 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteger Binary-Range Alignment Neuron for Spiking Neural Networks
Jun 06, 2025Spiking Neural Networks (SNNs) are noted for their brain-like computation and energy efficiency, but their performance lags behind Artificial Neural Networks (ANNs) in tasks like image classification and object detection due to the limited representational capacity. To address this, we propose a novel spiking neuron, Integer Binary-Range Alignment Leaky Integrate-and-Fire to exponentially expand the information expression capacity of spiking neurons with only a slight energy increase. This is achieved through Integer Binary Leaky Integrate-and-Fire and range alignment strategy. The Integer Binary Leaky Integrate-and-Fire allows integer value activation during training and maintains spike-driven dynamics with binary conversion expands virtual timesteps during inference. The range alignment strategy is designed to solve the spike activation limitation problem where neurons fail to activate high integer values. Experiments show our method outperforms previous SNNs, achieving 74.19% accuracy on ImageNet and 66.2% mAP@50 and 49.1% mAP@50:95 on COCO, surpassing previous bests with the same architecture by +3.45% and +1.6% and +1.8%, respectively. Notably, our SNNs match or exceed ANNs' performance with the same architecture, and the energy efficiency is improved by 6.3${\times}$.
Interactive Gadolinium-Free MRI Synthesis: A Transformer with Localization Prompt Learning
Mar 03, 2025Contrast-enhanced magnetic resonance imaging (CE-MRI) is crucial for tumor detection and diagnosis, but the use of gadolinium-based contrast agents (GBCAs) in clinical settings raises safety concerns due to potential health risks. To circumvent these issues while preserving diagnostic accuracy, we propose a novel Transformer with Localization Prompts (TLP) framework for synthesizing CE-MRI from non-contrast MR images. Our architecture introduces three key innovations: a hierarchical backbone that uses efficient Transformer to process multi-scale features; a multi-stage fusion system consisting of Local and Global Fusion modules that hierarchically integrate complementary information via spatial attention operations and cross-attention mechanisms, respectively; and a Fuzzy Prompt Generation (FPG) module that enhances the TLP model's generalization by emulating radiologists' manual annotation through stochastic feature perturbation. The framework uniquely enables interactive clinical integration by allowing radiologists to input diagnostic prompts during inference, synergizing artificial intelligence with medical expertise. This research establishes a new paradigm for contrast-free MRI synthesis while addressing critical clinical needs for safer diagnostic procedures. Codes are available at https://github.com/ChanghuiSu/TLP.
Realistic Restorer: artifact-free flow restorer(AF2R) for MRI motion artifact removal
Jun 19, 2023Motion artifact is a major challenge in magnetic resonance imaging (MRI) that severely degrades image quality, reduces examination efficiency, and makes accurate diagnosis difficult. However, previous methods often relied on implicit models for artifact correction, resulting in biases in modeling the artifact formation mechanism and characterizing the relationship between artifact information and anatomical details. These limitations have hindered the ability to obtain high-quality MR images. In this work, we incorporate the artifact generation mechanism to reestablish the relationship between artifacts and anatomical content in the image domain, highlighting the superiority of explicit models over implicit models in medical problems. Based on this, we propose a novel end-to-end image domain model called AF2R, which addresses this problem using conditional normalization flow. Specifically, we first design a feature encoder to extract anatomical features from images with motion artifacts. Then, through a series of reversible transformations using the feature-to-image flow module, we progressively obtain MR images unaffected by motion artifacts. Experimental results on simulated and real datasets demonstrate that our method achieves better performance in both quantitative and qualitative results, preserving better anatomical details.
RetinexFlow for CT metal artifact reduction
Jun 18, 2023



Metal artifacts is a major challenge in computed tomography (CT) imaging, significantly degrading image quality and making accurate diagnosis difficult. However, previous methods either require prior knowledge of the location of metal implants, or have modeling deviations with the mechanism of artifact formation, which limits the ability to obtain high-quality CT images. In this work, we formulate metal artifacts reduction problem as a combination of decomposition and completion tasks. And we propose RetinexFlow, which is a novel end-to-end image domain model based on Retinex theory and conditional normalizing flow, to solve it. Specifically, we first design a feature decomposition encoder for decomposing the metal implant component and inherent component, and extracting the inherent feature. Then, it uses a feature-to-image flow module to complete the metal artifact-free CT image step by step through a series of invertible transformations. These designs are incorporated in our model with a coarse-to-fine strategy, enabling it to achieve superior performance. The experimental results on on simulation and clinical datasets show our method achieves better quantitative and qualitative results, exhibiting better visual performance in artifact removal and image fidelity
Active CT Reconstruction with a Learned Sampling Policy
Nov 03, 2022



Computed tomography (CT) is a widely-used imaging technology that assists clinical decision-making with high-quality human body representations. To reduce the radiation dose posed by CT, sparse-view and limited-angle CT are developed with preserved image quality. However, these methods are still stuck with a fixed or uniform sampling strategy, which inhibits the possibility of acquiring a better image with an even reduced dose. In this paper, we explore this possibility via learning an active sampling policy that optimizes the sampling positions for patient-specific, high-quality reconstruction. To this end, we design an \textit{intelligent agent} for active recommendation of sampling positions based on on-the-fly reconstruction with obtained sinograms in a progressive fashion. With such a design, we achieve better performances on the NIH-AAPM dataset over popular uniform sampling, especially when the number of views is small. Finally, such a design also enables RoI-aware reconstruction with improved reconstruction quality within regions of interest (RoI's) that are clinically important. Experiments on the VerSe dataset demonstrate this ability of our sampling policy, which is difficult to achieve based on uniform sampling.
DuDoTrans: Dual-Domain Transformer Provides More Attention for Sinogram Restoration in Sparse-View CT Reconstruction
Nov 25, 2021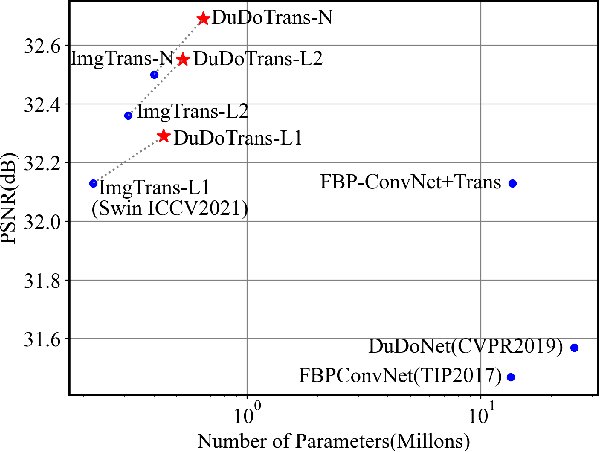



While Computed Tomography (CT) reconstruction from X-ray sinograms is necessary for clinical diagnosis, iodine radiation in the imaging process induces irreversible injury, thereby driving researchers to study sparse-view CT reconstruction, that is, recovering a high-quality CT image from a sparse set of sinogram views. Iterative models are proposed to alleviate the appeared artifacts in sparse-view CT images, but the computation cost is too expensive. Then deep-learning-based methods have gained prevalence due to the excellent performances and lower computation. However, these methods ignore the mismatch between the CNN's \textbf{local} feature extraction capability and the sinogram's \textbf{global} characteristics. To overcome the problem, we propose \textbf{Du}al-\textbf{Do}main \textbf{Trans}former (\textbf{DuDoTrans}) to simultaneously restore informative sinograms via the long-range dependency modeling capability of Transformer and reconstruct CT image with both the enhanced and raw sinograms. With such a novel design, reconstruction performance on the NIH-AAPM dataset and COVID-19 dataset experimentally confirms the effectiveness and generalizability of DuDoTrans with fewer involved parameters. Extensive experiments also demonstrate its robustness with different noise-level scenarios for sparse-view CT reconstruction. The code and models are publicly available at https://github.com/DuDoTrans/CODE
Generalizable Limited-Angle CT Reconstruction via Sinogram Extrapolation
Mar 15, 2021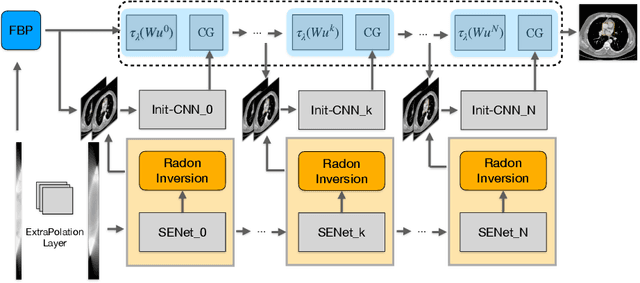


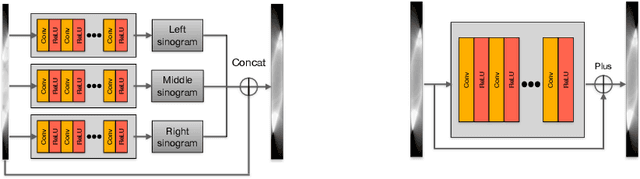
Computed tomography (CT) reconstruction from X-ray projections acquired within a limited angle range is challenging, especially when the angle range is extremely small. Both analytical and iterative models need more projections for effective modeling. Deep learning methods have gained prevalence due to their excellent reconstruction performances, but such success is mainly limited within the same dataset and does not generalize across datasets with different distributions. Hereby we propose ExtraPolationNetwork for limited-angle CT reconstruction via the introduction of a sinogram extrapolation module, which is theoretically justified. The module complements extra sinogram information and boots model generalizability. Extensive experimental results show that our reconstruction model achieves state-of-the-art performance on NIH-AAPM dataset, similar to existing approaches. More importantly, we show that using such a sinogram extrapolation module significantly improves the generalization capability of the model on unseen datasets (e.g., COVID-19 and LIDC datasets) when compared to existing approaches.
Label-Removed Generative Adversarial Networks Incorporating with K-Means
Feb 19, 2019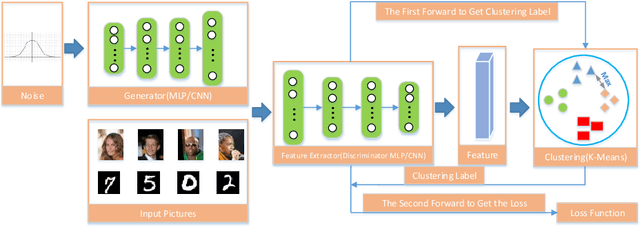
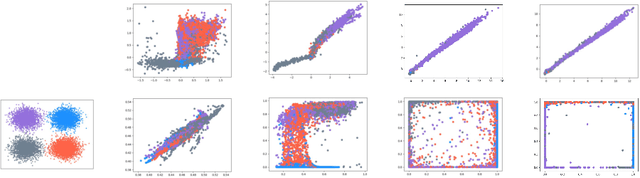

Generative Adversarial Networks (GANs) have achieved great success in generating realistic images. Most of these are conditional models, although acquisition of class labels is expensive and time-consuming in practice. To reduce the dependence on labeled data, we propose an un-conditional generative adversarial model, called K-Means-GAN (KM-GAN), which incorporates the idea of updating centers in K-Means into GANs. Specifically, we redesign the framework of GANs by applying K-Means on the features extracted from the discriminator. With obtained labels from K-Means, we propose new objective functions from the perspective of deep metric learning (DML). Distinct from previous works, the discriminator is treated as a feature extractor rather than a classifier in KM-GAN, meanwhile utilization of K-Means makes features of the discriminator more representative. Experiments are conducted on various datasets, such as MNIST, Fashion-10, CIFAR-10 and CelebA, and show that the quality of samples generated by KM-GAN is comparable to some conditional generative adversarial models.