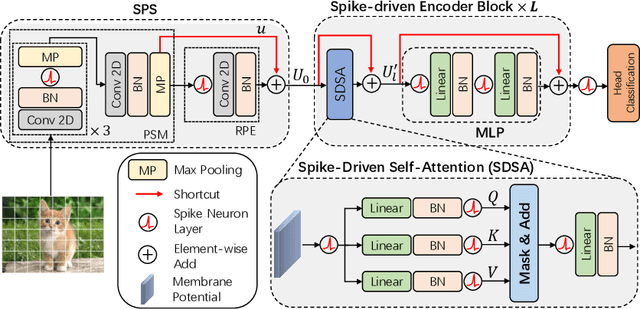

Spiking Neural Networks (SNNs) provide an energy-efficient deep learning option due to their unique spike-based event-driven (i.e., spike-driven) paradigm. In this paper, we incorporate the spike-driven paradigm into Transformer by the proposed Spike-driven Transformer with four unique properties: 1) Event-driven, no calculation is triggered when the input of Transformer is zero; 2) Binary spike communication, all matrix multiplications associated with the spike matrix can be transformed into sparse additions; 3) Self-attention with linear complexity at both token and channel dimensions; 4) The operations between spike-form Query, Key, and Value are mask and addition. Together, there are only sparse addition operations in the Spike-driven Transformer. To this end, we design a novel Spike-Driven Self-Attention (SDSA), which exploits only mask and addition operations without any multiplication, and thus having up to $87.2\times$ lower computation energy than vanilla self-attention. Especially in SDSA, the matrix multiplication between Query, Key, and Value is designed as the mask operation. In addition, we rearrange all residual connections in the vanilla Transformer before the activation functions to ensure that all neurons transmit binary spike signals. It is shown that the Spike-driven Transformer can achieve 77.1\% top-1 accuracy on ImageNet-1K, which is the state-of-the-art result in the SNN field. The source code is available at https://github.com/BICLab/Spike-Driven-Transformer.