 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpike-driven Transformer
Paper and Code
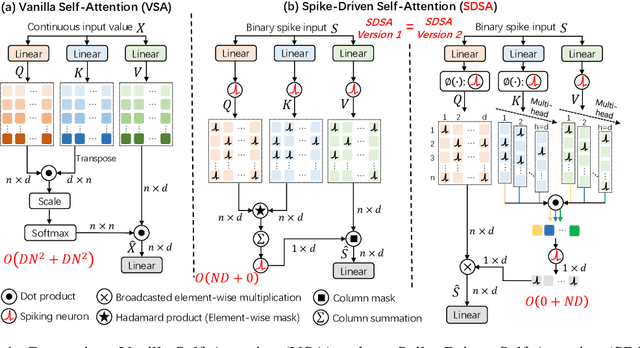
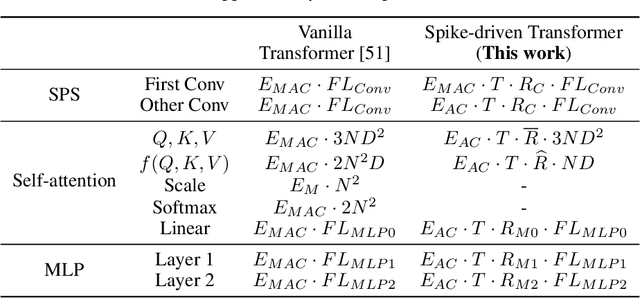
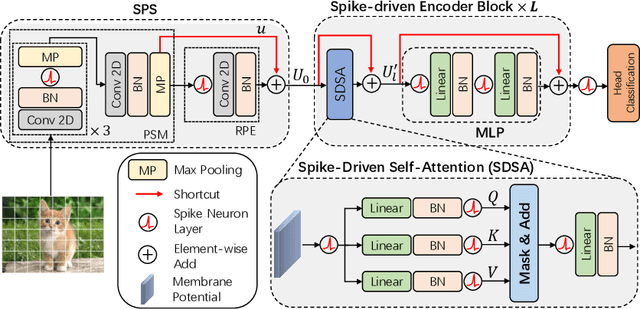

Spiking Neural Networks (SNNs) provide an energy-efficient deep learning option due to their unique spike-based event-driven (i.e., spike-driven) paradigm. In this paper, we incorporate the spike-driven paradigm into Transformer by the proposed Spike-driven Transformer with four unique properties: 1) Event-driven, no calculation is triggered when the input of Transformer is zero; 2) Binary spike communication, all matrix multiplications associated with the spike matrix can be transformed into sparse additions; 3) Self-attention with linear complexity at both token and channel dimensions; 4) The operations between spike-form Query, Key, and Value are mask and addition. Together, there are only sparse addition operations in the Spike-driven Transformer. To this end, we design a novel Spike-Driven Self-Attention (SDSA), which exploits only mask and addition operations without any multiplication, and thus having up to $87.2\times$ lower computation energy than vanilla self-attention. Especially in SDSA, the matrix multiplication between Query, Key, and Value is designed as the mask operation. In addition, we rearrange all residual connections in the vanilla Transformer before the activation functions to ensure that all neurons transmit binary spike signals. It is shown that the Spike-driven Transformer can achieve 77.1\% top-1 accuracy on ImageNet-1K, which is the state-of-the-art result in the SNN field. The source code is available at https://github.com/BICLab/Spike-Driven-Transformer.