 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Frequency-Adaptive Learning for SAR Despeckling
Nov 08, 2025Synthetic Aperture Radar (SAR) images are inherently corrupted by speckle noise, limiting their utility in high-precision applications. While deep learning methods have shown promise in SAR despeckling, most methods employ a single unified network to process the entire image, failing to account for the distinct speckle statistics associated with different spatial physical characteristics. It often leads to artifacts, blurred edges, and texture distortion. To address these issues, we propose SAR-FAH, a frequency-adaptive heterogeneous despeckling model based on a divide-and-conquer architecture. First, wavelet decomposition is used to separate the image into frequency sub-bands carrying different intrinsic characteristics. Inspired by their differing noise characteristics, we design specialized sub-networks for different frequency components. The tailored approach leverages statistical variations across frequencies, improving edge and texture preservation while suppressing noise. Specifically, for the low-frequency part, denoising is formulated as a continuous dynamic system via neural ordinary differential equations, ensuring structural fidelity and sufficient smoothness that prevents artifacts. For high-frequency sub-bands rich in edges and textures, we introduce an enhanced U-Net with deformable convolutions for noise suppression and enhanced features. Extensive experiments on synthetic and real SAR images validate the superior performance of the proposed model in noise removal and structural preservation.
Utilizing Strategic Pre-training to Reduce Overfitting: Baguan -- A Pre-trained Weather Forecasting Model
May 20, 2025Weather forecasting has long posed a significant challenge for humanity. While recent AI-based models have surpassed traditional numerical weather prediction (NWP) methods in global forecasting tasks, overfitting remains a critical issue due to the limited availability of real-world weather data spanning only a few decades. Unlike fields like computer vision or natural language processing, where data abundance can mitigate overfitting, weather forecasting demands innovative strategies to address this challenge with existing data. In this paper, we explore pre-training methods for weather forecasting, finding that selecting an appropriately challenging pre-training task introduces locality bias, effectively mitigating overfitting and enhancing performance. We introduce Baguan, a novel data-driven model for medium-range weather forecasting, built on a Siamese Autoencoder pre-trained in a self-supervised manner and fine-tuned for different lead times. Experimental results show that Baguan outperforms traditional methods, delivering more accurate forecasts. Additionally, the pre-trained Baguan demonstrates robust overfitting control and excels in downstream tasks, such as subseasonal-to-seasonal (S2S) modeling and regional forecasting, after fine-tuning.
Design and Control of A Tilt-Rotor Tailsitter Aircraft with Pivoting VTOL Capability
Mar 04, 2025Tailsitter aircraft attract considerable interest due to their capabilities of both agile hover and high speed forward flight. However, traditional tailsitters that use aerodynamic control surfaces face the challenge of limited control effectiveness and associated actuator saturation during vertical flight and transitions. Conversely, tailsitters relying solely on tilting rotors have the drawback of insufficient roll control authority in forward flight. This paper proposes a tilt-rotor tailsitter aircraft with both elevons and tilting rotors as a promising solution. By implementing a cascaded weighted least squares (WLS) based incremental nonlinear dynamic inversion (INDI) controller, the drone successfully achieved autonomous waypoint tracking in outdoor experiments at a cruise airspeed of 16 m/s, including transitions between forward flight and hover without actuator saturation. Wind tunnel experiments confirm improved roll control compared to tilt-rotor-only configurations, while comparative outdoor flight tests highlight the vehicle's superior control over elevon-only designs during critical phases such as vertical descent and transitions. Finally, we also show that the tilt-rotors allow for an autonomous takeoff and landing with a unique pivoting capability that demonstrates stability and robustness under wind disturbances.
FusionSF: Fuse Heterogeneous Modalities in a Vector Quantized Framework for Robust Solar Power Forecasting
Feb 08, 2024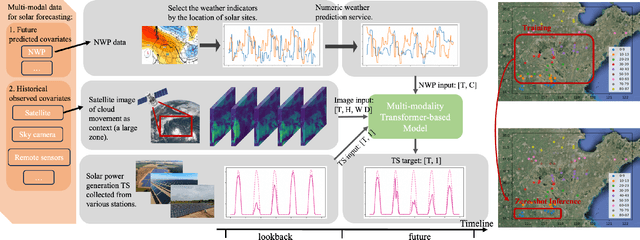
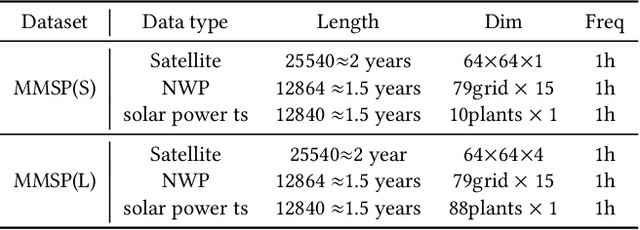
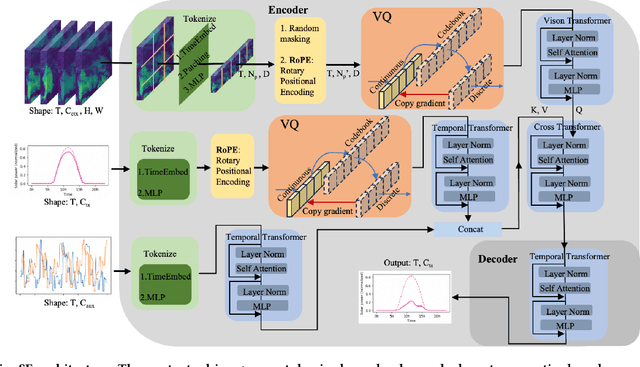
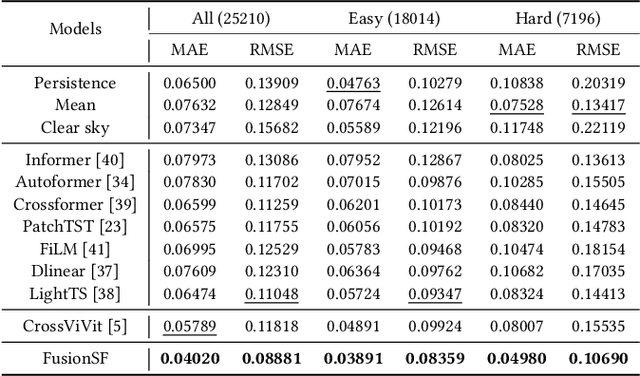
Accurate solar power forecasting is crucial to integrate photovoltaic plants into the electric grid, schedule and secure the power grid safety. This problem becomes more demanding for those newly installed solar plants which lack sufficient data. Current research predominantly relies on historical solar power data or numerical weather prediction in a single-modality format, ignoring the complementary information provided in different modalities. In this paper, we propose a multi-modality fusion framework to integrate historical power data, numerical weather prediction, and satellite images, significantly improving forecast performance. We introduce a vector quantized framework that aligns modalities with varying information densities, striking a balance between integrating sufficient information and averting model overfitting. Our framework demonstrates strong zero-shot forecasting capability, which is especially useful for those newly installed plants. Moreover, we collect and release a multi-modal solar power (MMSP) dataset from real-world plants to further promote the research of multi-modal solar forecasting algorithms. Our extensive experiments show that our model not only operates with robustness but also boosts accuracy in both zero-shot forecasting and scenarios rich with training data, surpassing leading models. We have incorporated it into our eForecaster platform and deployed it for more than 300 solar plants with a capacity of over 15GW.
SaDI: A Self-adaptive Decomposed Interpretable Framework for Electric Load Forecasting under Extreme Events
Jun 14, 2023
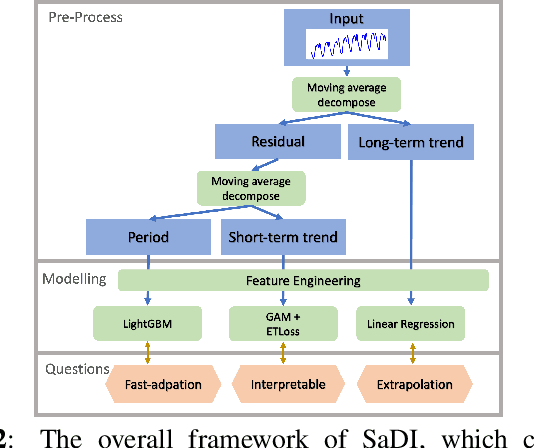

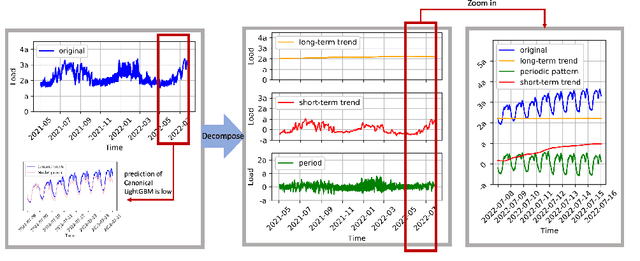
Accurate prediction of electric load is crucial in power grid planning and management. In this paper, we solve the electric load forecasting problem under extreme events such as scorching heats. One challenge for accurate forecasting is the lack of training samples under extreme conditions. Also load usually changes dramatically in these extreme conditions, which calls for interpretable model to make better decisions. In this paper, we propose a novel forecasting framework, named Self-adaptive Decomposed Interpretable framework~(SaDI), which ensembles long-term trend, short-term trend, and period modelings to capture temporal characteristics in different components. The external variable triggered loss is proposed for the imbalanced learning under extreme events. Furthermore, Generalized Additive Model (GAM) is employed in the framework for desirable interpretability. The experiments on both Central China electric load and public energy meters from buildings show that the proposed SaDI framework achieves average 22.14% improvement compared with the current state-of-the-art algorithms in forecasting under extreme events in terms of daily mean of normalized RMSE. Code, Public datasets, and Appendix are available at: https://doi.org/10.24433/CO.9696980.v1 .
GCformer: An Efficient Framework for Accurate and Scalable Long-Term Multivariate Time Series Forecasting
Jun 14, 2023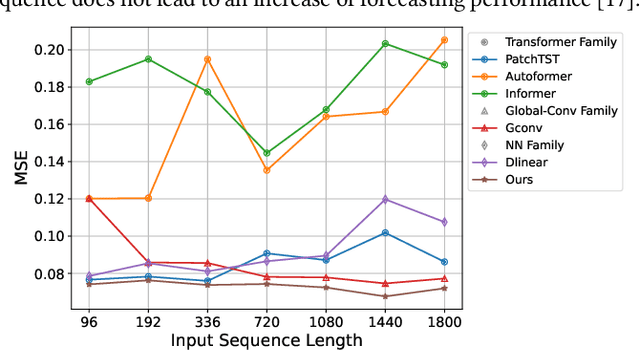

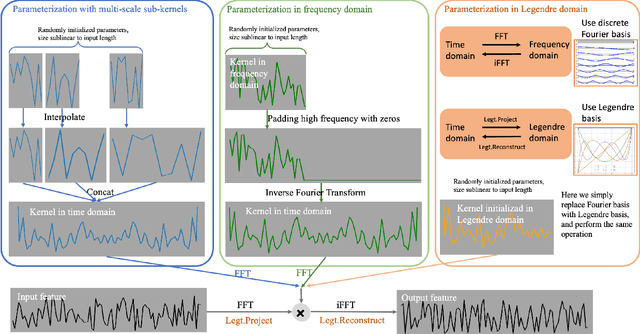

Transformer-based models have emerged as promising tools for time series forecasting. However, these model cannot make accurate prediction for long input time series. On the one hand, they failed to capture global dependencies within time series data. On the other hand, the long input sequence usually leads to large model size and high time complexity. To address these limitations, we present GCformer, which combines a structured global convolutional branch for processing long input sequences with a local Transformer-based branch for capturing short, recent signals. A cohesive framework for a global convolution kernel has been introduced, utilizing three distinct parameterization methods. The selected structured convolutional kernel in the global branch has been specifically crafted with sublinear complexity, thereby allowing for the efficient and effective processing of lengthy and noisy input signals. Empirical studies on six benchmark datasets demonstrate that GCformer outperforms state-of-the-art methods, reducing MSE error in multivariate time series benchmarks by 4.38% and model parameters by 61.92%. In particular, the global convolutional branch can serve as a plug-in block to enhance the performance of other models, with an average improvement of 31.93\%, including various recently published Transformer-based models. Our code is publicly available at https://github.com/zyj-111/GCformer.
TreeDRNet:A Robust Deep Model for Long Term Time Series Forecasting
Jun 24, 2022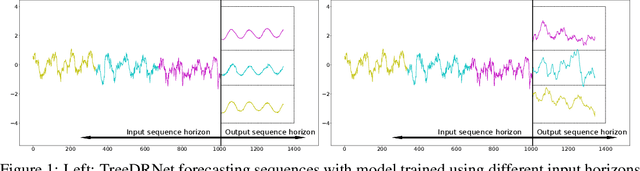
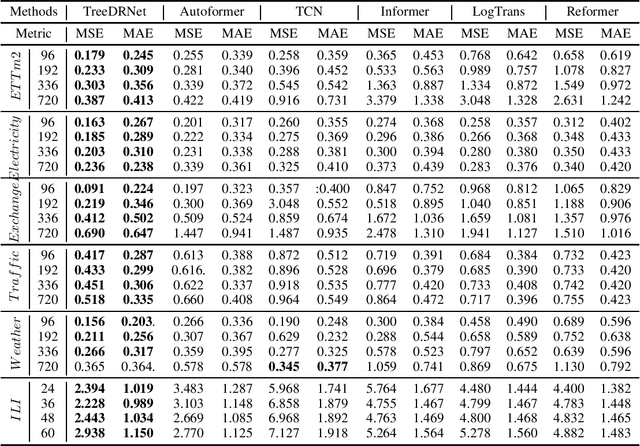
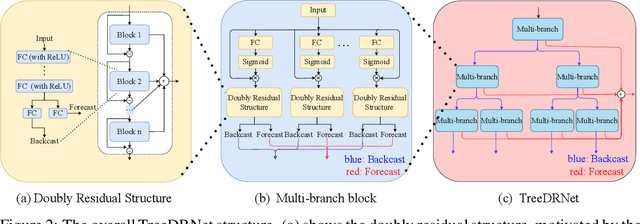

Various deep learning models, especially some latest Transformer-based approaches, have greatly improved the state-of-art performance for long-term time series forecasting.However, those transformer-based models suffer a severe deterioration performance with prolonged input length, which prohibits them from using extended historical info.Moreover, these methods tend to handle complex examples in long-term forecasting with increased model complexity, which often leads to a significant increase in computation and less robustness in performance(e.g., overfitting). We propose a novel neural network architecture, called TreeDRNet, for more effective long-term forecasting. Inspired by robust regression, we introduce doubly residual link structure to make prediction more robust.Built upon Kolmogorov-Arnold representation theorem, we explicitly introduce feature selection, model ensemble, and a tree structure to further utilize the extended input sequence, which improves the robustness and representation power of TreeDRNet. Unlike previous deep models for sequential forecasting work, TreeDRNet is built entirely on multilayer perceptron and thus enjoys high computational efficiency. Our extensive empirical studies show that TreeDRNet is significantly more effective than state-of-the-art methods, reducing prediction errors by 20% to 40% for multivariate time series. In particular, TreeDRNet is over 10 times more efficient than transformer-based methods. The code will be released soon.
FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting
May 24, 2022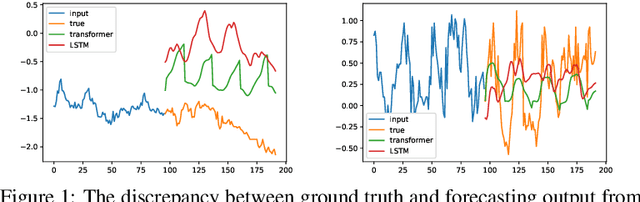
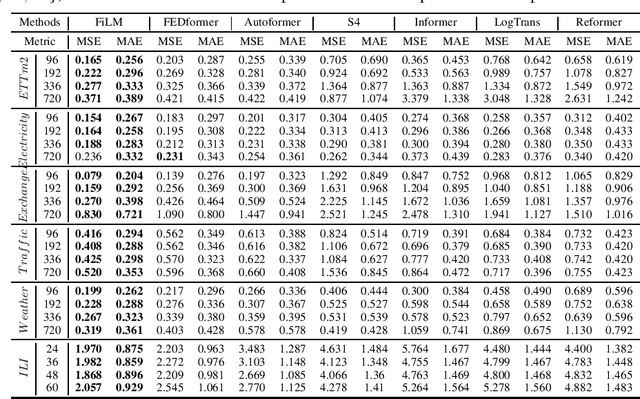
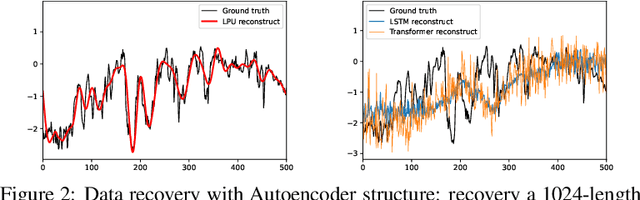
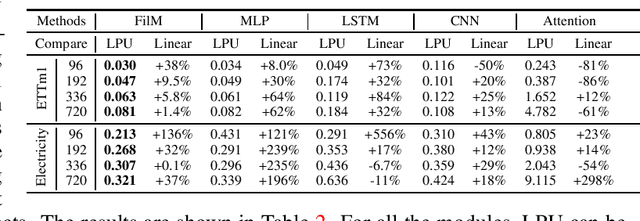
Recent studies have shown that deep learning models such as RNNs and Transformers have brought significant performance gains for long-term forecasting of time series because they effectively utilize historical information. We found, however, that there is still great room for improvement in how to preserve historical information in neural networks while avoiding overfitting to noise presented in the history. Addressing this allows better utilization of the capabilities of deep learning models. To this end, we design a \textbf{F}requency \textbf{i}mproved \textbf{L}egendre \textbf{M}emory model, or {\bf FiLM}: it applies Legendre Polynomials projections to approximate historical information, uses Fourier projection to remove noise, and adds a low-rank approximation to speed up computation. Our empirical studies show that the proposed FiLM significantly improves the accuracy of state-of-the-art models in multivariate and univariate long-term forecasting by (\textbf{20.3\%}, \textbf{22.6\%}), respectively. We also demonstrate that the representation module developed in this work can be used as a general plug-in to improve the long-term prediction performance of other deep learning modules. Code will be released soon.
Transformers in Time Series: A Survey
Mar 07, 2022
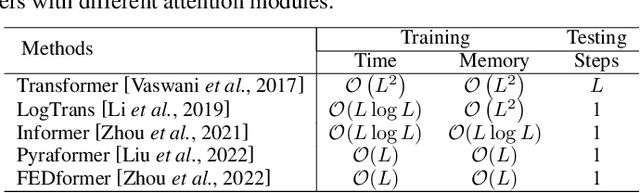

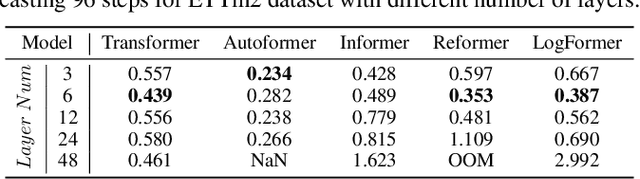
Transformers have achieved superior performances in many tasks in natural language processing and computer vision, which also intrigues great interests in the time series community. Among multiple advantages of transformers, the ability to capture long-range dependencies and interactions is especially attractive for time series modeling, leading to exciting progress in various time series applications. In this paper, we systematically review transformer schemes for time series modeling by highlighting their strengths as well as limitations through a new taxonomy to summarize existing time series transformers in two perspectives. From the perspective of network modifications, we summarize the adaptations of module level and architecture level of the time series transformers. From the perspective of applications, we categorize time series transformers based on common tasks including forecasting, anomaly detection, and classification. Empirically, we perform robust analysis, model size analysis, and seasonal-trend decomposition analysis to study how Transformers perform in time series. Finally, we discuss and suggest future directions to provide useful research guidance. A corresponding resource list that will be continuously updated can be found in the GitHub repository. To the best of our knowledge, this paper is the first work to comprehensively and systematically summarize the recent advances of Transformers for modeling time series data. We hope this survey will ignite further research interests in time series Transformers.
FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting
Jan 30, 2022

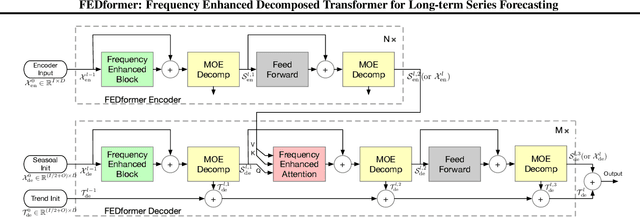

Although Transformer-based methods have significantly improved state-of-the-art results for long-term series forecasting, they are not only computationally expensive but more importantly, are unable to capture the global view of time series (e.g. overall trend). To address these problems, we propose to combine Transformer with the seasonal-trend decomposition method, in which the decomposition method captures the global profile of time series while Transformers capture more detailed structures. To further enhance the performance of Transformer for long-term prediction, we exploit the fact that most time series tend to have a sparse representation in well-known basis such as Fourier transform, and develop a frequency enhanced Transformer. Besides being more effective, the proposed method, termed as Frequency Enhanced Decomposed Transformer ({\bf FEDformer}), is more efficient than standard Transformer with a linear complexity to the sequence length. Our empirical studies with six benchmark datasets show that compared with state-of-the-art methods, FEDformer can reduce prediction error by $14.8\%$ and $22.6\%$ for multivariate and univariate time series, respectively. the code will be released soon.