 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Personalization: Prompt Optimization for Recommendation Reranking
Apr 04, 2025Modern recommender systems increasingly leverage large language models (LLMs) for reranking to improve personalization. However, existing approaches face two key limitations: (1) heavy reliance on manually crafted prompts that are difficult to scale, and (2) inadequate handling of unstructured item metadata that complicates preference inference. We present AGP (Auto-Guided Prompt Refinement), a novel framework that automatically optimizes user profile generation prompts for personalized reranking. AGP introduces two key innovations: (1) position-aware feedback mechanisms for precise ranking correction, and (2) batched training with aggregated feedback to enhance generalization.
Training Large Recommendation Models via Graph-Language Token Alignment
Feb 26, 2025



Recommender systems (RS) have become essential tools for helping users efficiently navigate the overwhelming amount of information on e-commerce and social platforms. However, traditional RS relying on Collaborative Filtering (CF) struggles to integrate the rich semantic information from textual data. Meanwhile, large language models (LLMs) have shown promising results in natural language processing, but directly using LLMs for recommendation introduces challenges, such as ambiguity in generating item predictions and inefficiencies in scalability. In this paper, we propose a novel framework to train Large Recommendation models via Graph-Language Token Alignment. By aligning item and user nodes from the interaction graph with pretrained LLM tokens, GLTA effectively leverages the reasoning abilities of LLMs. Furthermore, we introduce Graph-Language Logits Matching (GLLM) to optimize token alignment for end-to-end item prediction, eliminating ambiguity in the free-form text as recommendation results. Extensive experiments on three benchmark datasets demonstrate the effectiveness of GLTA, with ablation studies validating each component.
PCL: Prompt-based Continual Learning for User Modeling in Recommender Systems
Feb 26, 2025



User modeling in large e-commerce platforms aims to optimize user experiences by incorporating various customer activities. Traditional models targeting a single task often focus on specific business metrics, neglecting the comprehensive user behavior, and thus limiting their effectiveness. To develop more generalized user representations, some existing work adopts Multi-task Learning (MTL)approaches. But they all face the challenges of optimization imbalance and inefficiency in adapting to new tasks. Continual Learning (CL), which allows models to learn new tasks incrementally and independently, has emerged as a solution to MTL's limitations. However, CL faces the challenge of catastrophic forgetting, where previously learned knowledge is lost when the model is learning the new task. Inspired by the success of prompt tuning in Pretrained Language Models (PLMs), we propose PCL, a Prompt-based Continual Learning framework for user modeling, which utilizes position-wise prompts as external memory for each task, preserving knowledge and mitigating catastrophic forgetting. Additionally, we design contextual prompts to capture and leverage inter-task relationships during prompt tuning. We conduct extensive experiments on real-world datasets to demonstrate PCL's effectiveness.
Instruction-based Hypergraph Pretraining
Mar 28, 2024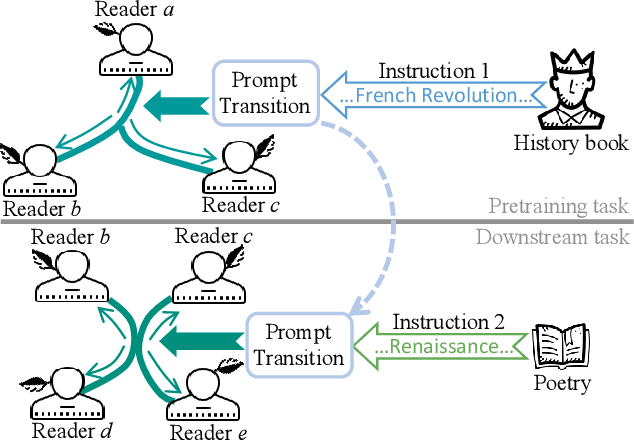



Pretraining has been widely explored to augment the adaptability of graph learning models to transfer knowledge from large datasets to a downstream task, such as link prediction or classification. However, the gap between training objectives and the discrepancy between data distributions in pretraining and downstream tasks hinders the transfer of the pretrained knowledge. Inspired by instruction-based prompts widely used in pretrained language models, we introduce instructions into graph pretraining. In this paper, we propose a novel pretraining framework named Instruction-based Hypergraph Pretraining. To overcome the discrepancy between pretraining and downstream tasks, text-based instructions are applied to provide explicit guidance on specific tasks for representation learning. Compared to learnable prompts, whose effectiveness depends on the quality and the diversity of training data, text-based instructions intrinsically encapsulate task information and support the model to generalize beyond the structure seen during pretraining. To capture high-order relations with task information in a context-aware manner, a novel prompting hypergraph convolution layer is devised to integrate instructions into information propagation in hypergraphs. Extensive experiments conducted on three public datasets verify the superiority of IHP in various scenarios.
Multi-view Graph Convolution for Participant Recommendation
Nov 20, 2023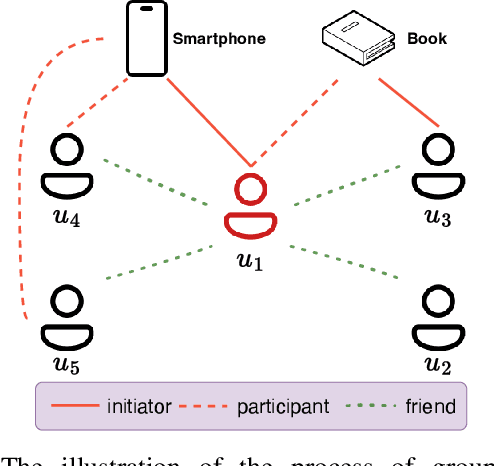
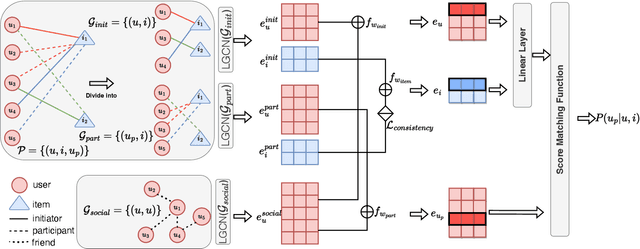
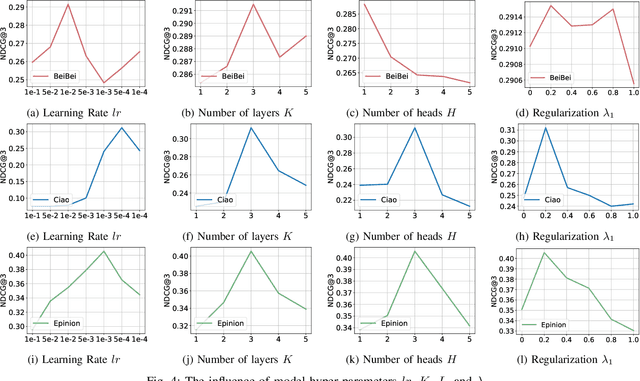
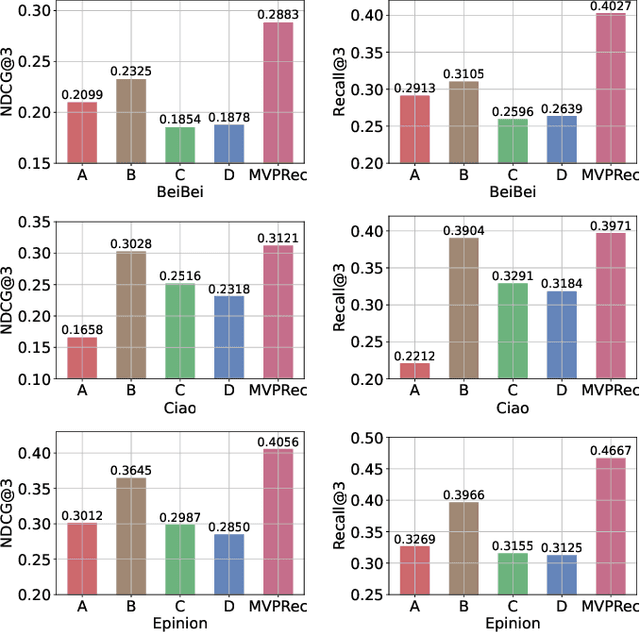
Social networks have become essential for people's lives. The proliferation of web services further expands social networks at an unprecedented scale, leading to immeasurable commercial value for online platforms. Recently, the group buying (GB) business mode is prevalent and also becoming more popular in E-commerce. GB explicitly forms groups of users with similar interests to secure better discounts from the merchants, often operating within social networks. It is a novel way to further unlock the commercial value by explicitly utilizing the online social network in E-commerce. Participant recommendation, a fundamental problem emerging together with GB, aims to find the participants for a launched group buying process with an initiator and a target item to increase the GB success rate. This paper proposes Multi-View Graph Convolution for Participant Recommendation (MVPRec) to tackle this problem. To differentiate the roles of users (Initiator/Participant) within the GB process, we explicitly reconstruct historical GB data into initiator-view and participant-view graphs. Together with the social graph, we obtain a multi-view user representation with graph encoders. Then MVPRec fuses the GB and social representation with an attention module to obtain the user representation and learns a matching score with the initiator's social friends via a multi-head attention mechanism. Social friends with the Top-k matching score are recommended for the corresponding GB process. Experiments on three datasets justify the effectiveness of MVPRec in the emerging participant recommendation problem.
Group-Aware Interest Disentangled Dual-Training for Personalized Recommendation
Nov 16, 2023


Personalized recommender systems aim to predict users' preferences for items. It has become an indispensable part of online services. Online social platforms enable users to form groups based on their common interests. The users' group participation on social platforms reveals their interests and can be utilized as side information to mitigate the data sparsity and cold-start problem in recommender systems. Users join different groups out of different interests. In this paper, we generate group representation from the user's interests and propose IGRec (Interest-based Group enhanced Recommendation) to utilize the group information accurately. It consists of four modules. (1) Interest disentangler via self-gating that disentangles users' interests from their initial embedding representation. (2) Interest aggregator that generates the interest-based group representation by Gumbel-Softmax aggregation on the group members' interests. (3) Interest-based group aggregation that fuses user's representation with the participated group representation. (4) A dual-trained rating prediction module to utilize both user-item and group-item interactions. We conduct extensive experiments on three publicly available datasets. Results show IGRec can effectively alleviate the data sparsity problem and enhance the recommender system with interest-based group representation. Experiments on the group recommendation task further show the informativeness of interest-based group representation.
Unified Pretraining for Recommendation via Task Hypergraphs
Oct 20, 2023

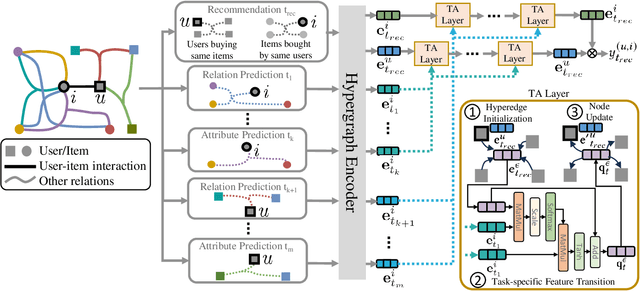

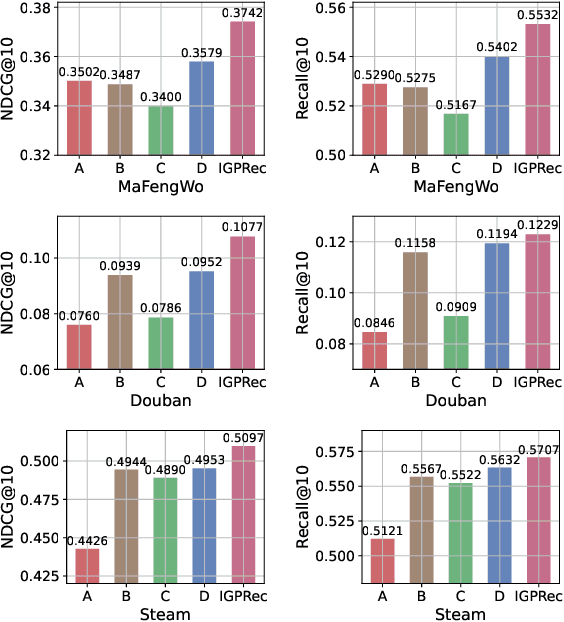
Although pretraining has garnered significant attention and popularity in recent years, its application in graph-based recommender systems is relatively limited. It is challenging to exploit prior knowledge by pretraining in widely used ID-dependent datasets. On one hand, user-item interaction history in one dataset can hardly be transferred to other datasets through pretraining, where IDs are different. On the other hand, pretraining and finetuning on the same dataset leads to a high risk of overfitting. In this paper, we propose a novel multitask pretraining framework named Unified Pretraining for Recommendation via Task Hypergraphs. For a unified learning pattern to handle diverse requirements and nuances of various pretext tasks, we design task hypergraphs to generalize pretext tasks to hyperedge prediction. A novel transitional attention layer is devised to discriminatively learn the relevance between each pretext task and recommendation. Experimental results on three benchmark datasets verify the superiority of UPRTH. Additional detailed investigations are conducted to demonstrate the effectiveness of the proposed framework.
Knowledge Graph Context-Enhanced Diversified Recommendation
Oct 20, 2023



The field of Recommender Systems (RecSys) has been extensively studied to enhance accuracy by leveraging users' historical interactions. Nonetheless, this persistent pursuit of accuracy frequently engenders diminished diversity, culminating in the well-recognized "echo chamber" phenomenon. Diversified RecSys has emerged as a countermeasure, placing diversity on par with accuracy and garnering noteworthy attention from academic circles and industry practitioners. This research explores the realm of diversified RecSys within the intricate context of knowledge graphs (KG). These KGs act as repositories of interconnected information concerning entities and items, offering a propitious avenue to amplify recommendation diversity through the incorporation of insightful contextual information. Our contributions include introducing an innovative metric, Entity Coverage, and Relation Coverage, which effectively quantifies diversity within the KG domain. Additionally, we introduce the Diversified Embedding Learning (DEL) module, meticulously designed to formulate user representations that possess an innate awareness of diversity. In tandem with this, we introduce a novel technique named Conditional Alignment and Uniformity (CAU). It adeptly encodes KG item embeddings while preserving contextual integrity. Collectively, our contributions signify a substantial stride towards augmenting the panorama of recommendation diversity within the realm of KG-informed RecSys paradigms.
Collaborative Contextualization: Bridging the Gap between Collaborative Filtering and Pre-trained Language Model
Oct 13, 2023



Traditional recommender systems have heavily relied on identity representations (IDs) to model users and items, while the ascendancy of pre-trained language model (PLM) encoders has enriched the modeling of contextual item descriptions. However, PLMs, although effective in addressing few-shot, zero-shot, or unified modeling scenarios, often neglect the crucial collaborative filtering signal. This neglect gives rise to two pressing challenges: (1) Collaborative Contextualization, the seamless integration of collaborative signals with contextual representations. (2) the imperative to bridge the representation gap between ID-based representations and contextual representations while preserving their contextual semantics. In this paper, we propose CollabContext, a novel model that adeptly combines collaborative filtering signals with contextual representations and aligns these representations within the contextual space, preserving essential contextual semantics. Experimental results across three real-world datasets demonstrate substantial improvements. Leveraging collaborative contextualization, CollabContext can also be effectively applied to cold-start scenarios, achieving remarkable enhancements in recommendation performance. The code is available after the conference accepts the paper.
Graph-based Alignment and Uniformity for Recommendation
Aug 18, 2023



Collaborative filtering-based recommender systems (RecSys) rely on learning representations for users and items to predict preferences accurately. Representation learning on the hypersphere is a promising approach due to its desirable properties, such as alignment and uniformity. However, the sparsity issue arises when it encounters RecSys. To address this issue, we propose a novel approach, graph-based alignment and uniformity (GraphAU), that explicitly considers high-order connectivities in the user-item bipartite graph. GraphAU aligns the user/item embedding to the dense vector representations of high-order neighbors using a neighborhood aggregator, eliminating the need to compute the burdensome alignment to high-order neighborhoods individually. To address the discrepancy in alignment losses, GraphAU includes a layer-wise alignment pooling module to integrate alignment losses layer-wise. Experiments on four datasets show that GraphAU significantly alleviates the sparsity issue and achieves state-of-the-art performance. We open-source GraphAU at https://github.com/YangLiangwei/GraphAU.