 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Time Series Forecasting by Pretrained LM
Paper and Code
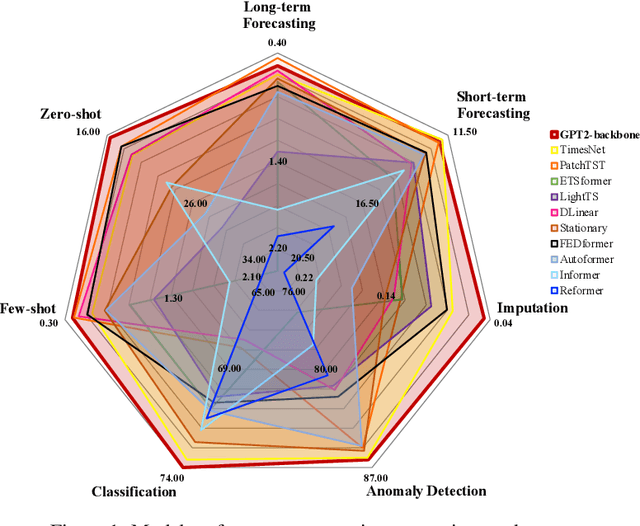

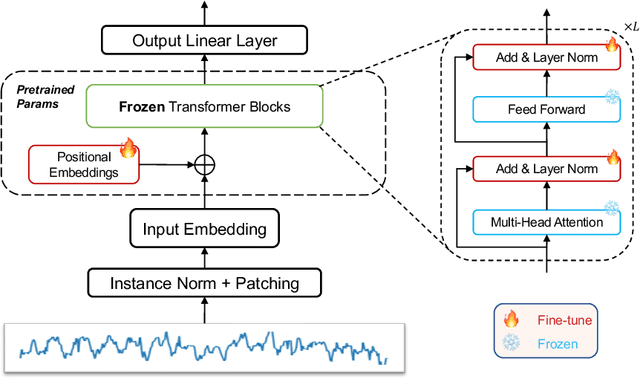
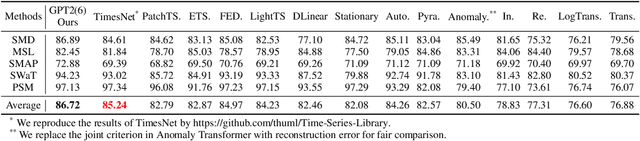
The diversity and domain dependence of time series data pose significant challenges in transferring learning to time series forecasting. In this study, we examine the effectiveness of using a transformer model that has been pre-trained on natural language or image data and then fine-tuned for time series forecasting with minimal modifications, specifically, without altering the self-attention and feedforward layers of the residual blocks. This model, known as the Frozen Pretrained Transformer (FPT), is evaluated through fine-tuning on time series forecasting tasks under Zero-Shot, Few-Shot, and normal sample size conditions. Our results demonstrate that pre-training on natural language or images can lead to a comparable or state-of-the-art performance in cross-modality time series forecasting tasks, in contrast to previous studies that focused on fine-tuning within the same modality as the pre-training data. Additionally, we provide a comprehensive theoretical analysis of the universality and the functionality of the FPT. The code is publicly available at https://anonymous.4open.science/r/Pretrained-LM-for-TSForcasting-C561.