 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCAViT: Compact Vision Transformer with Robust Global Coordination
Aug 07, 2025In recent years, large-scale visual backbones have demonstrated remarkable capabilities in learning general-purpose features from images via extensive pre-training. Concurrently, many efficient architectures have emerged that have performance comparable to that of larger models on in-domain benchmarks. However, we observe that for smaller models, the performance drop on out-of-distribution (OOD) data is disproportionately larger, indicating a deficiency in the generalization performance of existing efficient models. To address this, we identify key architectural bottlenecks and inappropriate design choices that contribute to this issue, retaining robustness for smaller models. To restore the global field of pure window attention, we further introduce a Coordinator-patch Cross Attention (CoCA) mechanism, featuring dynamic, domain-aware global tokens that enhance local-global feature modeling and adaptively capture robust patterns across domains with minimal computational overhead. Integrating these advancements, we present CoCAViT, a novel visual backbone designed for robust real-time visual representation. Extensive experiments empirically validate our design. At a resolution of 224*224, CoCAViT-28M achieves 84.0% top-1 accuracy on ImageNet-1K, with significant gains on multiple OOD benchmarks, compared to competing models. It also attains 52.2 mAP on COCO object detection and 51.3 mIOU on ADE20K semantic segmentation, while maintaining low latency.
Infrared and visible Image Fusion with Language-driven Loss in CLIP Embedding Space
Feb 26, 2024Infrared-visible image fusion (IVIF) has attracted much attention owing to the highly-complementary properties of the two image modalities. Due to the lack of ground-truth fused images, the fusion output of current deep-learning based methods heavily depends on the loss functions defined mathematically. As it is hard to well mathematically define the fused image without ground truth, the performance of existing fusion methods is limited. In this paper, we first propose to use natural language to express the objective of IVIF, which can avoid the explicit mathematical modeling of fusion output in current losses, and make full use of the advantage of language expression to improve the fusion performance. For this purpose, we present a comprehensive language-expressed fusion objective, and encode relevant texts into the multi-modal embedding space using CLIP. A language-driven fusion model is then constructed in the embedding space, by establishing the relationship among the embedded vectors to represent the fusion objective and input image modalities. Finally, a language-driven loss is derived to make the actual IVIF aligned with the embedded language-driven fusion model via supervised training. Experiments show that our method can obtain much better fusion results than existing techniques.
Semantic Object-level Modeling for Robust Visual Camera Relocalization
Feb 10, 2024



Visual relocalization is crucial for autonomous visual localization and navigation of mobile robotics. Due to the improvement of CNN-based object detection algorithm, the robustness of visual relocalization is greatly enhanced especially in viewpoints where classical methods fail. However, ellipsoids (quadrics) generated by axis-aligned object detection may limit the accuracy of the object-level representation and degenerate the performance of visual relocalization system. In this paper, we propose a novel method of automatic object-level voxel modeling for accurate ellipsoidal representations of objects. As for visual relocalization, we design a better pose optimization strategy for camera pose recovery, to fully utilize the projection characteristics of 2D fitted ellipses and the 3D accurate ellipsoids. All of these modules are entirely intergrated into visual SLAM system. Experimental results show that our semantic object-level mapping and object-based visual relocalization methods significantly enhance the performance of visual relocalization in terms of robustness to new viewpoints.
Optimization for Oriented Object Detection via Representation Invariance Loss
Mar 22, 2021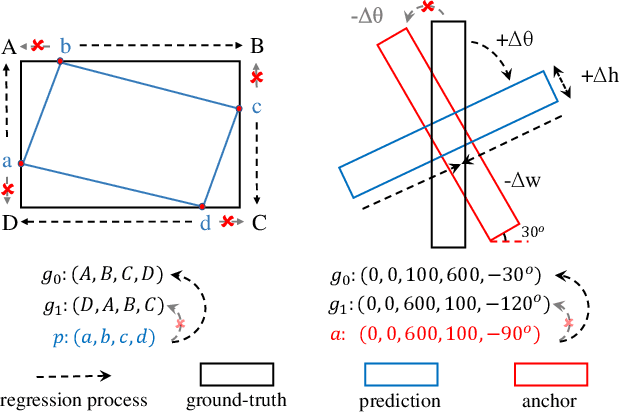
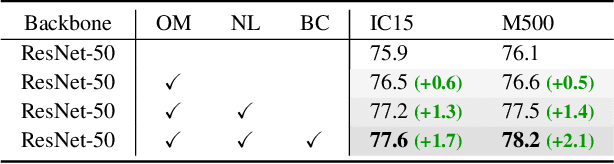
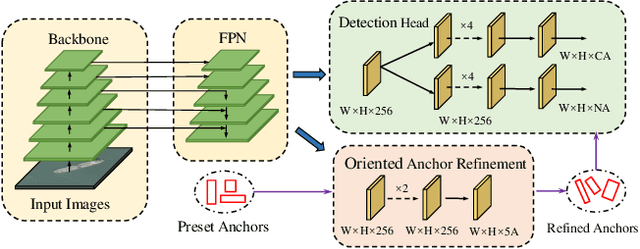
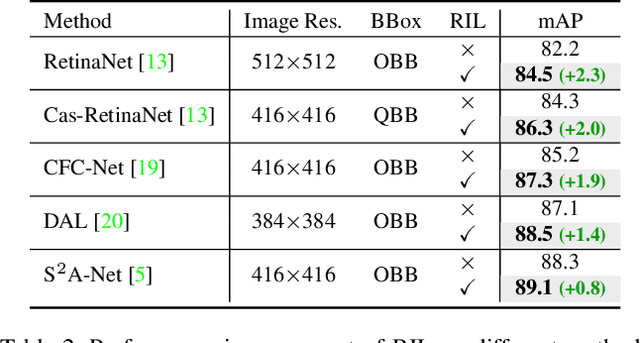
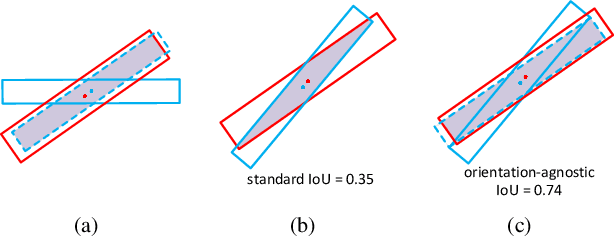
Arbitrary-oriented objects exist widely in natural scenes, and thus the oriented object detection has received extensive attention in recent years. The mainstream rotation detectors use oriented bounding boxes (OBB) or quadrilateral bounding boxes (QBB) to represent the rotating objects. However, these methods suffer from the representation ambiguity for oriented object definition, which leads to suboptimal regression optimization and the inconsistency between the loss metric and the localization accuracy of the predictions. In this paper, we propose a Representation Invariance Loss (RIL) to optimize the bounding box regression for the rotating objects. Specifically, RIL treats multiple representations of an oriented object as multiple equivalent local minima, and hence transforms bounding box regression into an adaptive matching process with these local minima. Then, the Hungarian matching algorithm is adopted to obtain the optimal regression strategy. We also propose a normalized rotation loss to alleviate the weak correlation between different variables and their unbalanced loss contribution in OBB representation. Extensive experiments on remote sensing datasets and scene text datasets show that our method achieves consistent and substantial improvement. The source code and trained models are available at https://github.com/ming71/RIDet.
CFC-Net: A Critical Feature Capturing Network for Arbitrary-Oriented Object Detection in Remote Sensing Images
Jan 18, 2021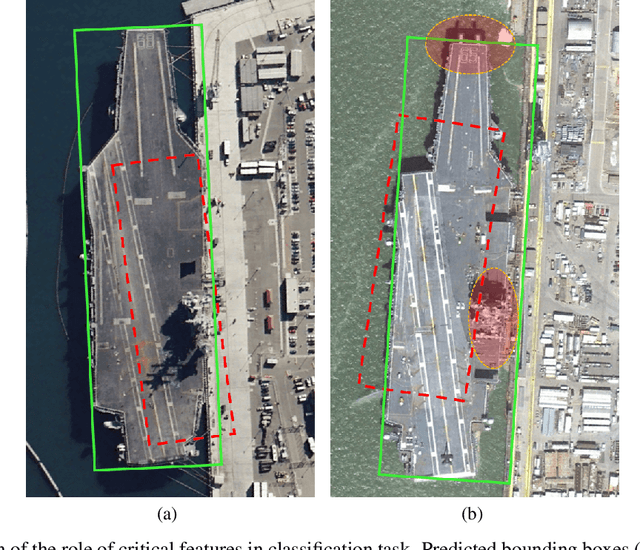
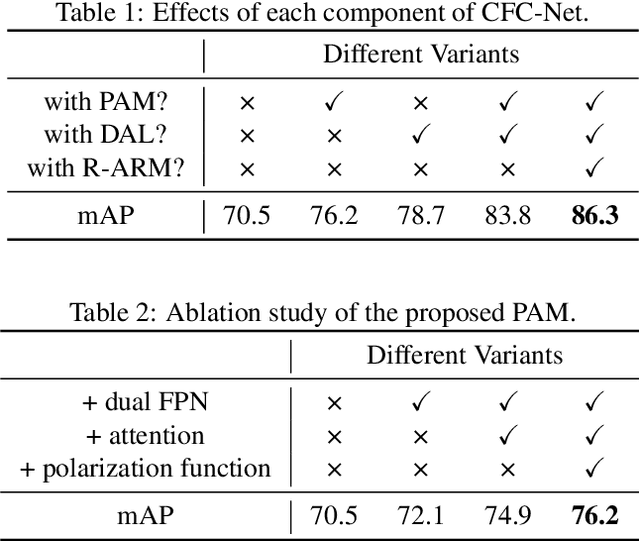
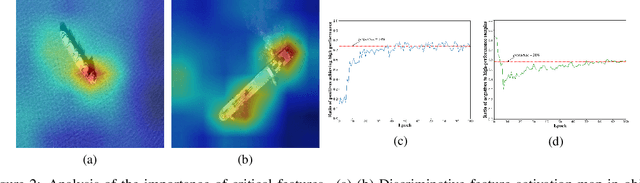
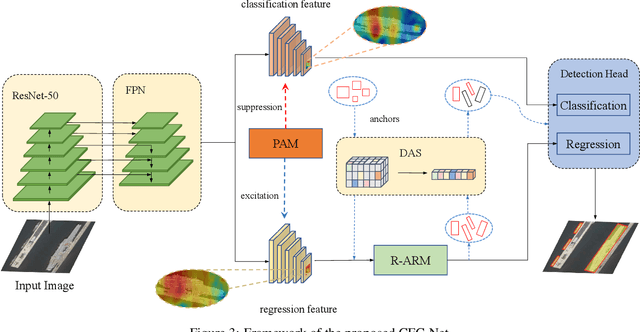
Object detection in optical remote sensing images is an important and challenging task. In recent years, the methods based on convolutional neural networks have made good progress. However, due to the large variation in object scale, aspect ratio, and arbitrary orientation, the detection performance is difficult to be further improved. In this paper, we discuss the role of discriminative features in object detection, and then propose a Critical Feature Capturing Network (CFC-Net) to improve detection accuracy from three aspects: building powerful feature representation, refining preset anchors, and optimizing label assignment. Specifically, we first decouple the classification and regression features, and then construct robust critical features adapted to the respective tasks through the Polarization Attention Module (PAM). With the extracted discriminative regression features, the Rotation Anchor Refinement Module (R-ARM) performs localization refinement on preset horizontal anchors to obtain superior rotation anchors. Next, the Dynamic Anchor Learning (DAL) strategy is given to adaptively select high-quality anchors based on their ability to capture critical features. The proposed framework creates more powerful semantic representations for objects in remote sensing images and achieves high-performance real-time object detection. Experimental results on three remote sensing datasets including HRSC2016, DOTA, and UCAS-AOD show that our method achieves superior detection performance compared with many state-of-the-art approaches. Code and models are available at https://github.com/ming71/CFC-Net.
Dynamic Anchor Learning for Arbitrary-Oriented Object Detection
Dec 15, 2020
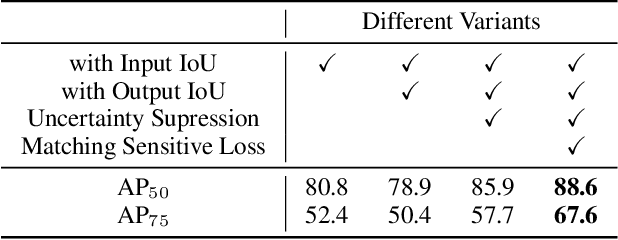
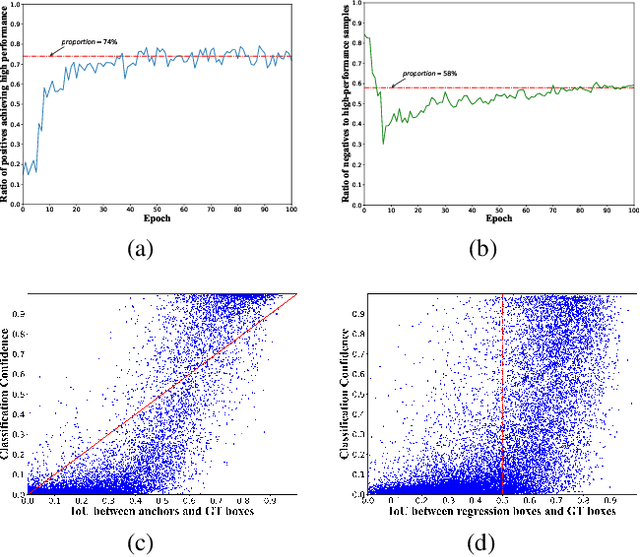
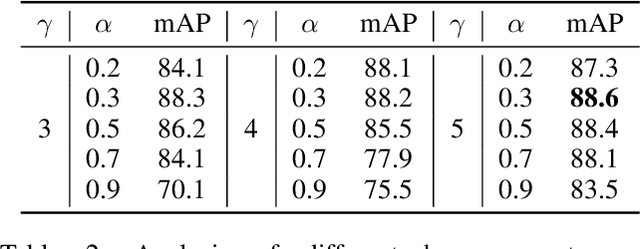
Arbitrary-oriented objects widely appear in natural scenes, aerial photographs, remote sensing images, etc., thus arbitrary-oriented object detection has received considerable attention. Many current rotation detectors use plenty of anchors with different orientations to achieve spatial alignment with ground truth boxes, then Intersection-over-Union (IoU) is applied to sample the positive and negative candidates for training. However, we observe that the selected positive anchors cannot always ensure accurate detections after regression, while some negative samples can achieve accurate localization. It indicates that the quality assessment of anchors through IoU is not appropriate, and this further lead to inconsistency between classification confidence and localization accuracy. In this paper, we propose a dynamic anchor learning (DAL) method, which utilizes the newly defined matching degree to comprehensively evaluate the localization potential of the anchors and carry out a more efficient label assignment process. In this way, the detector can dynamically select high-quality anchors to achieve accurate object detection, and the divergence between classification and regression will be alleviated. With the newly introduced DAL, we achieve superior detection performance for arbitrary-oriented objects with only a few horizontal preset anchors. Experimental results on three remote sensing datasets HRSC2016, DOTA, UCAS-AOD as well as a scene text dataset ICDAR 2015 show that our method achieves substantial improvement compared with the baseline model. Besides, our approach is also universal for object detection using horizontal bound box. The code and models are available at https://github.com/ming71/DAL.
A Novel CNN-based Method for Accurate Ship Detection in HR Optical Remote Sensing Images via Rotated Bounding Box
May 08, 2020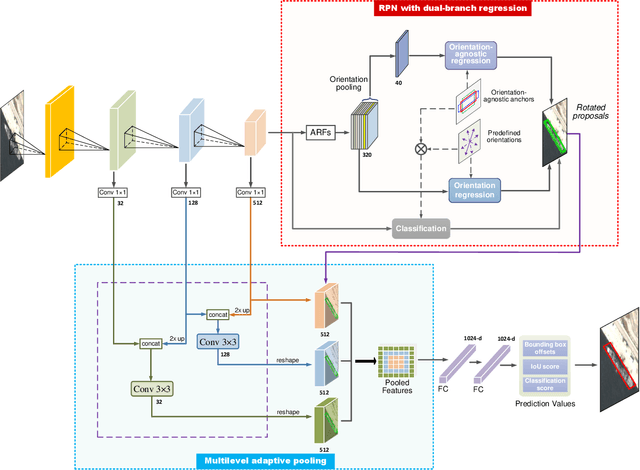

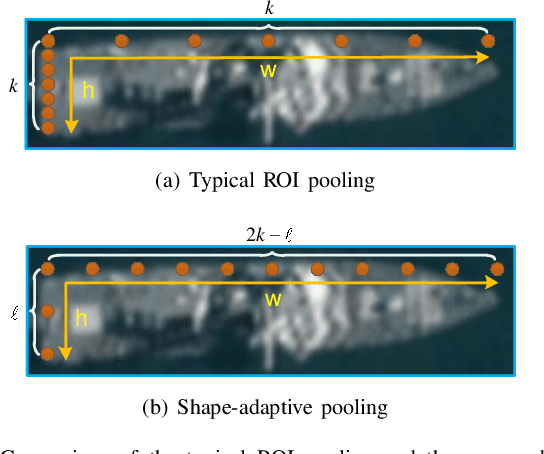
Currently, reliable and accurate ship detection in optical remote sensing images is still challenging. Even the state-of-the-art convolutional neural network (CNN) based methods cannot obtain very satisfactory results. To more accurately locate the ships in diverse orientations, some recent methods conduct the detection via the rotated bounding box. However, it further increases the difficulty of detection, because an additional variable of ship orientation must be accurately predicted in the algorithm. In this paper, a novel CNN-based ship detection method is proposed, by overcoming some common deficiencies of current CNN-based methods in ship detection. Specifically, to generate rotated region proposals, current methods have to predefine multi-oriented anchors, and predict all unknown variables together in one regression process, limiting the quality of overall prediction. By contrast, we are able to predict the orientation and other variables independently, and yet more effectively, with a novel dual-branch regression network, based on the observation that the ship targets are nearly rotation-invariant in remote sensing images. Next, a shape-adaptive pooling method is proposed, to overcome the limitation of typical regular ROI-pooling in extracting the features of the ships with various aspect ratios. Furthermore, we propose to incorporate multilevel features via the spatially-variant adaptive pooling. This novel approach, called multilevel adaptive pooling, leads to a compact feature representation more qualified for the simultaneous ship classification and localization. Finally, detailed ablation study performed on the proposed approaches is provided, along with some useful insights. Experimental results demonstrate the great superiority of the proposed method in ship detection.