 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Time-series Forecasting Needs Kernelized Moment Balancing
Jan 31, 2026Deep time-series forecasting can be formulated as a distribution balancing problem aimed at aligning the distribution of the forecasts and ground truths. According to Imbens' criterion, true distribution balance requires matching the first moments with respect to any balancing function. We demonstrate that existing objectives fail to meet this criterion, as they enforce moment matching only for one or two predefined balancing functions, thus failing to achieve full distribution balance. To address this limitation, we propose direct forecasting with kernelized moment balancing (KMB-DF). Unlike existing objectives, KMB-DF adaptively selects the most informative balancing functions from a reproducing kernel hilbert space (RKHS) to enforce sufficient distribution balancing. We derive a tractable and differentiable objective that enables efficient estimation from empirical samples and seamless integration into gradient-based training pipelines. Extensive experiments across multiple models and datasets show that KMB-DF consistently improves forecasting accuracy and achieves state-of-the-art performance. Code is available at https://anonymous.4open.science/r/KMB-DF-403C.
Breaking the Regional Barrier: Inductive Semantic Topology Learning for Worldwide Air Quality Forecasting
Jan 29, 2026Global air quality forecasting grapples with extreme spatial heterogeneity and the poor generalization of existing transductive models to unseen regions. To tackle this, we propose OmniAir, a semantic topology learning framework tailored for global station-level prediction. By encoding invariant physical environmental attributes into generalizable station identities and dynamically constructing adaptive sparse topologies, our approach effectively captures long-range non-Euclidean correlations and physical diffusion patterns across unevenly distributed global networks. We further curate WorldAir, a massive dataset covering over 7,800 stations worldwide. Extensive experiments show that OmniAir achieves state-of-the-art performance against 18 baselines, maintaining high efficiency and scalability with speeds nearly 10 times faster than existing models, while effectively bridging the monitoring gap in data-sparse regions.
DropoutTS: Sample-Adaptive Dropout for Robust Time Series Forecasting
Jan 29, 2026Deep time series models are vulnerable to noisy data ubiquitous in real-world applications. Existing robustness strategies either prune data or rely on costly prior quantification, failing to balance effectiveness and efficiency. In this paper, we introduce DropoutTS, a model-agnostic plugin that shifts the paradigm from "what" to learn to "how much" to learn. DropoutTS employs a Sample-Adaptive Dropout mechanism: leveraging spectral sparsity to efficiently quantify instance-level noise via reconstruction residuals, it dynamically calibrates model learning capacity by mapping noise to adaptive dropout rates - selectively suppressing spurious fluctuations while preserving fine-grained fidelity. Extensive experiments across diverse noise regimes and open benchmarks show DropoutTS consistently boosts superior backbones' performance, delivering advanced robustness with negligible parameter overhead and no architectural modifications. Our code is available at https://github.com/CityMind-Lab/DropoutTS.
HearSay Benchmark: Do Audio LLMs Leak What They Hear?
Jan 07, 2026While Audio Large Language Models (ALLMs) have achieved remarkable progress in understanding and generation, their potential privacy implications remain largely unexplored. This paper takes the first step to investigate whether ALLMs inadvertently leak user privacy solely through acoustic voiceprints and introduces $\textit{HearSay}$, a comprehensive benchmark constructed from over 22,000 real-world audio clips. To ensure data quality, the benchmark is meticulously curated through a rigorous pipeline involving automated profiling and human verification, guaranteeing that all privacy labels are grounded in factual records. Extensive experiments on $\textit{HearSay}$ yield three critical findings: $\textbf{Significant Privacy Leakage}$: ALLMs inherently extract private attributes from voiceprints, reaching 92.89% accuracy on gender and effectively profiling social attributes. $\textbf{Insufficient Safety Mechanisms}$: Alarmingly, existing safeguards are severely inadequate; most models fail to refuse privacy-intruding requests, exhibiting near-zero refusal rates for physiological traits. $\textbf{Reasoning Amplifies Risk}$: Chain-of-Thought (CoT) reasoning exacerbates privacy risks in capable models by uncovering deeper acoustic correlations. These findings expose critical vulnerabilities in ALLMs, underscoring the urgent need for targeted privacy alignment. The codes and dataset are available at https://github.com/JinWang79/HearSay_Benchmark
Advanced Global Wildfire Activity Modeling with Hierarchical Graph ODE
Jan 04, 2026Wildfires, as an integral component of the Earth system, are governed by a complex interplay of atmospheric, oceanic, and terrestrial processes spanning a vast range of spatiotemporal scales. Modeling their global activity on large timescales is therefore a critical yet challenging task. While deep learning has recently achieved significant breakthroughs in global weather forecasting, its potential for global wildfire behavior prediction remains underexplored. In this work, we reframe this problem and introduce the Hierarchical Graph ODE (HiGO), a novel framework designed to learn the multi-scale, continuous-time dynamics of wildfires. Specifically, we represent the Earth system as a multi-level graph hierarchy and propose an adaptive filtering message passing mechanism for both intra- and inter-level information flow, enabling more effective feature extraction and fusion. Furthermore, we incorporate GNN-parameterized Neural ODE modules at multiple levels to explicitly learn the continuous dynamics inherent to each scale. Through extensive experiments on the SeasFire Cube dataset, we demonstrate that HiGO significantly outperforms state-of-the-art baselines on long-range wildfire forecasting. Moreover, its continuous-time predictions exhibit strong observational consistency, highlighting its potential for real-world applications.
Digital Twin AI: Opportunities and Challenges from Large Language Models to World Models
Jan 04, 2026Digital twins, as precise digital representations of physical systems, have evolved from passive simulation tools into intelligent and autonomous entities through the integration of artificial intelligence technologies. This paper presents a unified four-stage framework that systematically characterizes AI integration across the digital twin lifecycle, spanning modeling, mirroring, intervention, and autonomous management. By synthesizing existing technologies and practices, we distill a unified four-stage framework that systematically characterizes how AI methodologies are embedded across the digital twin lifecycle: (1) modeling the physical twin through physics-based and physics-informed AI approaches, (2) mirroring the physical system into a digital twin with real-time synchronization, (3) intervening in the physical twin through predictive modeling, anomaly detection, and optimization strategies, and (4) achieving autonomous management through large language models, foundation models, and intelligent agents. We analyze the synergy between physics-based modeling and data-driven learning, highlighting the shift from traditional numerical solvers to physics-informed and foundation models for physical systems. Furthermore, we examine how generative AI technologies, including large language models and generative world models, transform digital twins into proactive and self-improving cognitive systems capable of reasoning, communication, and creative scenario generation. Through a cross-domain review spanning eleven application domains, including healthcare, aerospace, smart manufacturing, robotics, and smart cities, we identify common challenges related to scalability, explainability, and trustworthiness, and outline directions for responsible AI-driven digital twin systems.
The Procrustean Bed of Time Series: The Optimization Bias of Point-wise Loss
Dec 21, 2025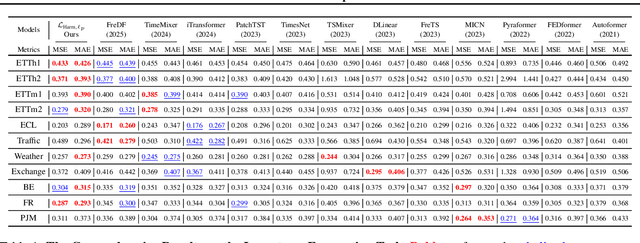
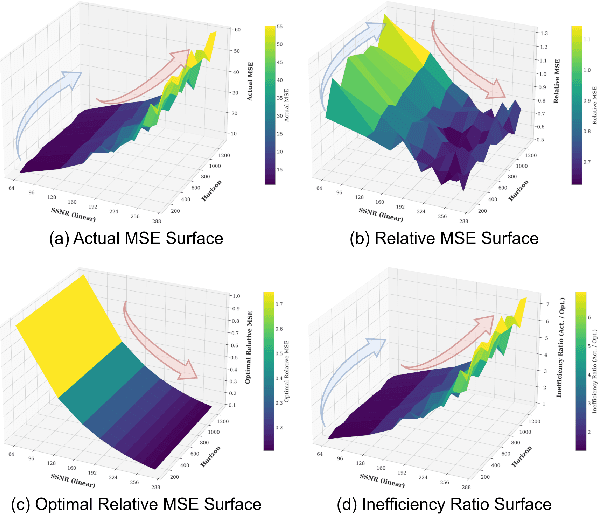
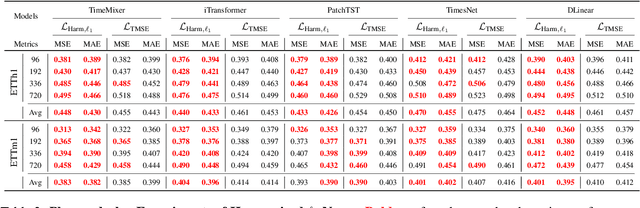
Optimizing time series models via point-wise loss functions (e.g., MSE) relying on a flawed point-wise independent and identically distributed (i.i.d.) assumption that disregards the causal temporal structure, an issue with growing awareness yet lacking formal theoretical grounding. Focusing on the core independence issue under covariance stationarity, this paper aims to provide a first-principles analysis of the Expectation of Optimization Bias (EOB), formalizing it information-theoretically as the discrepancy between the true joint distribution and its flawed i.i.d. counterpart. Our analysis reveals a fundamental paradigm paradox: the more deterministic and structured the time series, the more severe the bias by point-wise loss function. We derive the first closed-form quantification for the non-deterministic EOB across linear and non-linear systems, and prove EOB is an intrinsic data property, governed exclusively by sequence length and our proposed Structural Signal-to-Noise Ratio (SSNR). This theoretical diagnosis motivates our principled debiasing program that eliminates the bias through sequence length reduction and structural orthogonalization. We present a concrete solution that simultaneously achieves both principles via DFT or DWT. Furthermore, a novel harmonized $\ell_p$ norm framework is proposed to rectify gradient pathologies of high-variance series. Extensive experiments validate EOB Theory's generality and the superior performance of debiasing program.
CaPulse: Detecting Anomalies by Tuning in to the Causal Rhythms of Time Series
Aug 06, 2025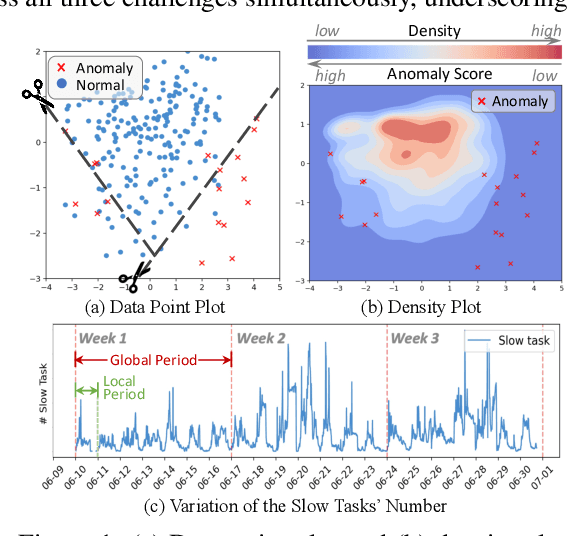
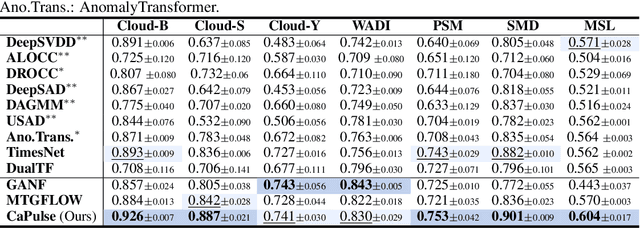

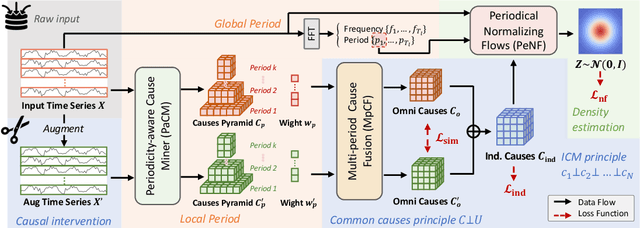
Time series anomaly detection has garnered considerable attention across diverse domains. While existing methods often fail to capture the underlying mechanisms behind anomaly generation in time series data. In addition, time series anomaly detection often faces several data-related inherent challenges, i.e., label scarcity, data imbalance, and complex multi-periodicity. In this paper, we leverage causal tools and introduce a new causality-based framework, CaPulse, which tunes in to the underlying causal pulse of time series data to effectively detect anomalies. Concretely, we begin by building a structural causal model to decipher the generation processes behind anomalies. To tackle the challenges posed by the data, we propose Periodical Normalizing Flows with a novel mask mechanism and carefully designed periodical learners, creating a periodicity-aware, density-based anomaly detection approach. Extensive experiments on seven real-world datasets demonstrate that CaPulse consistently outperforms existing methods, achieving AUROC improvements of 3% to 17%, with enhanced interpretability.
From Entanglement to Alignment: Representation Space Decomposition for Unsupervised Time Series Domain Adaptation
Jul 28, 2025Domain shift poses a fundamental challenge in time series analysis, where models trained on source domain often fail dramatically when applied in target domain with different yet similar distributions. While current unsupervised domain adaptation (UDA) methods attempt to align cross-domain feature distributions, they typically treat features as indivisible entities, ignoring their intrinsic compositions that governs domain adaptation. We introduce DARSD, a novel UDA framework with theoretical explainability that explicitly realizes UDA tasks from the perspective of representation space decomposition. Our core insight is that effective domain adaptation requires not just alignment, but principled disentanglement of transferable knowledge from mixed representations. DARSD consists three synergistic components: (I) An adversarial learnable common invariant basis that projects original features into a domain-invariant subspace while preserving semantic content; (II) A prototypical pseudo-labeling mechanism that dynamically separates target features based on confidence, hindering error accumulation; (III) A hybrid contrastive optimization strategy that simultaneously enforces feature clustering and consistency while mitigating emerging distribution gaps. Comprehensive experiments conducted on four benchmark datasets (WISDM, HAR, HHAR, and MFD) demonstrate DARSD's superiority against 12 UDA algorithms, achieving optimal performance in 35 out of 53 cross-domain scenarios.
Cross-Domain Conditional Diffusion Models for Time Series Imputation
Jun 14, 2025Cross-domain time series imputation is an underexplored data-centric research task that presents significant challenges, particularly when the target domain suffers from high missing rates and domain shifts in temporal dynamics. Existing time series imputation approaches primarily focus on the single-domain setting, which cannot effectively adapt to a new domain with domain shifts. Meanwhile, conventional domain adaptation techniques struggle with data incompleteness, as they typically assume the data from both source and target domains are fully observed to enable adaptation. For the problem of cross-domain time series imputation, missing values introduce high uncertainty that hinders distribution alignment, making existing adaptation strategies ineffective. Specifically, our proposed solution tackles this problem from three perspectives: (i) Data: We introduce a frequency-based time series interpolation strategy that integrates shared spectral components from both domains while retaining domain-specific temporal structures, constructing informative priors for imputation. (ii) Model: We design a diffusion-based imputation model that effectively learns domain-shared representations and captures domain-specific temporal dependencies with dedicated denoising networks. (iii) Algorithm: We further propose a cross-domain consistency alignment strategy that selectively regularizes output-level domain discrepancies, enabling effective knowledge transfer while preserving domain-specific characteristics. Extensive experiments on three real-world datasets demonstrate the superiority of our proposed approach. Our code implementation is available here.