 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention as Robust Representation for Time Series Forecasting
Feb 08, 2024Time series forecasting is essential for many practical applications, with the adoption of transformer-based models on the rise due to their impressive performance in NLP and CV. Transformers' key feature, the attention mechanism, dynamically fusing embeddings to enhance data representation, often relegating attention weights to a byproduct role. Yet, time series data, characterized by noise and non-stationarity, poses significant forecasting challenges. Our approach elevates attention weights as the primary representation for time series, capitalizing on the temporal relationships among data points to improve forecasting accuracy. Our study shows that an attention map, structured using global landmarks and local windows, acts as a robust kernel representation for data points, withstanding noise and shifts in distribution. Our method outperforms state-of-the-art models, reducing mean squared error (MSE) in multivariate time series forecasting by a notable 3.6% without altering the core neural network architecture. It serves as a versatile component that can readily replace recent patching based embedding schemes in transformer-based models, boosting their performance.
Power Time Series Forecasting by Pretrained LM
Feb 23, 2023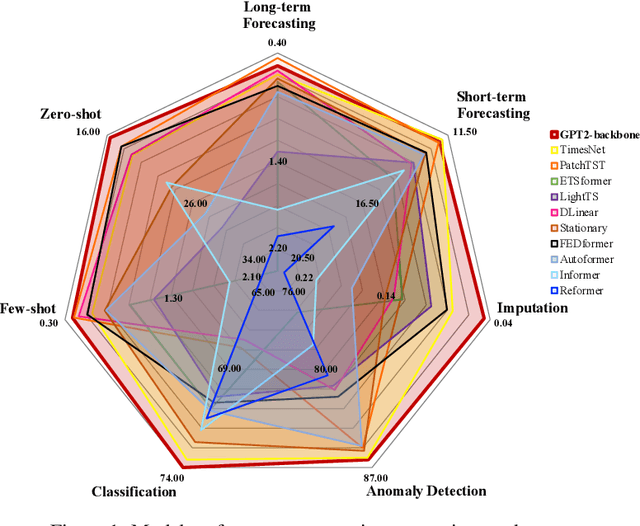

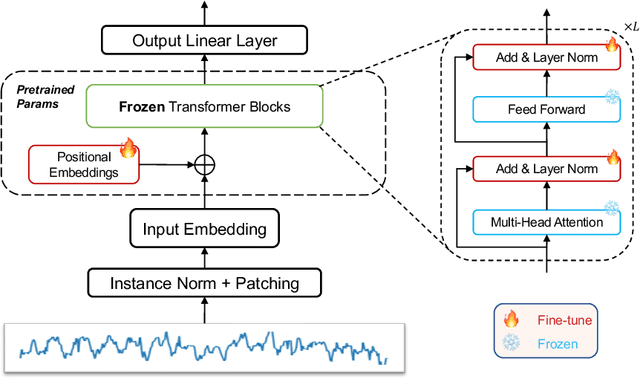
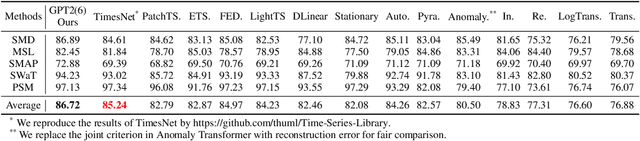
The diversity and domain dependence of time series data pose significant challenges in transferring learning to time series forecasting. In this study, we examine the effectiveness of using a transformer model that has been pre-trained on natural language or image data and then fine-tuned for time series forecasting with minimal modifications, specifically, without altering the self-attention and feedforward layers of the residual blocks. This model, known as the Frozen Pretrained Transformer (FPT), is evaluated through fine-tuning on time series forecasting tasks under Zero-Shot, Few-Shot, and normal sample size conditions. Our results demonstrate that pre-training on natural language or images can lead to a comparable or state-of-the-art performance in cross-modality time series forecasting tasks, in contrast to previous studies that focused on fine-tuning within the same modality as the pre-training data. Additionally, we provide a comprehensive theoretical analysis of the universality and the functionality of the FPT. The code is publicly available at https://anonymous.4open.science/r/Pretrained-LM-for-TSForcasting-C561.