 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Detection Based on Distributed Convolutional Neural Networks
Mar 30, 2026Based on the Distributed Convolutional Neural Network(DisCNN), a straightforward object detection method is proposed. The modules of the output vector of a DisCNN with respect to a specific positive class are positively monotonic with the presence probabilities of the positive features. So, by identifying all high-scoring patches across all possible scales, the positive object can be detected by overlapping them to form a bounding box. The essential idea is that the object is detected by detecting its features on multiple scales, ranging from specific sub-features to abstract features composed of these sub-features. Training DisCNN requires only object-centered image data with positive and negative class labels. The detection process for multiple positive classes can be conducted in parallel to significantly accelerate it, and also faster for single-object detection because of its lightweight model architecture.
Skillful Kilometer-Scale Regional Weather Forecasting via Global and Regional Coupling
Mar 30, 2026Data-driven weather models have advanced global medium-range forecasting, yet high-resolution regional prediction remains challenging due to unresolved multiscale interactions between large-scale dynamics and small-scale processes such as terrain-induced circulations and coastal effects. This paper presents a global-regional coupling framework for kilometer-scale regional weather forecasting that synergistically couples a pretrained Transformer-based global model with a high-resolution regional network via a novel bidirectional coupling module, ScaleMixer. ScaleMixer dynamically identifies meteorologically critical regions through adaptive key-position sampling and enables cross-scale feature interaction through dedicated attention mechanisms. The framework produces forecasts at $0.05^\circ$ ($\sim 5 \mathrm{km}$ ) and 1-hour resolution over China, significantly outperforming operational NWP and AI baselines on both gridded reanalysis data and real-time weather station observations. It exhibits exceptional skill in capturing fine-grained phenomena such as orographic wind patterns and Foehn warming, demonstrating effective global-scale coherence with high-resolution fidelity. The code is available at https://anonymous.4open.science/r/ScaleMixer-6B66.
Baguan-TS: A Sequence-Native In-Context Learning Model for Time Series Forecasting with Covariates
Mar 18, 2026Transformers enable in-context learning (ICL) for rapid, gradient-free adaptation in time series forecasting, yet most ICL-style approaches rely on tabularized, hand-crafted features, while end-to-end sequence models lack inference-time adaptation. We bridge this gap with a unified framework, Baguan-TS, which integrates the raw-sequence representation learning with ICL, instantiated by a 3D Transformer that attends jointly over temporal, variable, and context axes. To make this high-capacity model practical, we tackle two key hurdles: (i) calibration and training stability, improved with a feature-agnostic, target-space retrieval-based local calibration; and (ii) output oversmoothing, mitigated via context-overfitting strategy. On public benchmark with covariates, Baguan-TS consistently outperforms established baselines, achieving the highest win rate and significant reductions in both point and probabilistic forecasting metrics. Further evaluations across diverse real-world energy datasets demonstrate its robustness, yielding substantial improvements.
Integrating Weather Foundation Model and Satellite to Enable Fine-Grained Solar Irradiance Forecasting
Mar 17, 2026Accurate day-ahead solar irradiance forecasting is essential for integrating solar energy into the power grid. However, it remains challenging due to the pronounced diurnal cycle and inherently complex cloud dynamics. Current methods either lack fine-scale resolution (e.g., numerical weather prediction, weather foundation models) or degrade at longer lead times (e.g., satellite extrapolation). We propose Baguan-solar, a two-stage multimodal framework that fuses forecasts from Baguan, a global weather foundation model, with high-resolution geostationary satellite imagery to produce 24- hour irradiance forecasts at kilometer scale. Its decoupled two-stage design first forecasts day-night continuous intermediates (e.g., cloud cover) and then infers irradiance, while its modality fusion jointly preserves fine-scale cloud structures from satellite and large-scale constraints from Baguan forecasts. Evaluated over East Asia using CLDAS as ground truth, Baguan-solar outperforms strong baselines (including ECMWF IFS, vanilla Baguan, and SolarSeer), reducing RMSE by 16.08% and better resolving cloud-induced transients. An operational deployment of Baguan-solar has supported solar power forecasting in an eastern province in China, since July 2025. Our code is accessible at https://github.com/DAMO-DI-ML/Baguansolar. git.
Distributed Convolutional Neural Networks for Object Recognition
Mar 10, 2026This paper proposes a novel loss function for training a distributed convolutional neural network (DisCNN) to recognize only a specific positive class. By mapping positive samples to a compact set in high-dimensional space and negative samples to Origin, the DisCNN extracts only the features of the positive class. An experiment is given to prove this. Thus, the features of the positive class are disentangled from those of the negative classes. The model has a lightweight architecture because only a few positive-class features need to be extracted. The model demonstrates excellent generalization on the test data and remains effective even for unseen classes. Finally, using DisCNN, object detection of positive samples embedded in a large and complex background is straightforward.
Bridging Past and Future: Distribution-Aware Alignment for Time Series Forecasting
Sep 17, 2025Representation learning techniques like contrastive learning have long been explored in time series forecasting, mirroring their success in computer vision and natural language processing. Yet recent state-of-the-art (SOTA) forecasters seldom adopt these representation approaches because they have shown little performance advantage. We challenge this view and demonstrate that explicit representation alignment can supply critical information that bridges the distributional gap between input histories and future targets. To this end, we introduce TimeAlign, a lightweight, plug-and-play framework that learns auxiliary features via a simple reconstruction task and feeds them back to any base forecaster. Extensive experiments across eight benchmarks verify its superior performance. Further studies indicate that the gains arises primarily from correcting frequency mismatches between historical inputs and future outputs. We also provide a theoretical justification for the effectiveness of TimeAlign in increasing the mutual information between learned representations and predicted targets. As it is architecture-agnostic and incurs negligible overhead, TimeAlign can serve as a general alignment module for modern deep learning time-series forecasting systems. The code is available at https://github.com/TROUBADOUR000/TimeAlign.
Integrating Neurosymbolic AI in Advanced Air Mobility: A Comprehensive Survey
Aug 10, 2025Neurosymbolic AI combines neural network adaptability with symbolic reasoning, promising an approach to address the complex regulatory, operational, and safety challenges in Advanced Air Mobility (AAM). This survey reviews its applications across key AAM domains such as demand forecasting, aircraft design, and real-time air traffic management. Our analysis reveals a fragmented research landscape where methodologies, including Neurosymbolic Reinforcement Learning, have shown potential for dynamic optimization but still face hurdles in scalability, robustness, and compliance with aviation standards. We classify current advancements, present relevant case studies, and outline future research directions aimed at integrating these approaches into reliable, transparent AAM systems. By linking advanced AI techniques with AAM's operational demands, this work provides a concise roadmap for researchers and practitioners developing next-generation air mobility solutions.
Integrated Influence: Data Attribution with Baseline
Aug 07, 2025As an effective approach to quantify how training samples influence test sample, data attribution is crucial for understanding data and model and further enhance the transparency of machine learning models. We find that prevailing data attribution methods based on leave-one-out (LOO) strategy suffer from the local-based explanation, as these LOO-based methods only perturb a single training sample, and overlook the collective influence in the training set. On the other hand, the lack of baseline in many data attribution methods reduces the flexibility of the explanation, e.g., failing to provide counterfactual explanations. In this paper, we propose Integrated Influence, a novel data attribution method that incorporates a baseline approach. Our method defines a baseline dataset, follows a data degeneration process to transition the current dataset to the baseline, and accumulates the influence of each sample throughout this process. We provide a solid theoretical framework for our method, and further demonstrate that popular methods, such as influence functions, can be viewed as special cases of our approach. Experimental results show that Integrated Influence generates more reliable data attributions compared to existing methods in both data attribution task and mislablled example identification task.
MorphSAM: Learning the Morphological Prompts from Atlases for Spine Image Segmentation
Jun 16, 2025Spine image segmentation is crucial for clinical diagnosis and treatment of spine diseases. The complex structure of the spine and the high morphological similarity between individual vertebrae and adjacent intervertebral discs make accurate spine segmentation a challenging task. Although the Segment Anything Model (SAM) has been developed, it still struggles to effectively capture and utilize morphological information, limiting its ability to enhance spine image segmentation performance. To address these challenges, in this paper, we propose a MorphSAM that explicitly learns morphological information from atlases, thereby strengthening the spine image segmentation performance of SAM. Specifically, the MorphSAM includes two fully automatic prompt learning networks, 1) an anatomical prompt learning network that directly learns morphological information from anatomical atlases, and 2) a semantic prompt learning network that derives morphological information from text descriptions converted from the atlases. Then, the two learned morphological prompts are fed into the SAM model to boost the segmentation performance. We validate our MorphSAM on two spine image segmentation tasks, including a spine anatomical structure segmentation task with CT images and a lumbosacral plexus segmentation task with MR images. Experimental results demonstrate that our MorphSAM achieves superior segmentation performance when compared to the state-of-the-art methods.
Physics-Guided Learning of Meteorological Dynamics for Weather Downscaling and Forecasting
May 20, 2025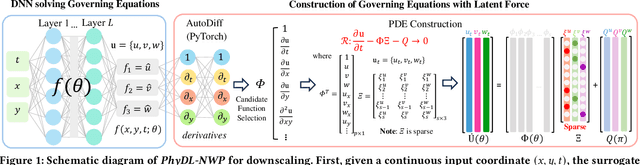

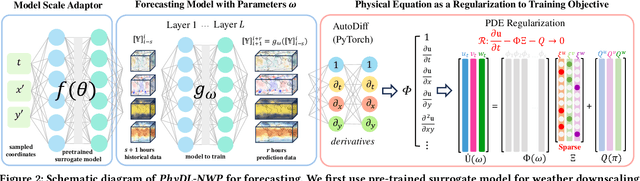
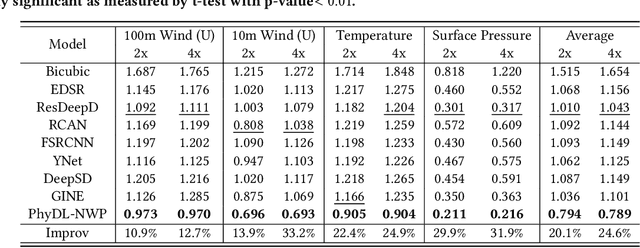
Weather forecasting is essential but remains computationally intensive and physically incomplete in traditional numerical weather prediction (NWP) methods. Deep learning (DL) models offer efficiency and accuracy but often ignore physical laws, limiting interpretability and generalization. We propose PhyDL-NWP, a physics-guided deep learning framework that integrates physical equations with latent force parameterization into data-driven models. It predicts weather variables from arbitrary spatiotemporal coordinates, computes physical terms via automatic differentiation, and uses a physics-informed loss to align predictions with governing dynamics. PhyDL-NWP enables resolution-free downscaling by modeling weather as a continuous function and fine-tunes pre-trained models with minimal overhead, achieving up to 170x faster inference with only 55K parameters. Experiments show that PhyDL-NWP improves both forecasting performance and physical consistency.