 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaguan-TS: A Sequence-Native In-Context Learning Model for Time Series Forecasting with Covariates
Mar 18, 2026Transformers enable in-context learning (ICL) for rapid, gradient-free adaptation in time series forecasting, yet most ICL-style approaches rely on tabularized, hand-crafted features, while end-to-end sequence models lack inference-time adaptation. We bridge this gap with a unified framework, Baguan-TS, which integrates the raw-sequence representation learning with ICL, instantiated by a 3D Transformer that attends jointly over temporal, variable, and context axes. To make this high-capacity model practical, we tackle two key hurdles: (i) calibration and training stability, improved with a feature-agnostic, target-space retrieval-based local calibration; and (ii) output oversmoothing, mitigated via context-overfitting strategy. On public benchmark with covariates, Baguan-TS consistently outperforms established baselines, achieving the highest win rate and significant reductions in both point and probabilistic forecasting metrics. Further evaluations across diverse real-world energy datasets demonstrate its robustness, yielding substantial improvements.
Integrating Weather Foundation Model and Satellite to Enable Fine-Grained Solar Irradiance Forecasting
Mar 17, 2026Accurate day-ahead solar irradiance forecasting is essential for integrating solar energy into the power grid. However, it remains challenging due to the pronounced diurnal cycle and inherently complex cloud dynamics. Current methods either lack fine-scale resolution (e.g., numerical weather prediction, weather foundation models) or degrade at longer lead times (e.g., satellite extrapolation). We propose Baguan-solar, a two-stage multimodal framework that fuses forecasts from Baguan, a global weather foundation model, with high-resolution geostationary satellite imagery to produce 24- hour irradiance forecasts at kilometer scale. Its decoupled two-stage design first forecasts day-night continuous intermediates (e.g., cloud cover) and then infers irradiance, while its modality fusion jointly preserves fine-scale cloud structures from satellite and large-scale constraints from Baguan forecasts. Evaluated over East Asia using CLDAS as ground truth, Baguan-solar outperforms strong baselines (including ECMWF IFS, vanilla Baguan, and SolarSeer), reducing RMSE by 16.08% and better resolving cloud-induced transients. An operational deployment of Baguan-solar has supported solar power forecasting in an eastern province in China, since July 2025. Our code is accessible at https://github.com/DAMO-DI-ML/Baguansolar. git.
SOON: Symmetric Orthogonal Operator Network for Global Subseasonal-to-Seasonal Climate Forecasting
Feb 04, 2026Accurate global Subseasonal-to-Seasonal (S2S) climate forecasting is critical for disaster preparedness and resource management, yet it remains challenging due to chaotic atmospheric dynamics. Existing models predominantly treat atmospheric fields as isotropic images, conflating the distinct physical processes of zonal wave propagation and meridional transport, and leading to suboptimal modeling of anisotropic dynamics. In this paper, we propose the Symmetric Orthogonal Operator Network (SOON) for global S2S climate forecasting. It couples: (1) an Anisotropic Embedding strategy that tokenizes the global grid into latitudinal rings, preserving the integrity of zonal periodic structures; and (2) a stack of SOON Blocks that models the alternating interaction of Zonal and Meridional Operators via a symmetric decomposition, structurally mitigating discretization errors inherent in long-term integration. Extensive experiments on the Earth Reanalysis 5 dataset demonstrate that SOON establishes a new state-of-the-art, significantly outperforming existing methods in both forecasting accuracy and computational efficiency.
Bridging Past and Future: Distribution-Aware Alignment for Time Series Forecasting
Sep 17, 2025Representation learning techniques like contrastive learning have long been explored in time series forecasting, mirroring their success in computer vision and natural language processing. Yet recent state-of-the-art (SOTA) forecasters seldom adopt these representation approaches because they have shown little performance advantage. We challenge this view and demonstrate that explicit representation alignment can supply critical information that bridges the distributional gap between input histories and future targets. To this end, we introduce TimeAlign, a lightweight, plug-and-play framework that learns auxiliary features via a simple reconstruction task and feeds them back to any base forecaster. Extensive experiments across eight benchmarks verify its superior performance. Further studies indicate that the gains arises primarily from correcting frequency mismatches between historical inputs and future outputs. We also provide a theoretical justification for the effectiveness of TimeAlign in increasing the mutual information between learned representations and predicted targets. As it is architecture-agnostic and incurs negligible overhead, TimeAlign can serve as a general alignment module for modern deep learning time-series forecasting systems. The code is available at https://github.com/TROUBADOUR000/TimeAlign.
Utilizing Strategic Pre-training to Reduce Overfitting: Baguan -- A Pre-trained Weather Forecasting Model
May 20, 2025Weather forecasting has long posed a significant challenge for humanity. While recent AI-based models have surpassed traditional numerical weather prediction (NWP) methods in global forecasting tasks, overfitting remains a critical issue due to the limited availability of real-world weather data spanning only a few decades. Unlike fields like computer vision or natural language processing, where data abundance can mitigate overfitting, weather forecasting demands innovative strategies to address this challenge with existing data. In this paper, we explore pre-training methods for weather forecasting, finding that selecting an appropriately challenging pre-training task introduces locality bias, effectively mitigating overfitting and enhancing performance. We introduce Baguan, a novel data-driven model for medium-range weather forecasting, built on a Siamese Autoencoder pre-trained in a self-supervised manner and fine-tuned for different lead times. Experimental results show that Baguan outperforms traditional methods, delivering more accurate forecasts. Additionally, the pre-trained Baguan demonstrates robust overfitting control and excels in downstream tasks, such as subseasonal-to-seasonal (S2S) modeling and regional forecasting, after fine-tuning.
Maximizing the Impact of Deep Learning on Subseasonal-to-Seasonal Climate Forecasting: The Essential Role of Optimization
Nov 23, 2024Weather and climate forecasting is vital for sectors such as agriculture and disaster management. Although numerical weather prediction (NWP) systems have advanced, forecasting at the subseasonal-to-seasonal (S2S) scale, spanning 2 to 6 weeks, remains challenging due to the chaotic and sparse atmospheric signals at this interval. Even state-of-the-art deep learning models struggle to outperform simple climatology models in this domain. This paper identifies that optimization, instead of network structure, could be the root cause of this performance gap, and then we develop a novel multi-stage optimization strategy to close the gap. Extensive empirical studies demonstrate that our multi-stage optimization approach significantly improves key skill metrics, PCC and TCC, while utilizing the same backbone structure, surpassing the state-of-the-art NWP systems (ECMWF-S2S) by over \textbf{19-91\%}. Our research contests the recent study that direct forecasting outperforms rolling forecasting for S2S tasks. Through theoretical analysis, we propose that the underperformance of rolling forecasting may arise from the accumulation of Jacobian matrix products during training. Our multi-stage framework can be viewed as a form of teacher forcing to address this issue. Code is available at \url{https://anonymous.4open.science/r/Baguan-S2S-23E7/}
Guided MRI Reconstruction via Schrödinger Bridge
Nov 21, 2024



Magnetic Resonance Imaging (MRI) is a multi-contrast imaging technique in which different contrast images share similar structural information. However, conventional diffusion models struggle to effectively leverage this structural similarity. Recently, the Schr\"odinger Bridge (SB), a nonlinear extension of the diffusion model, has been proposed to establish diffusion paths between any distributions, allowing the incorporation of guided priors. This study proposes an SB-based, multi-contrast image-guided reconstruction framework that establishes a diffusion bridge between the guiding and target image distributions. By using the guiding image along with data consistency during sampling, the target image is reconstructed more accurately. To better address structural differences between images, we introduce an inversion strategy from the field of image editing, termed $\mathbf{I}^2$SB-inversion. Experiments on a paried T1 and T2-FLAIR datasets demonstrate that $\mathbf{I}^2$SB-inversion achieve a high acceleration up to 14.4 and outperforms existing methods in terms of both reconstruction accuracy and stability.
Mitigating Time Discretization Challenges with WeatherODE: A Sandwich Physics-Driven Neural ODE for Weather Forecasting
Oct 09, 2024In the field of weather forecasting, traditional models often grapple with discretization errors and time-dependent source discrepancies, which limit their predictive performance. In this paper, we present WeatherODE, a novel one-stage, physics-driven ordinary differential equation (ODE) model designed to enhance weather forecasting accuracy. By leveraging wave equation theory and integrating a time-dependent source model, WeatherODE effectively addresses the challenges associated with time-discretization error and dynamic atmospheric processes. Moreover, we design a CNN-ViT-CNN sandwich structure, facilitating efficient learning dynamics tailored for distinct yet interrelated tasks with varying optimization biases in advection equation estimation. Through rigorous experiments, WeatherODE demonstrates superior performance in both global and regional weather forecasting tasks, outperforming recent state-of-the-art approaches by significant margins of over 40.0\% and 31.8\% in root mean square error (RMSE), respectively. The source code is available at \url{https://github.com/DAMO-DI-ML/WeatherODE}.
Less is more: Embracing sparsity and interpolation with Esiformer for time series forecasting
Oct 08, 2024Time series forecasting has played a significant role in many practical fields. But time series data generated from real-world applications always exhibits high variance and lots of noise, which makes it difficult to capture the inherent periodic patterns of the data, hurting the prediction accuracy significantly. To address this issue, we propose the Esiformer, which apply interpolation on the original data, decreasing the overall variance of the data and alleviating the influence of noise. What's more, we enhanced the vanilla transformer with a robust Sparse FFN. It can enhance the representation ability of the model effectively, and maintain the excellent robustness, avoiding the risk of overfitting compared with the vanilla implementation. Through evaluations on challenging real-world datasets, our method outperforms leading model PatchTST, reducing MSE by 6.5% and MAE by 5.8% in multivariate time series forecasting. Code is available at: https://github.com/yyg1282142265/Esiformer/tree/main.
Unlocking the Power of LSTM for Long Term Time Series Forecasting
Aug 19, 2024


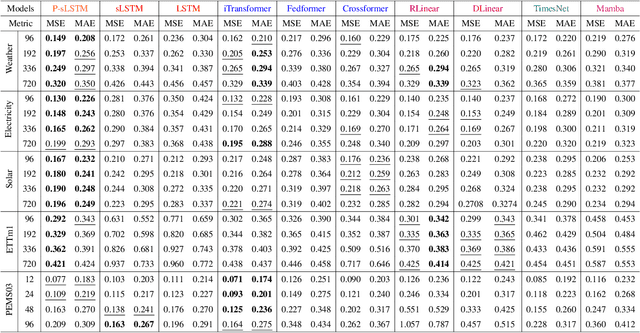
Traditional recurrent neural network architectures, such as long short-term memory neural networks (LSTM), have historically held a prominent role in time series forecasting (TSF) tasks. While the recently introduced sLSTM for Natural Language Processing (NLP) introduces exponential gating and memory mixing that are beneficial for long term sequential learning, its potential short memory issue is a barrier to applying sLSTM directly in TSF. To address this, we propose a simple yet efficient algorithm named P-sLSTM, which is built upon sLSTM by incorporating patching and channel independence. These modifications substantially enhance sLSTM's performance in TSF, achieving state-of-the-art results. Furthermore, we provide theoretical justifications for our design, and conduct extensive comparative and analytical experiments to fully validate the efficiency and superior performance of our model.