 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEach Prompt Matters: Scaling Reinforcement Learning Without Wasting Rollouts on Hundred-Billion-Scale MoE
Dec 08, 2025We present CompassMax-V3-Thinking, a hundred-billion-scale MoE reasoning model trained with a new RL framework built on one principle: each prompt must matter. Scaling RL to this size exposes critical inefficiencies-zero-variance prompts that waste rollouts, unstable importance sampling over long horizons, advantage inversion from standard reward models, and systemic bottlenecks in rollout processing. To overcome these challenges, we introduce several unified innovations: (1) Multi-Stage Zero-Variance Elimination, which filters out non-informative prompts and stabilizes group-based policy optimization (e.g. GRPO) by removing wasted rollouts; (2) ESPO, an entropy-adaptive optimization method that balances token-level and sequence-level importance sampling to maintain stable learning dynamics; (3) a Router Replay strategy that aligns training-time MoE router decisions with inference-time behavior to mitigate train-infer discrepancies, coupled with a reward model adjustment to prevent advantage inversion; (4) a high-throughput RL system with FP8-precision rollouts, overlapped reward computation, and length-aware scheduling to eliminate performance bottlenecks. Together, these contributions form a cohesive pipeline that makes RL on hundred-billion-scale MoE models stable and efficient. The resulting model delivers strong performance across both internal and public evaluations.
Towards Reliable Evaluation of Large Language Models for Multilingual and Multimodal E-Commerce Applications
Oct 23, 2025Large Language Models (LLMs) excel on general-purpose NLP benchmarks, yet their capabilities in specialized domains remain underexplored. In e-commerce, existing evaluations-such as EcomInstruct, ChineseEcomQA, eCeLLM, and Shopping MMLU-suffer from limited task diversity (e.g., lacking product guidance and after-sales issues), limited task modalities (e.g., absence of multimodal data), synthetic or curated data, and a narrow focus on English and Chinese, leaving practitioners without reliable tools to assess models on complex, real-world shopping scenarios. We introduce EcomEval, a comprehensive multilingual and multimodal benchmark for evaluating LLMs in e-commerce. EcomEval covers six categories and 37 tasks (including 8 multimodal tasks), sourced primarily from authentic customer queries and transaction logs, reflecting the noisy and heterogeneous nature of real business interactions. To ensure both quality and scalability of reference answers, we adopt a semi-automatic pipeline in which large models draft candidate responses subsequently reviewed and modified by over 50 expert annotators with strong e-commerce and multilingual expertise. We define difficulty levels for each question and task category by averaging evaluation scores across models with different sizes and capabilities, enabling challenge-oriented and fine-grained assessment. EcomEval also spans seven languages-including five low-resource Southeast Asian languages-offering a multilingual perspective absent from prior work.
CoCAViT: Compact Vision Transformer with Robust Global Coordination
Aug 07, 2025In recent years, large-scale visual backbones have demonstrated remarkable capabilities in learning general-purpose features from images via extensive pre-training. Concurrently, many efficient architectures have emerged that have performance comparable to that of larger models on in-domain benchmarks. However, we observe that for smaller models, the performance drop on out-of-distribution (OOD) data is disproportionately larger, indicating a deficiency in the generalization performance of existing efficient models. To address this, we identify key architectural bottlenecks and inappropriate design choices that contribute to this issue, retaining robustness for smaller models. To restore the global field of pure window attention, we further introduce a Coordinator-patch Cross Attention (CoCA) mechanism, featuring dynamic, domain-aware global tokens that enhance local-global feature modeling and adaptively capture robust patterns across domains with minimal computational overhead. Integrating these advancements, we present CoCAViT, a novel visual backbone designed for robust real-time visual representation. Extensive experiments empirically validate our design. At a resolution of 224*224, CoCAViT-28M achieves 84.0% top-1 accuracy on ImageNet-1K, with significant gains on multiple OOD benchmarks, compared to competing models. It also attains 52.2 mAP on COCO object detection and 51.3 mIOU on ADE20K semantic segmentation, while maintaining low latency.
GraphSubDetector: Time Series Subsequence Anomaly Detection via Density-Aware Adaptive Graph Neural Network
Nov 26, 2024



Time series subsequence anomaly detection is an important task in a large variety of real-world applications ranging from health monitoring to AIOps, and is challenging due to the following reasons: 1) how to effectively learn complex dynamics and dependencies in time series; 2) diverse and complicated anomalous subsequences as well as the inherent variance and noise of normal patterns; 3) how to determine the proper subsequence length for effective detection, which is a required parameter for many existing algorithms. In this paper, we present a novel approach to subsequence anomaly detection, namely GraphSubDetector. First, it adaptively learns the appropriate subsequence length with a length selection mechanism that highlights the characteristics of both normal and anomalous patterns. Second, we propose a density-aware adaptive graph neural network (DAGNN), which can generate further robust representations against variance of normal data for anomaly detection by message passing between subsequences. The experimental results demonstrate the effectiveness of the proposed algorithm, which achieves superior performance on multiple time series anomaly benchmark datasets compared to state-of-the-art algorithms.
Infrared and visible Image Fusion with Language-driven Loss in CLIP Embedding Space
Feb 26, 2024Infrared-visible image fusion (IVIF) has attracted much attention owing to the highly-complementary properties of the two image modalities. Due to the lack of ground-truth fused images, the fusion output of current deep-learning based methods heavily depends on the loss functions defined mathematically. As it is hard to well mathematically define the fused image without ground truth, the performance of existing fusion methods is limited. In this paper, we first propose to use natural language to express the objective of IVIF, which can avoid the explicit mathematical modeling of fusion output in current losses, and make full use of the advantage of language expression to improve the fusion performance. For this purpose, we present a comprehensive language-expressed fusion objective, and encode relevant texts into the multi-modal embedding space using CLIP. A language-driven fusion model is then constructed in the embedding space, by establishing the relationship among the embedded vectors to represent the fusion objective and input image modalities. Finally, a language-driven loss is derived to make the actual IVIF aligned with the embedded language-driven fusion model via supervised training. Experiments show that our method can obtain much better fusion results than existing techniques.
Semantic Object-level Modeling for Robust Visual Camera Relocalization
Feb 10, 2024



Visual relocalization is crucial for autonomous visual localization and navigation of mobile robotics. Due to the improvement of CNN-based object detection algorithm, the robustness of visual relocalization is greatly enhanced especially in viewpoints where classical methods fail. However, ellipsoids (quadrics) generated by axis-aligned object detection may limit the accuracy of the object-level representation and degenerate the performance of visual relocalization system. In this paper, we propose a novel method of automatic object-level voxel modeling for accurate ellipsoidal representations of objects. As for visual relocalization, we design a better pose optimization strategy for camera pose recovery, to fully utilize the projection characteristics of 2D fitted ellipses and the 3D accurate ellipsoids. All of these modules are entirely intergrated into visual SLAM system. Experimental results show that our semantic object-level mapping and object-based visual relocalization methods significantly enhance the performance of visual relocalization in terms of robustness to new viewpoints.
AHPA: Adaptive Horizontal Pod Autoscaling Systems on Alibaba Cloud Container Service for Kubernetes
Mar 07, 2023The existing resource allocation policy for application instances in Kubernetes cannot dynamically adjust according to the requirement of business, which would cause an enormous waste of resources during fluctuations. Moreover, the emergence of new cloud services puts higher resource management requirements. This paper discusses horizontal POD resources management in Alibaba Cloud Container Services with a newly deployed AI algorithm framework named AHPA -- the adaptive horizontal pod auto-scaling system. Based on a robust decomposition forecasting algorithm and performance training model, AHPA offers an optimal pod number adjustment plan that could reduce POD resources and maintain business stability. Since being deployed in April 2021, this system has expanded to multiple customer scenarios, including logistics, social networks, AI audio and video, e-commerce, etc. Compared with the previous algorithms, AHPA solves the elastic lag problem, increasing CPU usage by 10% and reducing resource cost by more than 20%. In addition, AHPA can automatically perform flexible planning according to the predicted business volume without manual intervention, significantly saving operation and maintenance costs.
Towards Out-of-Distribution Sequential Event Prediction: A Causal Treatment
Oct 24, 2022



The goal of sequential event prediction is to estimate the next event based on a sequence of historical events, with applications to sequential recommendation, user behavior analysis and clinical treatment. In practice, the next-event prediction models are trained with sequential data collected at one time and need to generalize to newly arrived sequences in remote future, which requires models to handle temporal distribution shift from training to testing. In this paper, we first take a data-generating perspective to reveal a negative result that existing approaches with maximum likelihood estimation would fail for distribution shift due to the latent context confounder, i.e., the common cause for the historical events and the next event. Then we devise a new learning objective based on backdoor adjustment and further harness variational inference to make it tractable for sequence learning problems. On top of that, we propose a framework with hierarchical branching structures for learning context-specific representations. Comprehensive experiments on diverse tasks (e.g., sequential recommendation) demonstrate the effectiveness, applicability and scalability of our method with various off-the-shelf models as backbones.
NetRCA: An Effective Network Fault Cause Localization Algorithm
Mar 07, 2022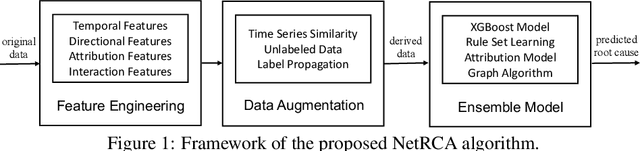
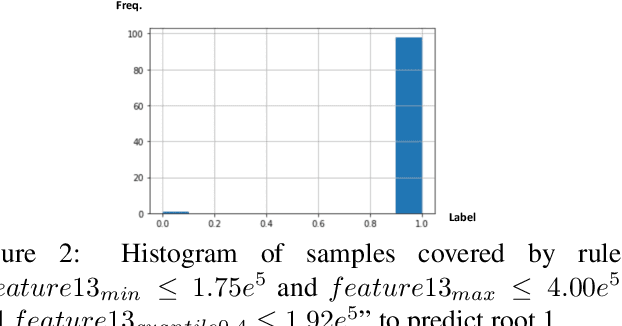
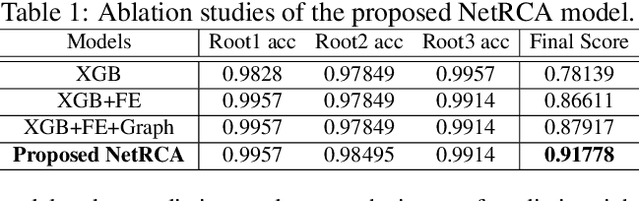
Localizing the root cause of network faults is crucial to network operation and maintenance. However, due to the complicated network architectures and wireless environments, as well as limited labeled data, accurately localizing the true root cause is challenging. In this paper, we propose a novel algorithm named NetRCA to deal with this problem. Firstly, we extract effective derived features from the original raw data by considering temporal, directional, attribution, and interaction characteristics. Secondly, we adopt multivariate time series similarity and label propagation to generate new training data from both labeled and unlabeled data to overcome the lack of labeled samples. Thirdly, we design an ensemble model which combines XGBoost, rule set learning, attribution model, and graph algorithm, to fully utilize all data information and enhance performance. Finally, experiments and analysis are conducted on the real-world dataset from ICASSP 2022 AIOps Challenge to demonstrate the superiority and effectiveness of our approach.
Oriented Feature Alignment for Fine-grained Object Recognition in High-Resolution Satellite Imagery
Oct 13, 2021
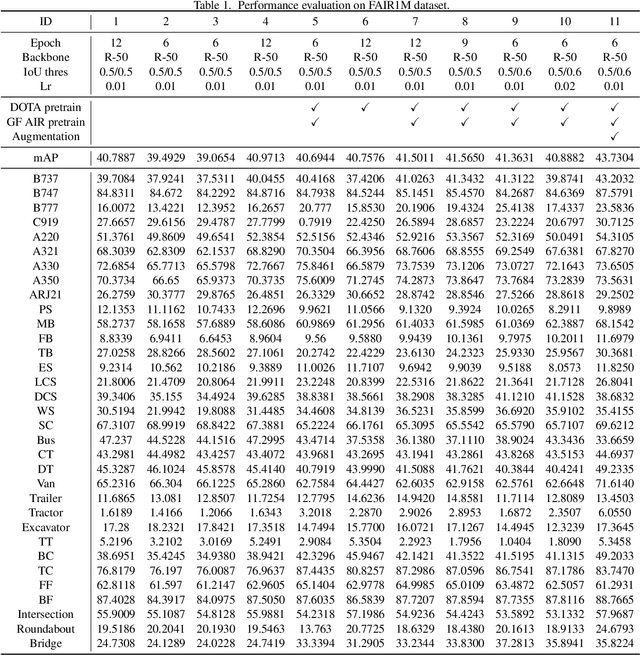
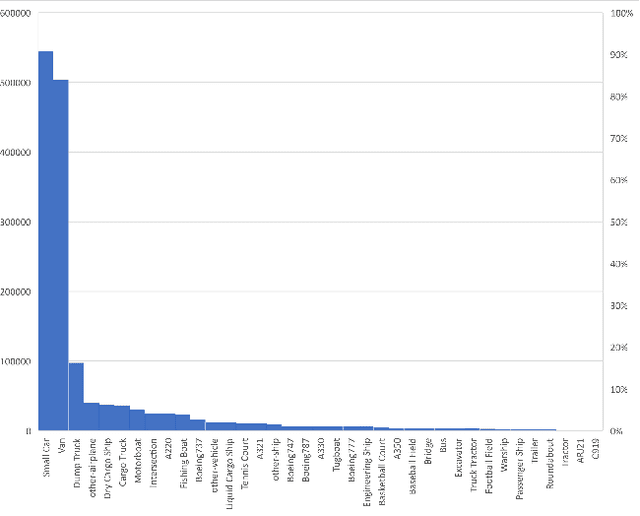

Oriented object detection in remote sensing images has made great progress in recent years. However, most of the current methods only focus on detecting targets, and cannot distinguish fine-grained objects well in complex scenes. In this technical report, we analyzed the key issues of fine-grained object recognition, and use an oriented feature alignment network (OFA-Net) to achieve high-performance fine-grained oriented object recognition in optical remote sensing images. OFA-Net achieves accurate object localization through a rotated bounding boxes refinement module. On this basis, the boundary-constrained rotation feature alignment module is applied to achieve local feature extraction, which is beneficial to fine-grained object classification. The single model of our method achieved mAP of 46.51\% in the GaoFen competition and won 3rd place in the ISPRS benchmark with the mAP of 43.73\%.