 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegRap2025: A Benchmark of Gross Tumor Volume and Lymph Node Clinical Target Volume Segmentation for Radiotherapy Planning of Nasopharyngeal Carcinoma
Jan 28, 2026Accurate delineation of Gross Tumor Volume (GTV), Lymph Node Clinical Target Volume (LN CTV), and Organ-at-Risk (OAR) from Computed Tomography (CT) scans is essential for precise radiotherapy planning in Nasopharyngeal Carcinoma (NPC). Building upon SegRap2023, which focused on OAR and GTV segmentation using single-center paired non-contrast CT (ncCT) and contrast-enhanced CT (ceCT) scans, the SegRap2025 challenge aims to enhance the generalizability and robustness of segmentation models across imaging centers and modalities. SegRap2025 comprises two tasks: Task01 addresses GTV segmentation using paired CT from the SegRap2023 dataset, with an additional external testing set to evaluate cross-center generalization, and Task02 focuses on LN CTV segmentation using multi-center training data and an unseen external testing set, where each case contains paired CT scans or a single modality, emphasizing both cross-center and cross-modality robustness. This paper presents the challenge setup and provides a comprehensive analysis of the solutions submitted by ten participating teams. For GTV segmentation task, the top-performing models achieved average Dice Similarity Coefficient (DSC) of 74.61% and 56.79% on the internal and external testing cohorts, respectively. For LN CTV segmentation task, the highest average DSC values reached 60.24%, 60.50%, and 57.23% on paired CT, ceCT-only, and ncCT-only subsets, respectively. SegRap2025 establishes a large-scale multi-center, multi-modality benchmark for evaluating the generalization and robustness in radiotherapy target segmentation, providing valuable insights toward clinically applicable automated radiotherapy planning systems. The benchmark is available at: https://hilab-git.github.io/SegRap2025_Challenge.
Unified Start, Personalized End: Progressive Pruning for Efficient 3D Medical Image Segmentation
Sep 11, 20253D medical image segmentation often faces heavy resource and time consumption, limiting its scalability and rapid deployment in clinical environments. Existing efficient segmentation models are typically static and manually designed prior to training, which restricts their adaptability across diverse tasks and makes it difficult to balance performance with resource efficiency. In this paper, we propose PSP-Seg, a progressive pruning framework that enables dynamic and efficient 3D segmentation. PSP-Seg begins with a redundant model and iteratively prunes redundant modules through a combination of block-wise pruning and a functional decoupling loss. We evaluate PSP-Seg on five public datasets, benchmarking it against seven state-of-the-art models and six efficient segmentation models. Results demonstrate that the lightweight variant, PSP-Seg-S, achieves performance on par with nnU-Net while reducing GPU memory usage by 42-45%, training time by 29-48%, and parameter number by 83-87% across all datasets. These findings underscore PSP-Seg's potential as a cost-effective yet high-performing alternative for widespread clinical application.
Adaptive Decision Boundary for Few-Shot Class-Incremental Learning
Apr 15, 2025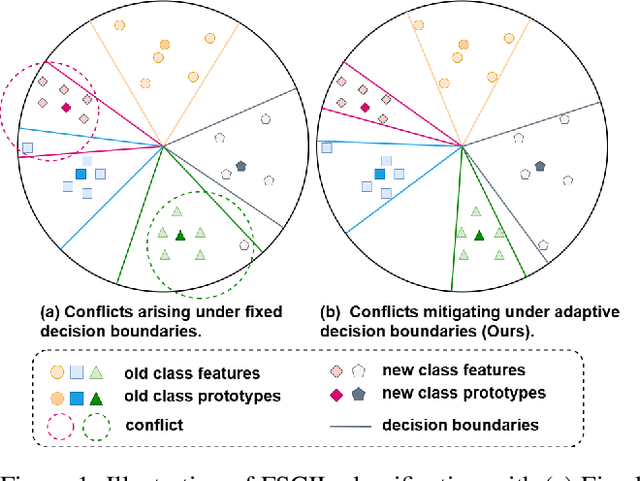
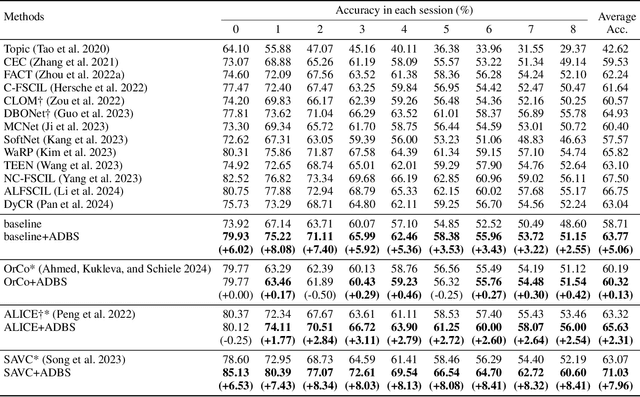
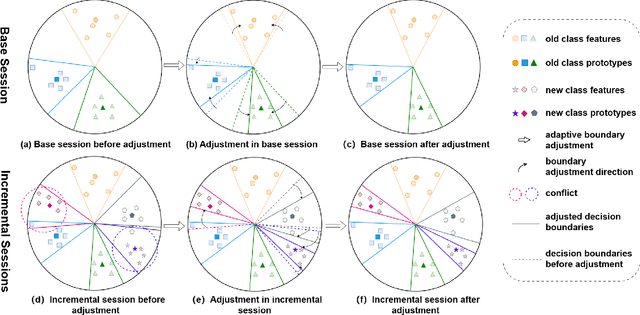
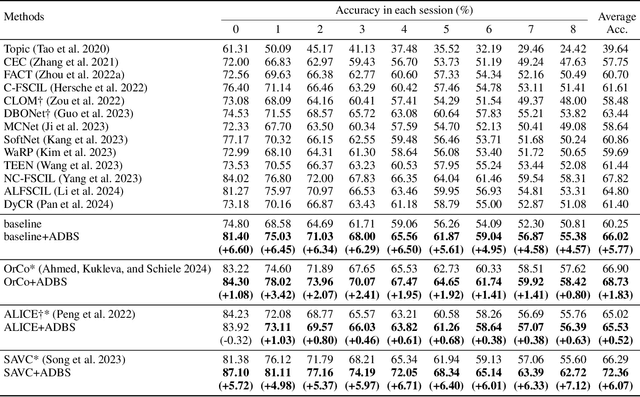
Few-Shot Class-Incremental Learning (FSCIL) aims to continuously learn new classes from a limited set of training samples without forgetting knowledge of previously learned classes. Conventional FSCIL methods typically build a robust feature extractor during the base training session with abundant training samples and subsequently freeze this extractor, only fine-tuning the classifier in subsequent incremental phases. However, current strategies primarily focus on preventing catastrophic forgetting, considering only the relationship between novel and base classes, without paying attention to the specific decision spaces of each class. To address this challenge, we propose a plug-and-play Adaptive Decision Boundary Strategy (ADBS), which is compatible with most FSCIL methods. Specifically, we assign a specific decision boundary to each class and adaptively adjust these boundaries during training to optimally refine the decision spaces for the classes in each session. Furthermore, to amplify the distinctiveness between classes, we employ a novel inter-class constraint loss that optimizes the decision boundaries and prototypes for each class. Extensive experiments on three benchmarks, namely CIFAR100, miniImageNet, and CUB200, demonstrate that incorporating our ADBS method with existing FSCIL techniques significantly improves performance, achieving overall state-of-the-art results.
Interactive Gadolinium-Free MRI Synthesis: A Transformer with Localization Prompt Learning
Mar 03, 2025Contrast-enhanced magnetic resonance imaging (CE-MRI) is crucial for tumor detection and diagnosis, but the use of gadolinium-based contrast agents (GBCAs) in clinical settings raises safety concerns due to potential health risks. To circumvent these issues while preserving diagnostic accuracy, we propose a novel Transformer with Localization Prompts (TLP) framework for synthesizing CE-MRI from non-contrast MR images. Our architecture introduces three key innovations: a hierarchical backbone that uses efficient Transformer to process multi-scale features; a multi-stage fusion system consisting of Local and Global Fusion modules that hierarchically integrate complementary information via spatial attention operations and cross-attention mechanisms, respectively; and a Fuzzy Prompt Generation (FPG) module that enhances the TLP model's generalization by emulating radiologists' manual annotation through stochastic feature perturbation. The framework uniquely enables interactive clinical integration by allowing radiologists to input diagnostic prompts during inference, synergizing artificial intelligence with medical expertise. This research establishes a new paradigm for contrast-free MRI synthesis while addressing critical clinical needs for safer diagnostic procedures. Codes are available at https://github.com/ChanghuiSu/TLP.
Interactive Model with Structural Loss for Language-based Abductive Reasoning
Dec 01, 2021

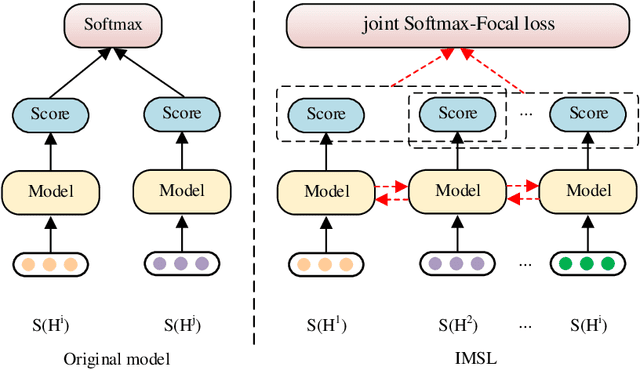

The abductive natural language inference task ($\alpha$NLI) is proposed to infer the most plausible explanation between the cause and the event. In the $\alpha$NLI task, two observations are given, and the most plausible hypothesis is asked to pick out from the candidates. Existing methods model the relation between each candidate hypothesis separately and penalize the inference network uniformly. In this paper, we argue that it is unnecessary to distinguish the reasoning abilities among correct hypotheses; and similarly, all wrong hypotheses contribute the same when explaining the reasons of the observations. Therefore, we propose to group instead of ranking the hypotheses and design a structural loss called ``joint softmax focal loss'' in this paper. Based on the observation that the hypotheses are generally semantically related, we have designed a novel interactive language model aiming at exploiting the rich interaction among competing hypotheses. We name this new model for $\alpha$NLI: Interactive Model with Structural Loss (IMSL). The experimental results show that our IMSL has achieved the highest performance on the RoBERTa-large pretrained model, with ACC and AUC results increased by about 1\% and 5\% respectively.
Dynamic Anchor Learning for Arbitrary-Oriented Object Detection
Dec 15, 2020
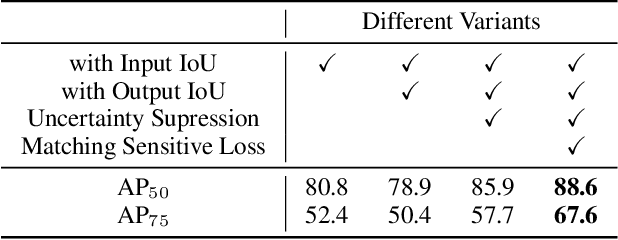
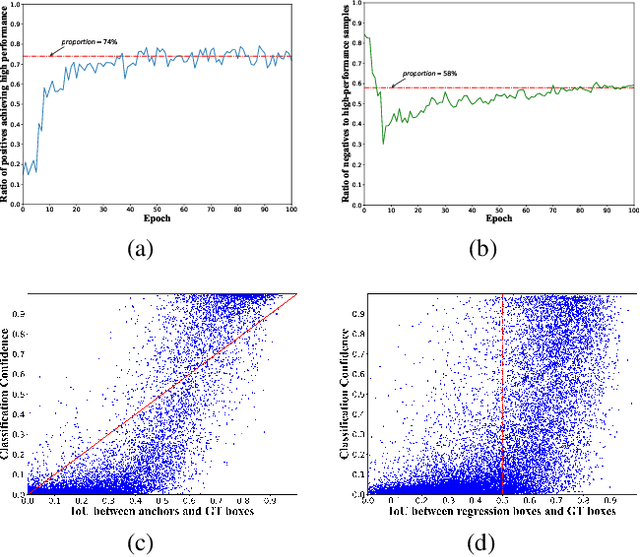
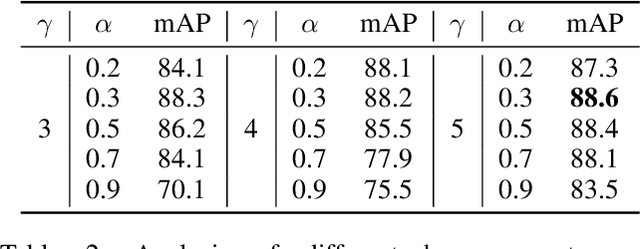
Arbitrary-oriented objects widely appear in natural scenes, aerial photographs, remote sensing images, etc., thus arbitrary-oriented object detection has received considerable attention. Many current rotation detectors use plenty of anchors with different orientations to achieve spatial alignment with ground truth boxes, then Intersection-over-Union (IoU) is applied to sample the positive and negative candidates for training. However, we observe that the selected positive anchors cannot always ensure accurate detections after regression, while some negative samples can achieve accurate localization. It indicates that the quality assessment of anchors through IoU is not appropriate, and this further lead to inconsistency between classification confidence and localization accuracy. In this paper, we propose a dynamic anchor learning (DAL) method, which utilizes the newly defined matching degree to comprehensively evaluate the localization potential of the anchors and carry out a more efficient label assignment process. In this way, the detector can dynamically select high-quality anchors to achieve accurate object detection, and the divergence between classification and regression will be alleviated. With the newly introduced DAL, we achieve superior detection performance for arbitrary-oriented objects with only a few horizontal preset anchors. Experimental results on three remote sensing datasets HRSC2016, DOTA, UCAS-AOD as well as a scene text dataset ICDAR 2015 show that our method achieves substantial improvement compared with the baseline model. Besides, our approach is also universal for object detection using horizontal bound box. The code and models are available at https://github.com/ming71/DAL.
A Novel CNN-based Method for Accurate Ship Detection in HR Optical Remote Sensing Images via Rotated Bounding Box
May 08, 2020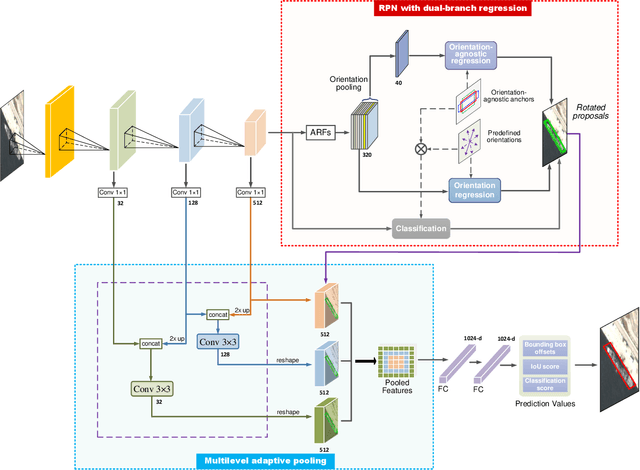

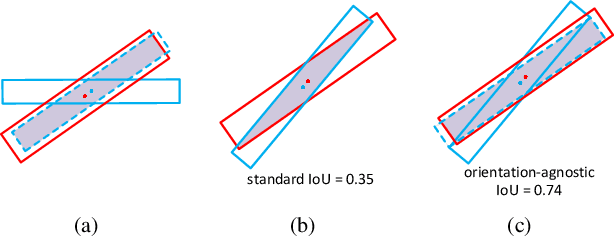
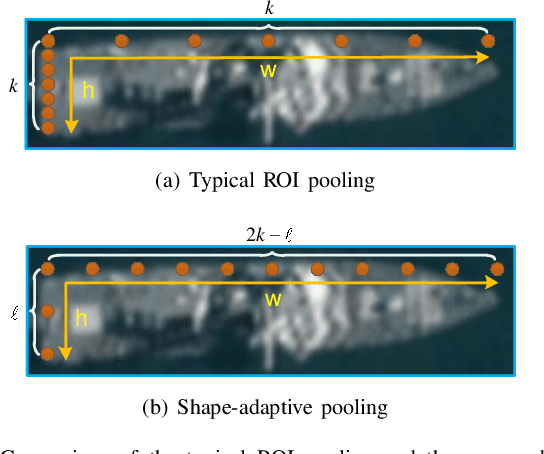
Currently, reliable and accurate ship detection in optical remote sensing images is still challenging. Even the state-of-the-art convolutional neural network (CNN) based methods cannot obtain very satisfactory results. To more accurately locate the ships in diverse orientations, some recent methods conduct the detection via the rotated bounding box. However, it further increases the difficulty of detection, because an additional variable of ship orientation must be accurately predicted in the algorithm. In this paper, a novel CNN-based ship detection method is proposed, by overcoming some common deficiencies of current CNN-based methods in ship detection. Specifically, to generate rotated region proposals, current methods have to predefine multi-oriented anchors, and predict all unknown variables together in one regression process, limiting the quality of overall prediction. By contrast, we are able to predict the orientation and other variables independently, and yet more effectively, with a novel dual-branch regression network, based on the observation that the ship targets are nearly rotation-invariant in remote sensing images. Next, a shape-adaptive pooling method is proposed, to overcome the limitation of typical regular ROI-pooling in extracting the features of the ships with various aspect ratios. Furthermore, we propose to incorporate multilevel features via the spatially-variant adaptive pooling. This novel approach, called multilevel adaptive pooling, leads to a compact feature representation more qualified for the simultaneous ship classification and localization. Finally, detailed ablation study performed on the proposed approaches is provided, along with some useful insights. Experimental results demonstrate the great superiority of the proposed method in ship detection.
Efficient Background Modeling Based on Sparse Representation and Outlier Iterative Removal
Jan 05, 2016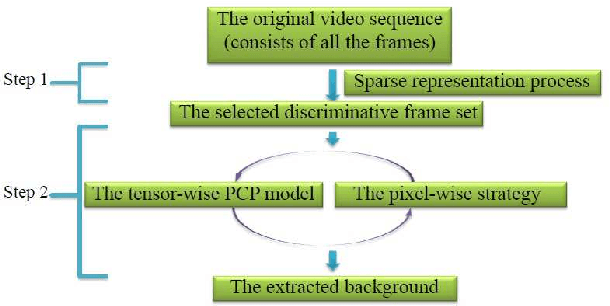


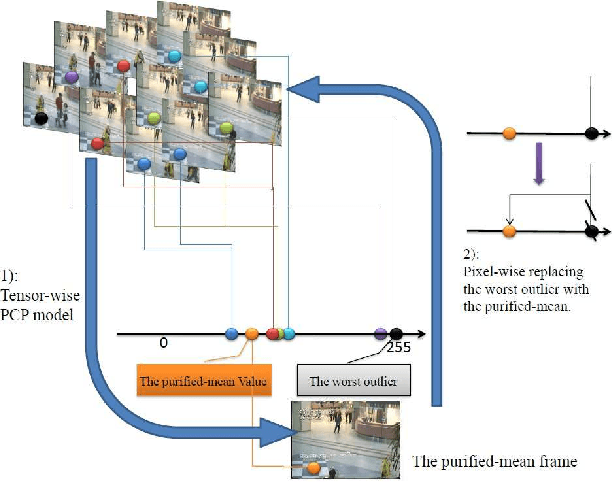
Background modeling is a critical component for various vision-based applications. Most traditional methods tend to be inefficient when solving large-scale problems. In this paper, we introduce sparse representation into the task of large scale stable background modeling, and reduce the video size by exploring its 'discriminative' frames. A cyclic iteration process is then proposed to extract the background from the discriminative frame set. The two parts combine to form our Sparse Outlier Iterative Removal (SOIR) algorithm. The algorithm operates in tensor space to obey the natural data structure of videos. Experimental results show that a few discriminative frames determine the performance of the background extraction. Further, SOIR can achieve high accuracy and high speed simultaneously when dealing with real video sequences. Thus, SOIR has an advantage in solving large-scale tasks.