 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Architecture: Deep Dive into Transformer Architectures for Long-Term Time Series Forecasting
Jul 17, 2025



Transformer-based models have recently become dominant in Long-term Time Series Forecasting (LTSF), yet the variations in their architecture, such as encoder-only, encoder-decoder, and decoder-only designs, raise a crucial question: What Transformer architecture works best for LTSF tasks? However, existing models are often tightly coupled with various time-series-specific designs, making it difficult to isolate the impact of the architecture itself. To address this, we propose a novel taxonomy that disentangles these designs, enabling clearer and more unified comparisons of Transformer architectures. Our taxonomy considers key aspects such as attention mechanisms, forecasting aggregations, forecasting paradigms, and normalization layers. Through extensive experiments, we uncover several key insights: bi-directional attention with joint-attention is most effective; more complete forecasting aggregation improves performance; and the direct-mapping paradigm outperforms autoregressive approaches. Furthermore, our combined model, utilizing optimal architectural choices, consistently outperforms several existing models, reinforcing the validity of our conclusions. We hope these findings offer valuable guidance for future research on Transformer architectural designs in LTSF. Our code is available at https://github.com/HALF111/TSF_architecture.
Utilizing Strategic Pre-training to Reduce Overfitting: Baguan -- A Pre-trained Weather Forecasting Model
May 20, 2025Weather forecasting has long posed a significant challenge for humanity. While recent AI-based models have surpassed traditional numerical weather prediction (NWP) methods in global forecasting tasks, overfitting remains a critical issue due to the limited availability of real-world weather data spanning only a few decades. Unlike fields like computer vision or natural language processing, where data abundance can mitigate overfitting, weather forecasting demands innovative strategies to address this challenge with existing data. In this paper, we explore pre-training methods for weather forecasting, finding that selecting an appropriately challenging pre-training task introduces locality bias, effectively mitigating overfitting and enhancing performance. We introduce Baguan, a novel data-driven model for medium-range weather forecasting, built on a Siamese Autoencoder pre-trained in a self-supervised manner and fine-tuned for different lead times. Experimental results show that Baguan outperforms traditional methods, delivering more accurate forecasts. Additionally, the pre-trained Baguan demonstrates robust overfitting control and excels in downstream tasks, such as subseasonal-to-seasonal (S2S) modeling and regional forecasting, after fine-tuning.
VisionTS: Visual Masked Autoencoders Are Free-Lunch Zero-Shot Time Series Forecasters
Aug 30, 2024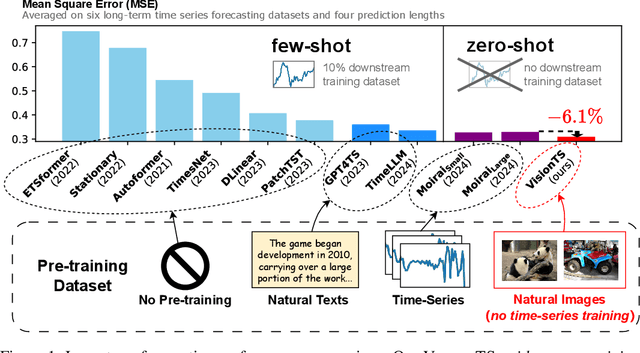
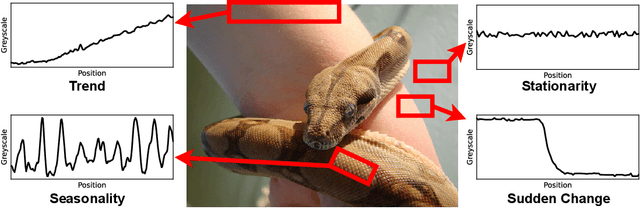
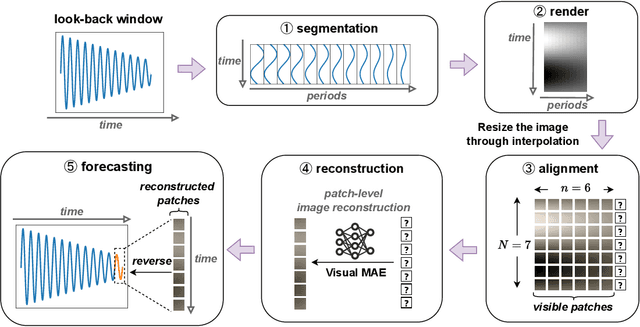
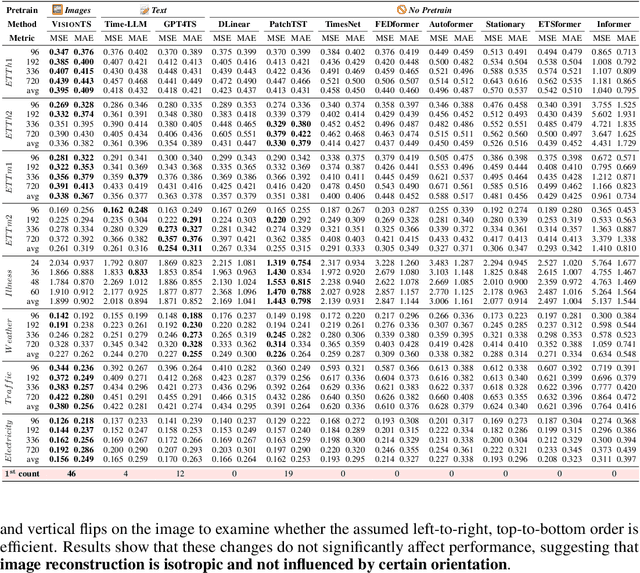
Foundation models have emerged as a promising approach in time series forecasting (TSF). Existing approaches either fine-tune large language models (LLMs) or build large-scale time-series datasets to develop TSF foundation models. However, these methods face challenges due to the severe cross-domain gap or in-domain heterogeneity. In this paper, we explore a new road to building a TSF foundation model from rich and high-quality natural images, based on the intrinsic similarities between images and time series. To bridge the gap between the two domains, we reformulate the TSF task as an image reconstruction task, which is further processed by a visual masked autoencoder (MAE) self-supervised pre-trained on the ImageNet dataset. Surprisingly, without further adaptation in the time-series domain, the proposed VisionTS could achieve superior zero-shot forecasting performance compared to existing TSF foundation models. With minimal fine-tuning, VisionTS could further improve the forecasting and achieve state-of-the-art performance in most cases. These findings suggest that visual models could be a free lunch for TSF and highlight the potential for future cross-domain research between computer vision and TSF. Our code is publicly available at https://github.com/Keytoyze/VisionTS.
Calibration of Time-Series Forecasting Transformers: Detecting and Adapting Context-Driven Distribution Shift
Oct 23, 2023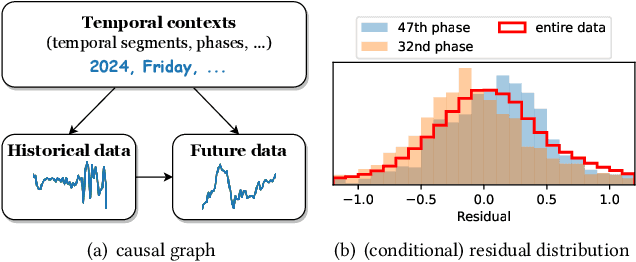
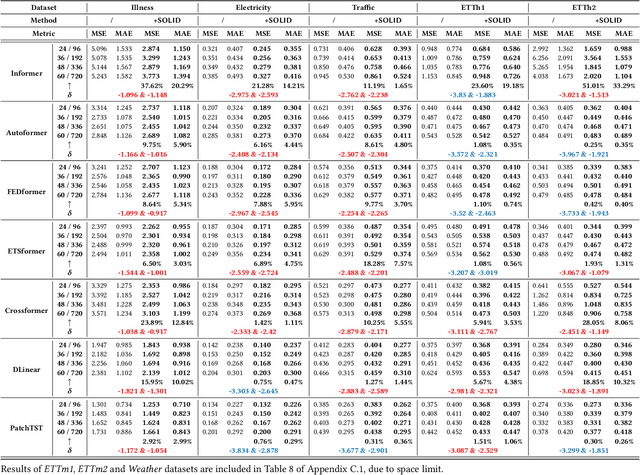
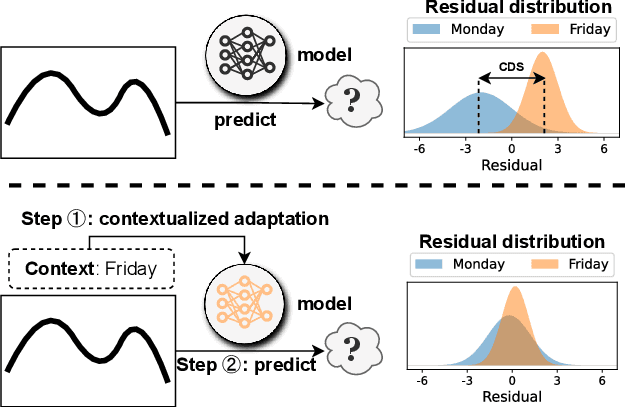
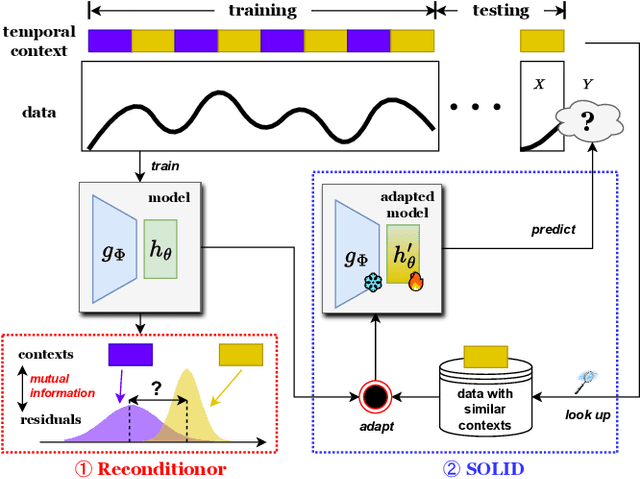
Recent years have witnessed the success of introducing Transformers to time series forecasting. From a data generation perspective, we illustrate that existing Transformers are susceptible to distribution shifts driven by temporal contexts, whether observed or unobserved. Such context-driven distribution shift (CDS) introduces biases in predictions within specific contexts and poses challenges for conventional training paradigm. In this paper, we introduce a universal calibration methodology for the detection and adaptation of CDS with a trained Transformer model. To this end, we propose a novel CDS detector, termed the "residual-based CDS detector" or "Reconditionor", which quantifies the model's vulnerability to CDS by evaluating the mutual information between prediction residuals and their corresponding contexts. A high Reconditionor score indicates a severe susceptibility, thereby necessitating model adaptation. In this circumstance, we put forth a straightforward yet potent adapter framework for model calibration, termed the "sample-level contextualized adapter" or "SOLID". This framework involves the curation of a contextually similar dataset to the provided test sample and the subsequent fine-tuning of the model's prediction layer with a limited number of steps. Our theoretical analysis demonstrates that this adaptation strategy is able to achieve an optimal equilibrium between bias and variance. Notably, our proposed Reconditionor and SOLID are model-agnostic and readily adaptable to a wide range of Transformers. Extensive experiments show that SOLID consistently enhances the performance of current SOTA Transformers on real-world datasets, especially on cases with substantial CDS detected by the proposed Reconditionor, thus validate the effectiveness of the calibration approach.