 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Strategic Pre-training to Reduce Overfitting: Baguan -- A Pre-trained Weather Forecasting Model
May 20, 2025Weather forecasting has long posed a significant challenge for humanity. While recent AI-based models have surpassed traditional numerical weather prediction (NWP) methods in global forecasting tasks, overfitting remains a critical issue due to the limited availability of real-world weather data spanning only a few decades. Unlike fields like computer vision or natural language processing, where data abundance can mitigate overfitting, weather forecasting demands innovative strategies to address this challenge with existing data. In this paper, we explore pre-training methods for weather forecasting, finding that selecting an appropriately challenging pre-training task introduces locality bias, effectively mitigating overfitting and enhancing performance. We introduce Baguan, a novel data-driven model for medium-range weather forecasting, built on a Siamese Autoencoder pre-trained in a self-supervised manner and fine-tuned for different lead times. Experimental results show that Baguan outperforms traditional methods, delivering more accurate forecasts. Additionally, the pre-trained Baguan demonstrates robust overfitting control and excels in downstream tasks, such as subseasonal-to-seasonal (S2S) modeling and regional forecasting, after fine-tuning.
One Fits All: Universal Time Series Analysis by Pretrained LM and Specially Designed Adaptors
Nov 24, 2023
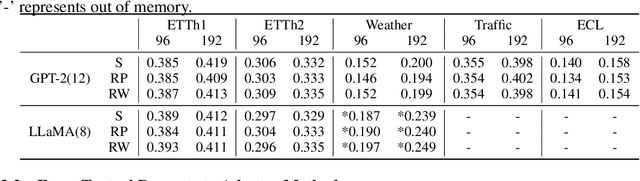


Despite the impressive achievements of pre-trained models in the fields of natural language processing (NLP) and computer vision (CV), progress in the domain of time series analysis has been limited. In contrast to NLP and CV, where a single model can handle various tasks, time series analysis still relies heavily on task-specific methods for activities such as classification, anomaly detection, forecasting, and few-shot learning. The primary obstacle to developing a pre-trained model for time series analysis is the scarcity of sufficient training data. In our research, we overcome this obstacle by utilizing pre-trained models from language or CV, which have been trained on billions of data points, and apply them to time series analysis. We assess the effectiveness of the pre-trained transformer model in two ways. Initially, we maintain the original structure of the self-attention and feedforward layers in the residual blocks of the pre-trained language or image model, using the Frozen Pre-trained Transformer (FPT) for time series analysis with the addition of projection matrices for input and output. Additionally, we introduce four unique adapters, designed specifically for downstream tasks based on the pre-trained model, including forecasting and anomaly detection. These adapters are further enhanced with efficient parameter tuning, resulting in superior performance compared to all state-of-the-art methods.Our comprehensive experimental studies reveal that (a) the simple FPT achieves top-tier performance across various time series analysis tasks; and (b) fine-tuning the FPT with the custom-designed adapters can further elevate its performance, outshining specialized task-specific models.