 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMPlug: Plug-In Foundation Flow-Matching Priors for Inverse Problems
Aug 01, 2025We present FMPlug, a novel plug-in framework that enhances foundation flow-matching (FM) priors for solving ill-posed inverse problems. Unlike traditional approaches that rely on domain-specific or untrained priors, FMPlug smartly leverages two simple but powerful insights: the similarity between observed and desired objects and the Gaussianity of generative flows. By introducing a time-adaptive warm-up strategy and sharp Gaussianity regularization, FMPlug unlocks the true potential of domain-agnostic foundation models. Our method beats state-of-the-art methods that use foundation FM priors by significant margins, on image super-resolution and Gaussian deblurring.
Temporal-Consistent Video Restoration with Pre-trained Diffusion Models
Mar 19, 2025
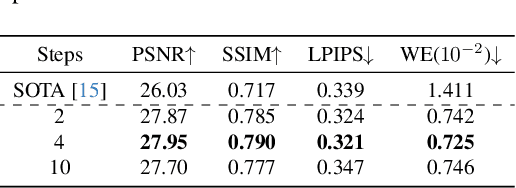
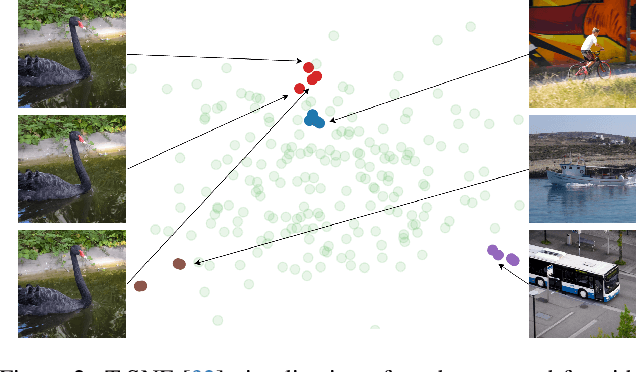
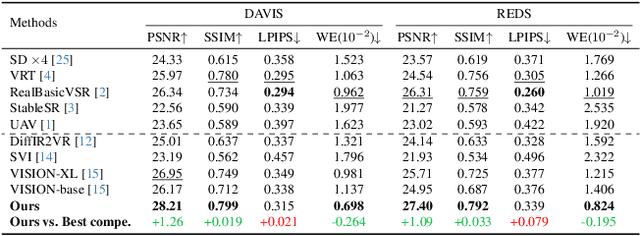
Video restoration (VR) aims to recover high-quality videos from degraded ones. Although recent zero-shot VR methods using pre-trained diffusion models (DMs) show good promise, they suffer from approximation errors during reverse diffusion and insufficient temporal consistency. Moreover, dealing with 3D video data, VR is inherently computationally intensive. In this paper, we advocate viewing the reverse process in DMs as a function and present a novel Maximum a Posterior (MAP) framework that directly parameterizes video frames in the seed space of DMs, eliminating approximation errors. We also introduce strategies to promote bilevel temporal consistency: semantic consistency by leveraging clustering structures in the seed space, and pixel-level consistency by progressive warping with optical flow refinements. Extensive experiments on multiple virtual reality tasks demonstrate superior visual quality and temporal consistency achieved by our method compared to the state-of-the-art.
A Baseline Method for Removing Invisible Image Watermarks using Deep Image Prior
Feb 19, 2025Image watermarks have been considered a promising technique to help detect AI-generated content, which can be used to protect copyright or prevent fake image abuse. In this work, we present a black-box method for removing invisible image watermarks, without the need of any dataset of watermarked images or any knowledge about the watermark system. Our approach is simple to implement: given a single watermarked image, we regress it by deep image prior (DIP). We show that from the intermediate steps of DIP one can reliably find an evasion image that can remove invisible watermarks while preserving high image quality. Due to its unique working mechanism and practical effectiveness, we advocate including DIP as a baseline invasion method for benchmarking the robustness of watermarking systems. Finally, by showing the limited ability of DIP and other existing black-box methods in evading training-based visible watermarks, we discuss the positive implications on the practical use of training-based visible watermarks to prevent misinformation abuse.
DMPlug: A Plug-in Method for Solving Inverse Problems with Diffusion Models
May 27, 2024



Pretrained diffusion models (DMs) have recently been popularly used in solving inverse problems (IPs). The existing methods mostly interleave iterative steps in the reverse diffusion process and iterative steps to bring the iterates closer to satisfying the measurement constraint. However, such interleaving methods struggle to produce final results that look like natural objects of interest (i.e., manifold feasibility) and fit the measurement (i.e., measurement feasibility), especially for nonlinear IPs. Moreover, their capabilities to deal with noisy IPs with unknown types and levels of measurement noise are unknown. In this paper, we advocate viewing the reverse process in DMs as a function and propose a novel plug-in method for solving IPs using pretrained DMs, dubbed DMPlug. DMPlug addresses the issues of manifold feasibility and measurement feasibility in a principled manner, and also shows great potential for being robust to unknown types and levels of noise. Through extensive experiments across various IP tasks, including two linear and three nonlinear IPs, we demonstrate that DMPlug consistently outperforms state-of-the-art methods, often by large margins especially for nonlinear IPs. The code is available at https://github.com/sun-umn/DMPlug.
Selective Classification Under Distribution Shifts
May 08, 2024



In selective classification (SC), a classifier abstains from making predictions that are likely to be wrong to avoid excessive errors. To deploy imperfect classifiers -- imperfect either due to intrinsic statistical noise of data or for robustness issue of the classifier or beyond -- in high-stakes scenarios, SC appears to be an attractive and necessary path to follow. Despite decades of research in SC, most previous SC methods still focus on the ideal statistical setting only, i.e., the data distribution at deployment is the same as that of training, although practical data can come from the wild. To bridge this gap, in this paper, we propose an SC framework that takes into account distribution shifts, termed generalized selective classification, that covers label-shifted (or out-of-distribution) and covariate-shifted samples, in addition to typical in-distribution samples, the first of its kind in the SC literature. We focus on non-training-based confidence-score functions for generalized SC on deep learning (DL) classifiers and propose two novel margin-based score functions. Through extensive analysis and experiments, we show that our proposed score functions are more effective and reliable than the existing ones for generalized SC on a variety of classification tasks and DL classifiers.
What is Wrong with End-to-End Learning for Phase Retrieval?
Mar 18, 2024For nonlinear inverse problems that are prevalent in imaging science, symmetries in the forward model are common. When data-driven deep learning approaches are used to solve such problems, these intrinsic symmetries can cause substantial learning difficulties. In this paper, we explain how such difficulties arise and, more importantly, how to overcome them by preprocessing the training set before any learning, i.e., symmetry breaking. We take far-field phase retrieval (FFPR), which is central to many areas of scientific imaging, as an example and show that symmetric breaking can substantially improve data-driven learning. We also formulate the mathematical principle of symmetry breaking.
A proximal augmented Lagrangian based algorithm for federated learning with global and local convex conic constraints
Oct 16, 2023
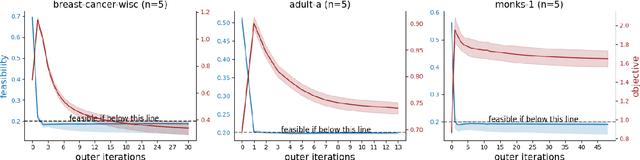
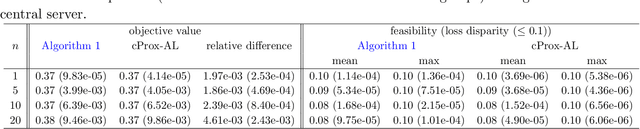

This paper considers federated learning (FL) with constraints, where the central server and all local clients collectively minimize a sum of convex local objective functions subject to global and local convex conic constraints. To train the model without moving local data from clients to the central server, we propose an FL framework in which each local client performs multiple updates using the local objective and local constraint, while the central server handles the global constraint and performs aggregation based on the updated local models. In particular, we develop a proximal augmented Lagrangian (AL) based algorithm for FL with global and local convex conic constraints. The subproblems arising in this algorithm are solved by an inexact alternating direction method of multipliers (ADMM) in a federated fashion. Under a local Lipschitz condition and mild assumptions, we establish the worst-case complexity bounds of the proposed algorithm for finding an approximate KKT solution. To the best of our knowledge, this work proposes the first algorithm for FL with global and local constraints. Our numerical experiments demonstrate the practical advantages of our algorithm in performing Neyman-Pearson classification and enhancing model fairness in the context of FL.
A Systematic Evaluation of Federated Learning on Biomedical Natural Language Processing
Jul 20, 2023Language models (LMs) like BERT and GPT have revolutionized natural language processing (NLP). However, privacy-sensitive domains, particularly the medical field, face challenges to train LMs due to limited data access and privacy constraints imposed by regulations like the Health Insurance Portability and Accountability Act (HIPPA) and the General Data Protection Regulation (GDPR). Federated learning (FL) offers a decentralized solution that enables collaborative learning while ensuring the preservation of data privacy. In this study, we systematically evaluate FL in medicine across $2$ biomedical NLP tasks using $6$ LMs encompassing $8$ corpora. Our results showed that: 1) FL models consistently outperform LMs trained on individual client's data and sometimes match the model trained with polled data; 2) With the fixed number of total data, LMs trained using FL with more clients exhibit inferior performance, but pre-trained transformer-based models exhibited greater resilience. 3) LMs trained using FL perform nearly on par with the model trained with pooled data when clients' data are IID distributed while exhibiting visible gaps with non-IID data. Our code is available at: https://github.com/PL97/FedNLP
Predicting the Future of the CMS Detector: Crystal Radiation Damage and Machine Learning at the LHC
Mar 23, 2023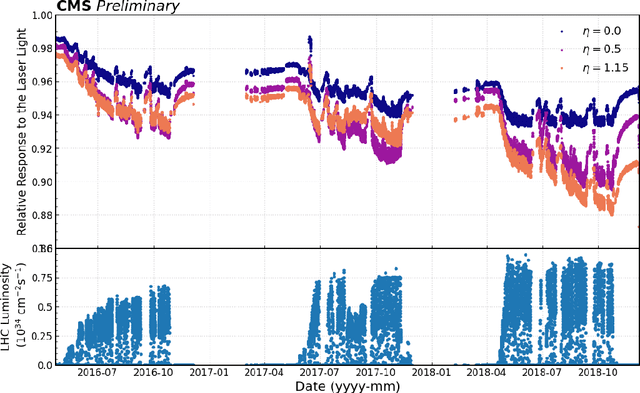
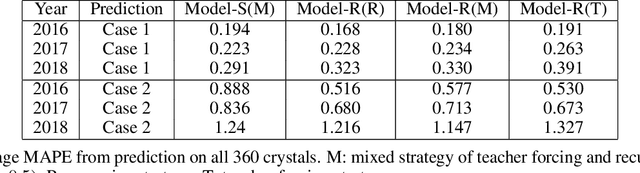
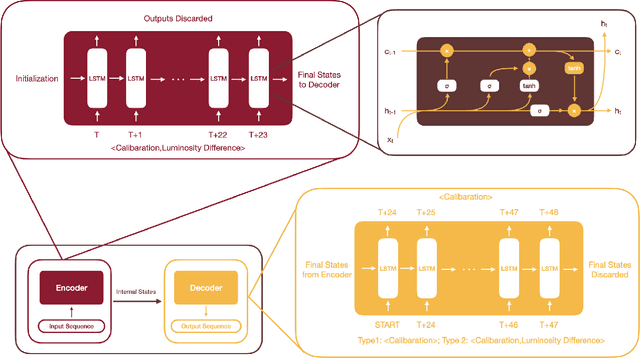
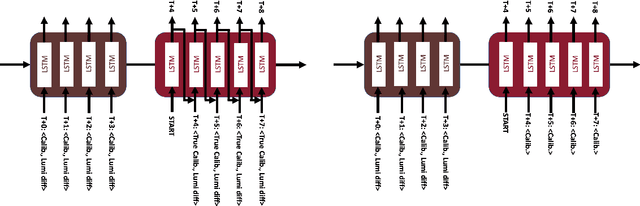
The 75,848 lead tungstate crystals in CMS experiment at the CERN Large Hadron Collider are used to measure the energy of electrons and photons produced in the proton-proton collisions. The optical transparency of the crystals degrades slowly with radiation dose due to the beam-beam collisions. The transparency of each crystal is monitored with a laser monitoring system that tracks changes in the optical properties of the crystals due to radiation from the collision products. Predicting the optical transparency of the crystals, both in the short-term and in the long-term, is a critical task for the CMS experiment. We describe here the public data release, following FAIR principles, of the crystal monitoring data collected by the CMS Collaboration between 2016 and 2018. Besides describing the dataset and its access, the problems that can be addressed with it are described, as well as an example solution based on a Long Short-Term Memory neural network developed to predict future behavior of the crystals.
Optimization and Optimizers for Adversarial Robustness
Mar 23, 2023



Empirical robustness evaluation (RE) of deep learning models against adversarial perturbations entails solving nontrivial constrained optimization problems. Existing numerical algorithms that are commonly used to solve them in practice predominantly rely on projected gradient, and mostly handle perturbations modeled by the $\ell_1$, $\ell_2$ and $\ell_\infty$ distances. In this paper, we introduce a novel algorithmic framework that blends a general-purpose constrained-optimization solver PyGRANSO with Constraint Folding (PWCF), which can add more reliability and generality to the state-of-the-art RE packages, e.g., AutoAttack. Regarding reliability, PWCF provides solutions with stationarity measures and feasibility tests to assess the solution quality. For generality, PWCF can handle perturbation models that are typically inaccessible to the existing projected gradient methods; the main requirement is the distance metric to be almost everywhere differentiable. Taking advantage of PWCF and other existing numerical algorithms, we further explore the distinct patterns in the solutions found for solving these optimization problems using various combinations of losses, perturbation models, and optimization algorithms. We then discuss the implications of these patterns on the current robustness evaluation and adversarial training.