 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Training in Spiking Neural Networks
Feb 01, 2026The bio-inspired integrate-fire-reset mechanism of spiking neurons constitutes the foundation for efficient processing in Spiking Neural Networks (SNNs). Recent progress in large models demands that spiking neurons support highly parallel computation to scale efficiently on modern GPUs. This work proposes a novel functional perspective that provides general guidance for designing parallel spiking neurons. We argue that the reset mechanism, which induces complex temporal dependencies and hinders parallel training, should be removed. However, any such modification should satisfy two principles: 1) preserving the functions of reset as a core biological mechanism; and 2) enabling parallel training without sacrificing the serial inference ability of spiking neurons, which underpins their efficiency at test time. To this end, we identify the functions of the reset and analyze how to reconcile parallel training with serial inference, upon which we propose a dynamic decay spiking neuron. We conduct comprehensive testing of our method in terms of: 1) Training efficiency and extrapolation capability. On 16k-length sequences, we achieve a 25.6x training speedup over the pioneering parallel spiking neuron, and our models trained on 2k-length can stably perform inference on sequences as long as 30k. 2) Generality. We demonstrate the consistent effectiveness of the proposed method across five task categories (image classification, neuromorphic event processing, time-series forecasting, language modeling, and reinforcement learning), three network architectures (spiking CNN/Transformer/SSMs), and two spike activation modes (spike/integer activation). 3) Energy consumption. The spiking firing of our neuron is lower than that of vanilla and existing parallel spiking neurons.
DeepPersona: A Generative Engine for Scaling Deep Synthetic Personas
Nov 11, 2025Simulating human profiles by instilling personas into large language models (LLMs) is rapidly transforming research in agentic behavioral simulation, LLM personalization, and human-AI alignment. However, most existing synthetic personas remain shallow and simplistic, capturing minimal attributes and failing to reflect the rich complexity and diversity of real human identities. We introduce DEEPPERSONA, a scalable generative engine for synthesizing narrative-complete synthetic personas through a two-stage, taxonomy-guided method. First, we algorithmically construct the largest-ever human-attribute taxonomy, comprising over hundreds of hierarchically organized attributes, by mining thousands of real user-ChatGPT conversations. Second, we progressively sample attributes from this taxonomy, conditionally generating coherent and realistic personas that average hundreds of structured attributes and roughly 1 MB of narrative text, two orders of magnitude deeper than prior works. Intrinsic evaluations confirm significant improvements in attribute diversity (32 percent higher coverage) and profile uniqueness (44 percent greater) compared to state-of-the-art baselines. Extrinsically, our personas enhance GPT-4.1-mini's personalized question answering accuracy by 11.6 percent on average across ten metrics and substantially narrow (by 31.7 percent) the gap between simulated LLM citizens and authentic human responses in social surveys. Our generated national citizens reduced the performance gap on the Big Five personality test by 17 percent relative to LLM-simulated citizens. DEEPPERSONA thus provides a rigorous, scalable, and privacy-free platform for high-fidelity human simulation and personalized AI research.
* 12 pages, 5 figures, accepted at LAW 2025 Workshop (NeurIPS 2025) Project page: https://deeppersona-ai.github.io/
SpikingBrain Technical Report: Spiking Brain-inspired Large Models
Sep 05, 2025Mainstream Transformer-based large language models face major efficiency bottlenecks: training computation scales quadratically with sequence length, and inference memory grows linearly, limiting long-context processing. Building large models on non-NVIDIA platforms also poses challenges for stable and efficient training. To address this, we introduce SpikingBrain, a family of brain-inspired models designed for efficient long-context training and inference. SpikingBrain leverages the MetaX GPU cluster and focuses on three aspects: (1) Model Architecture: linear and hybrid-linear attention architectures with adaptive spiking neurons; (2) Algorithmic Optimizations: an efficient, conversion-based training pipeline and a dedicated spike coding framework; (3) System Engineering: customized training frameworks, operator libraries, and parallelism strategies tailored to MetaX hardware. Using these techniques, we develop two models: SpikingBrain-7B, a linear LLM, and SpikingBrain-76B, a hybrid-linear MoE LLM. These models demonstrate the feasibility of large-scale LLM development on non-NVIDIA platforms. SpikingBrain achieves performance comparable to open-source Transformer baselines while using only about 150B tokens for continual pre-training. Our models significantly improve long-sequence training efficiency and deliver inference with (partially) constant memory and event-driven spiking behavior. For example, SpikingBrain-7B attains over 100x speedup in Time to First Token for 4M-token sequences. Training remains stable for weeks on hundreds of MetaX C550 GPUs, with the 7B model reaching a Model FLOPs Utilization of 23.4 percent. The proposed spiking scheme achieves 69.15 percent sparsity, enabling low-power operation. Overall, this work demonstrates the potential of brain-inspired mechanisms to drive the next generation of efficient and scalable large model design.
Integer Binary-Range Alignment Neuron for Spiking Neural Networks
Jun 06, 2025Spiking Neural Networks (SNNs) are noted for their brain-like computation and energy efficiency, but their performance lags behind Artificial Neural Networks (ANNs) in tasks like image classification and object detection due to the limited representational capacity. To address this, we propose a novel spiking neuron, Integer Binary-Range Alignment Leaky Integrate-and-Fire to exponentially expand the information expression capacity of spiking neurons with only a slight energy increase. This is achieved through Integer Binary Leaky Integrate-and-Fire and range alignment strategy. The Integer Binary Leaky Integrate-and-Fire allows integer value activation during training and maintains spike-driven dynamics with binary conversion expands virtual timesteps during inference. The range alignment strategy is designed to solve the spike activation limitation problem where neurons fail to activate high integer values. Experiments show our method outperforms previous SNNs, achieving 74.19% accuracy on ImageNet and 66.2% mAP@50 and 49.1% mAP@50:95 on COCO, surpassing previous bests with the same architecture by +3.45% and +1.6% and +1.8%, respectively. Notably, our SNNs match or exceed ANNs' performance with the same architecture, and the energy efficiency is improved by 6.3${\times}$.
Spike2Former: Efficient Spiking Transformer for High-performance Image Segmentation
Dec 19, 2024



Spiking Neural Networks (SNNs) have a low-power advantage but perform poorly in image segmentation tasks. The reason is that directly converting neural networks with complex architectural designs for segmentation tasks into spiking versions leads to performance degradation and non-convergence. To address this challenge, we first identify the modules in the architecture design that lead to the severe reduction in spike firing, make targeted improvements, and propose Spike2Former architecture. Second, we propose normalized integer spiking neurons to solve the training stability problem of SNNs with complex architectures. We set a new state-of-the-art for SNNs in various semantic segmentation datasets, with a significant improvement of +12.7% mIoU and 5.0 efficiency on ADE20K, +14.3% mIoU and 5.2 efficiency on VOC2012, and +9.1% mIoU and 6.6 efficiency on CityScapes.
Efficient 3D Recognition with Event-driven Spike Sparse Convolution
Dec 10, 2024



Spiking Neural Networks (SNNs) provide an energy-efficient way to extract 3D spatio-temporal features. Point clouds are sparse 3D spatial data, which suggests that SNNs should be well-suited for processing them. However, when applying SNNs to point clouds, they often exhibit limited performance and fewer application scenarios. We attribute this to inappropriate preprocessing and feature extraction methods. To address this issue, we first introduce the Spike Voxel Coding (SVC) scheme, which encodes the 3D point clouds into a sparse spike train space, reducing the storage requirements and saving time on point cloud preprocessing. Then, we propose a Spike Sparse Convolution (SSC) model for efficiently extracting 3D sparse point cloud features. Combining SVC and SSC, we design an efficient 3D SNN backbone (E-3DSNN), which is friendly with neuromorphic hardware. For instance, SSC can be implemented on neuromorphic chips with only minor modifications to the addressing function of vanilla spike convolution. Experiments on ModelNet40, KITTI, and Semantic KITTI datasets demonstrate that E-3DSNN achieves state-of-the-art (SOTA) results with remarkable efficiency. Notably, our E-3DSNN (1.87M) obtained 91.7\% top-1 accuracy on ModelNet40, surpassing the current best SNN baselines (14.3M) by 3.0\%. To our best knowledge, it is the first direct training 3D SNN backbone that can simultaneously handle various 3D computer vision tasks (e.g., classification, detection, and segmentation) with an event-driven nature. Code is available: https://github.com/bollossom/E-3DSNN/.
Scaling Spike-driven Transformer with Efficient Spike Firing Approximation Training
Nov 25, 2024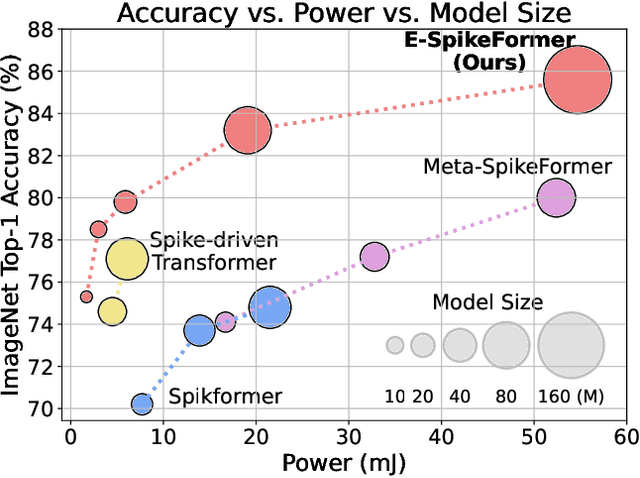
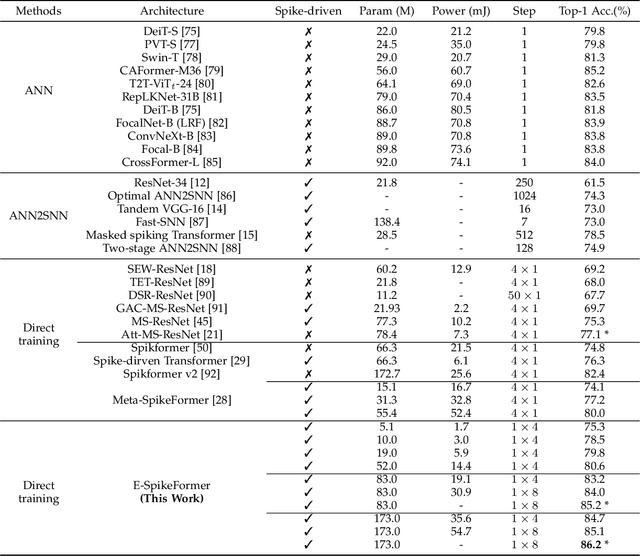
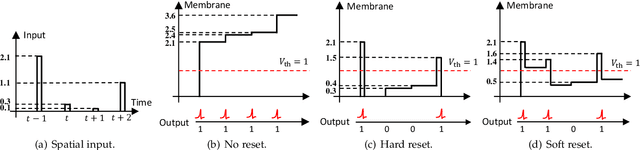
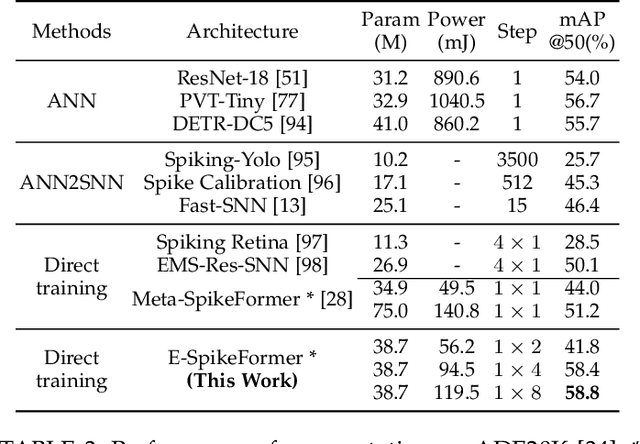
The ambition of brain-inspired Spiking Neural Networks (SNNs) is to become a low-power alternative to traditional Artificial Neural Networks (ANNs). This work addresses two major challenges in realizing this vision: the performance gap between SNNs and ANNs, and the high training costs of SNNs. We identify intrinsic flaws in spiking neurons caused by binary firing mechanisms and propose a Spike Firing Approximation (SFA) method using integer training and spike-driven inference. This optimizes the spike firing pattern of spiking neurons, enhancing efficient training, reducing power consumption, improving performance, enabling easier scaling, and better utilizing neuromorphic chips. We also develop an efficient spike-driven Transformer architecture and a spike-masked autoencoder to prevent performance degradation during SNN scaling. On ImageNet-1k, we achieve state-of-the-art top-1 accuracy of 78.5\%, 79.8\%, 84.0\%, and 86.2\% with models containing 10M, 19M, 83M, and 173M parameters, respectively. For instance, the 10M model outperforms the best existing SNN by 7.2\% on ImageNet, with training time acceleration and inference energy efficiency improved by 4.5$\times$ and 3.9$\times$, respectively. We validate the effectiveness and efficiency of the proposed method across various tasks, including object detection, semantic segmentation, and neuromorphic vision tasks. This work enables SNNs to match ANN performance while maintaining the low-power advantage, marking a significant step towards SNNs as a general visual backbone. Code is available at https://github.com/BICLab/Spike-Driven-Transformer-V3.
MetaLA: Unified Optimal Linear Approximation to Softmax Attention Map
Nov 16, 2024



Various linear complexity models, such as Linear Transformer (LinFormer), State Space Model (SSM), and Linear RNN (LinRNN), have been proposed to replace the conventional softmax attention in Transformer structures. However, the optimal design of these linear models is still an open question. In this work, we attempt to answer this question by finding the best linear approximation to softmax attention from a theoretical perspective. We start by unifying existing linear complexity models as the linear attention form and then identify three conditions for the optimal linear attention design: 1) Dynamic memory ability; 2) Static approximation ability; 3) Least parameter approximation. We find that none of the current linear models meet all three conditions, resulting in suboptimal performance. Instead, we propose Meta Linear Attention (MetaLA) as a solution that satisfies these conditions. Our experiments on Multi-Query Associative Recall (MQAR) task, language modeling, image classification, and Long-Range Arena (LRA) benchmark demonstrate that MetaLA is more effective than the existing linear models.
Integer-Valued Training and Spike-Driven Inference Spiking Neural Network for High-performance and Energy-efficient Object Detection
Jul 31, 2024



Brain-inspired Spiking Neural Networks (SNNs) have bio-plausibility and low-power advantages over Artificial Neural Networks (ANNs). Applications of SNNs are currently limited to simple classification tasks because of their poor performance. In this work, we focus on bridging the performance gap between ANNs and SNNs on object detection. Our design revolves around network architecture and spiking neuron. First, the overly complex module design causes spike degradation when the YOLO series is converted to the corresponding spiking version. We design a SpikeYOLO architecture to solve this problem by simplifying the vanilla YOLO and incorporating meta SNN blocks. Second, object detection is more sensitive to quantization errors in the conversion of membrane potentials into binary spikes by spiking neurons. To address this challenge, we design a new spiking neuron that activates Integer values during training while maintaining spike-driven by extending virtual timesteps during inference. The proposed method is validated on both static and neuromorphic object detection datasets. On the static COCO dataset, we obtain 66.2% mAP@50 and 48.9% mAP@50:95, which is +15.0% and +18.7% higher than the prior state-of-the-art SNN, respectively. On the neuromorphic Gen1 dataset, we achieve 67.2% mAP@50, which is +2.5% greater than the ANN with equivalent architecture, and the energy efficiency is improved by 5.7*. Code: https://github.com/BICLab/SpikeYOLO
RSC-SNN: Exploring the Trade-off Between Adversarial Robustness and Accuracy in Spiking Neural Networks via Randomized Smoothing Coding
Jul 29, 2024



Spiking Neural Networks (SNNs) have received widespread attention due to their unique neuronal dynamics and low-power nature. Previous research empirically shows that SNNs with Poisson coding are more robust than Artificial Neural Networks (ANNs) on small-scale datasets. However, it is still unclear in theory how the adversarial robustness of SNNs is derived, and whether SNNs can still maintain its adversarial robustness advantage on large-scale dataset tasks. This work theoretically demonstrates that SNN's inherent adversarial robustness stems from its Poisson coding. We reveal the conceptual equivalence of Poisson coding and randomized smoothing in defense strategies, and analyze in depth the trade-off between accuracy and adversarial robustness in SNNs via the proposed Randomized Smoothing Coding (RSC) method. Experiments demonstrate that the proposed RSC-SNNs show remarkable adversarial robustness, surpassing ANNs and achieving state-of-the-art robustness results on large-scale dataset ImageNet. Our open-source implementation code is available at this https URL: https://github.com/KemingWu/RSC-SNN.