 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning by Analogy: A Causal Framework for Composition Generalization
Dec 11, 2025Compositional generalization -- the ability to understand and generate novel combinations of learned concepts -- enables models to extend their capabilities beyond limited experiences. While effective, the data structures and principles that enable this crucial capability remain poorly understood. We propose that compositional generalization fundamentally requires decomposing high-level concepts into basic, low-level concepts that can be recombined across similar contexts, similar to how humans draw analogies between concepts. For example, someone who has never seen a peacock eating rice can envision this scene by relating it to their previous observations of a chicken eating rice. In this work, we formalize these intuitive processes using principles of causal modularity and minimal changes. We introduce a hierarchical data-generating process that naturally encodes different levels of concepts and their interaction mechanisms. Theoretically, we demonstrate that this approach enables compositional generalization supporting complex relations between composed concepts, advancing beyond prior work that assumes simpler interactions like additive effects. Critically, we also prove that this latent hierarchical structure is provably recoverable (identifiable) from observable data like text-image pairs, a necessary step for learning such a generative process. To validate our theory, we apply insights from our theoretical framework and achieve significant improvements on benchmark datasets.
Multi-modal Relational Item Representation Learning for Inferring Substitutable and Complementary Items
Jul 29, 2025



We introduce a novel self-supervised multi-modal relational item representation learning framework designed to infer substitutable and complementary items. Existing approaches primarily focus on modeling item-item associations deduced from user behaviors using graph neural networks (GNNs) or leveraging item content information. However, these methods often overlook critical challenges, such as noisy user behavior data and data sparsity due to the long-tailed distribution of these behaviors. In this paper, we propose MMSC, a self-supervised multi-modal relational item representation learning framework to address these challenges. Specifically, MMSC consists of three main components: (1) a multi-modal item representation learning module that leverages a multi-modal foundational model and learns from item metadata, (2) a self-supervised behavior-based representation learning module that denoises and learns from user behavior data, and (3) a hierarchical representation aggregation mechanism that integrates item representations at both the semantic and task levels. Additionally, we leverage LLMs to generate augmented training data, further enhancing the denoising process during training. We conduct extensive experiments on five real-world datasets, showing that MMSC outperforms existing baselines by 26.1% for substitutable recommendation and 39.2% for complementary recommendation. In addition, we empirically show that MMSC is effective in modeling cold-start items.
Enhancing Systematic Reviews with Large Language Models: Using GPT-4 and Kimi
Apr 28, 2025
This research delved into GPT-4 and Kimi, two Large Language Models (LLMs), for systematic reviews. We evaluated their performance by comparing LLM-generated codes with human-generated codes from a peer-reviewed systematic review on assessment. Our findings suggested that the performance of LLMs fluctuates by data volume and question complexity for systematic reviews.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
Temporal-Consistent Video Restoration with Pre-trained Diffusion Models
Mar 19, 2025
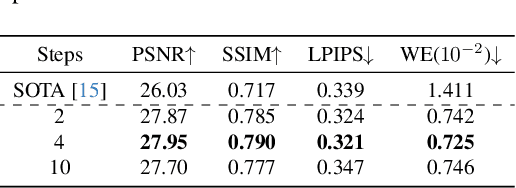
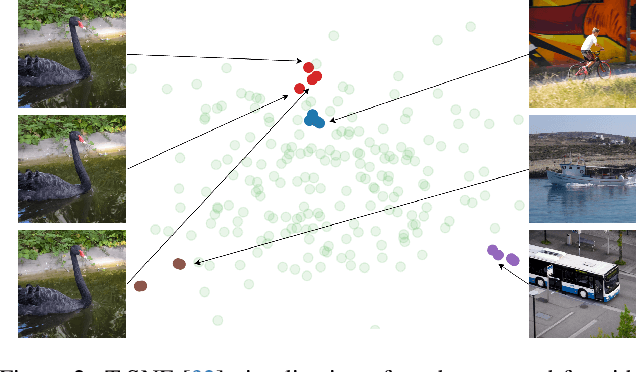
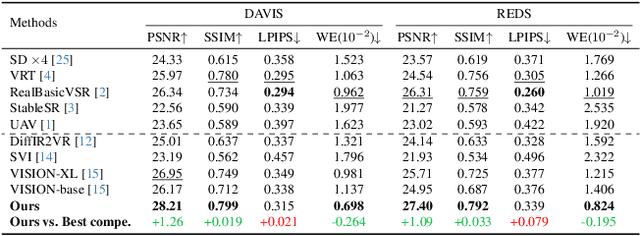
Video restoration (VR) aims to recover high-quality videos from degraded ones. Although recent zero-shot VR methods using pre-trained diffusion models (DMs) show good promise, they suffer from approximation errors during reverse diffusion and insufficient temporal consistency. Moreover, dealing with 3D video data, VR is inherently computationally intensive. In this paper, we advocate viewing the reverse process in DMs as a function and present a novel Maximum a Posterior (MAP) framework that directly parameterizes video frames in the seed space of DMs, eliminating approximation errors. We also introduce strategies to promote bilevel temporal consistency: semantic consistency by leveraging clustering structures in the seed space, and pixel-level consistency by progressive warping with optical flow refinements. Extensive experiments on multiple virtual reality tasks demonstrate superior visual quality and temporal consistency achieved by our method compared to the state-of-the-art.
PCL: Prompt-based Continual Learning for User Modeling in Recommender Systems
Feb 26, 2025



User modeling in large e-commerce platforms aims to optimize user experiences by incorporating various customer activities. Traditional models targeting a single task often focus on specific business metrics, neglecting the comprehensive user behavior, and thus limiting their effectiveness. To develop more generalized user representations, some existing work adopts Multi-task Learning (MTL)approaches. But they all face the challenges of optimization imbalance and inefficiency in adapting to new tasks. Continual Learning (CL), which allows models to learn new tasks incrementally and independently, has emerged as a solution to MTL's limitations. However, CL faces the challenge of catastrophic forgetting, where previously learned knowledge is lost when the model is learning the new task. Inspired by the success of prompt tuning in Pretrained Language Models (PLMs), we propose PCL, a Prompt-based Continual Learning framework for user modeling, which utilizes position-wise prompts as external memory for each task, preserving knowledge and mitigating catastrophic forgetting. Additionally, we design contextual prompts to capture and leverage inter-task relationships during prompt tuning. We conduct extensive experiments on real-world datasets to demonstrate PCL's effectiveness.
Q-Tuning: Queue-based Prompt Tuning for Lifelong Few-shot Language Learning
Apr 22, 2024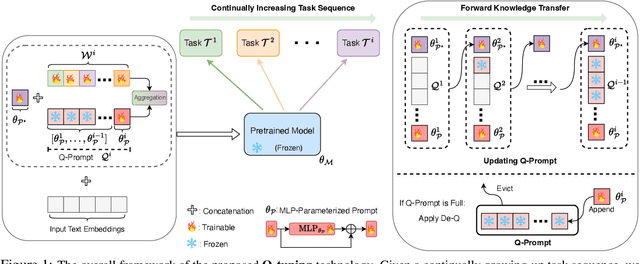
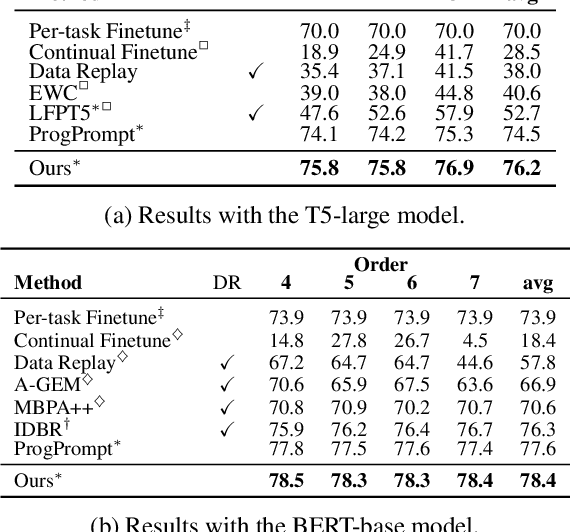
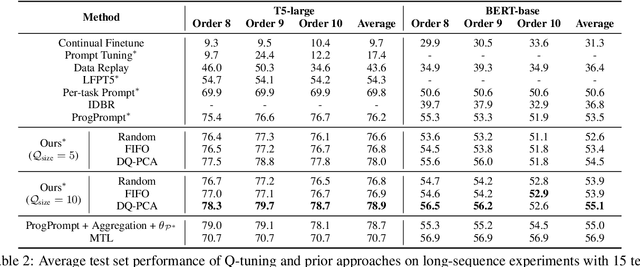
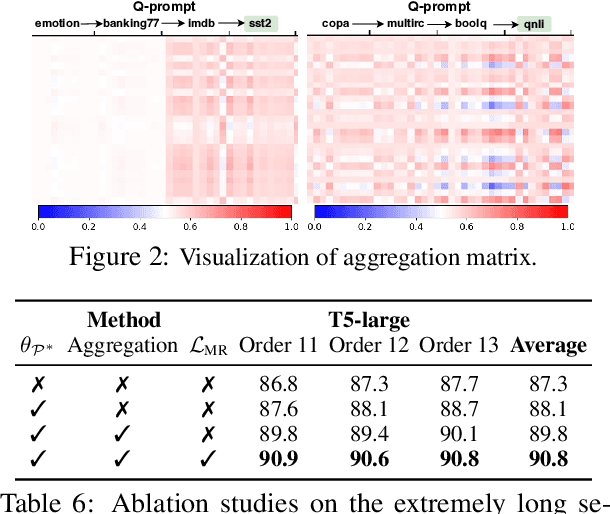
This paper introduces \textbf{Q-tuning}, a novel approach for continual prompt tuning that enables the lifelong learning of a pre-trained language model. When learning a new task, Q-tuning trains a task-specific prompt by adding it to a prompt queue consisting of the prompts from older tasks. To better transfer the knowledge of old tasks, we design an adaptive knowledge aggregation technique that reweighs previous prompts in the queue with a learnable low-rank matrix. Once the prompt queue reaches its maximum capacity, we leverage a PCA-based eviction rule to reduce the queue's size, allowing the newly trained prompt to be added while preserving the primary knowledge of old tasks. In order to mitigate the accumulation of information loss caused by the eviction, we additionally propose a globally shared prefix prompt and a memory retention regularization based on information theory. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods substantially on continual prompt tuning benchmarks. Moreover, our approach enables lifelong learning on linearly growing task sequences while requiring constant complexity for training and inference.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024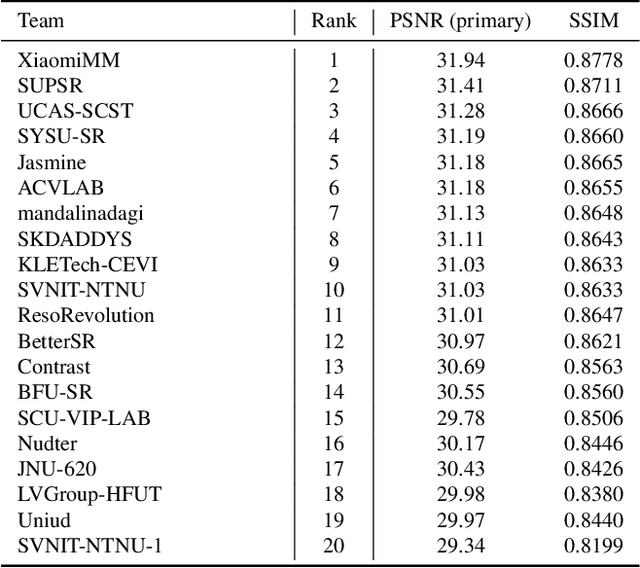
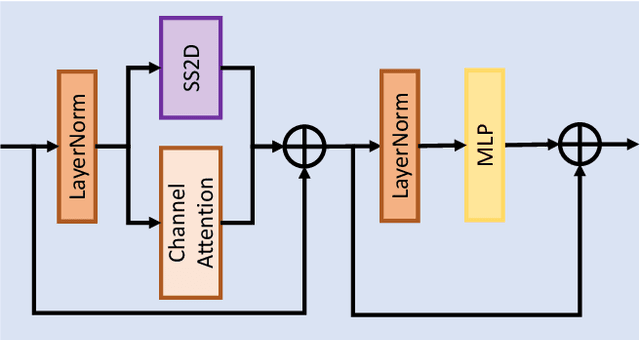
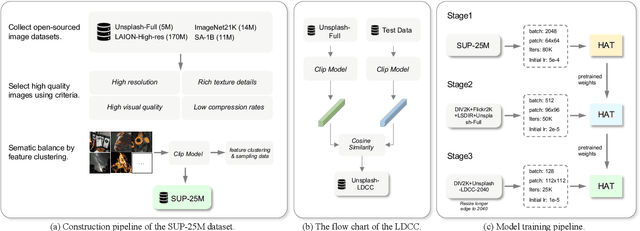
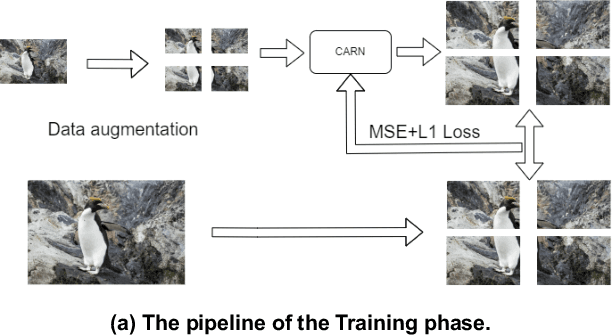
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Learning Noise-Resistant Image Representation by Aligning Clean and Noisy Domains
Jul 03, 2023Recent supervised and unsupervised image representation learning algorithms have achieved quantum leaps. However, these techniques do not account for representation resilience against noise in their design paradigms. Consequently, these effective methods suffer failure when confronted with noise outside the training distribution, such as complicated real-world noise that is usually opaque to model training. To address this issue, dual domains are optimized to separately model a canonical space for noisy representations, namely the Noise-Robust (NR) domain, and a twinned canonical clean space, namely the Noise-Free (NF) domain, by maximizing the interaction information between the representations. Given the dual canonical domains, we design a target-guided implicit neural mapping function to accurately translate the NR representations to the NF domain, yielding noise-resistant representations by eliminating noise regencies. The proposed method is a scalable module that can be readily integrated into existing learning systems to improve their robustness against noise. Comprehensive trials of various tasks using both synthetic and real-world noisy data demonstrate that the proposed Target-Guided Dual-Domain Translation (TDDT) method is able to achieve remarkable performance and robustness in the face of complex noisy images.