 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Baseline Method for Removing Invisible Image Watermarks using Deep Image Prior
Feb 19, 2025Image watermarks have been considered a promising technique to help detect AI-generated content, which can be used to protect copyright or prevent fake image abuse. In this work, we present a black-box method for removing invisible image watermarks, without the need of any dataset of watermarked images or any knowledge about the watermark system. Our approach is simple to implement: given a single watermarked image, we regress it by deep image prior (DIP). We show that from the intermediate steps of DIP one can reliably find an evasion image that can remove invisible watermarks while preserving high image quality. Due to its unique working mechanism and practical effectiveness, we advocate including DIP as a baseline invasion method for benchmarking the robustness of watermarking systems. Finally, by showing the limited ability of DIP and other existing black-box methods in evading training-based visible watermarks, we discuss the positive implications on the practical use of training-based visible watermarks to prevent misinformation abuse.
DMPlug: A Plug-in Method for Solving Inverse Problems with Diffusion Models
May 27, 2024



Pretrained diffusion models (DMs) have recently been popularly used in solving inverse problems (IPs). The existing methods mostly interleave iterative steps in the reverse diffusion process and iterative steps to bring the iterates closer to satisfying the measurement constraint. However, such interleaving methods struggle to produce final results that look like natural objects of interest (i.e., manifold feasibility) and fit the measurement (i.e., measurement feasibility), especially for nonlinear IPs. Moreover, their capabilities to deal with noisy IPs with unknown types and levels of measurement noise are unknown. In this paper, we advocate viewing the reverse process in DMs as a function and propose a novel plug-in method for solving IPs using pretrained DMs, dubbed DMPlug. DMPlug addresses the issues of manifold feasibility and measurement feasibility in a principled manner, and also shows great potential for being robust to unknown types and levels of noise. Through extensive experiments across various IP tasks, including two linear and three nonlinear IPs, we demonstrate that DMPlug consistently outperforms state-of-the-art methods, often by large margins especially for nonlinear IPs. The code is available at https://github.com/sun-umn/DMPlug.
Joint Demosaicing and Denoising with Double Deep Image Priors
Sep 18, 2023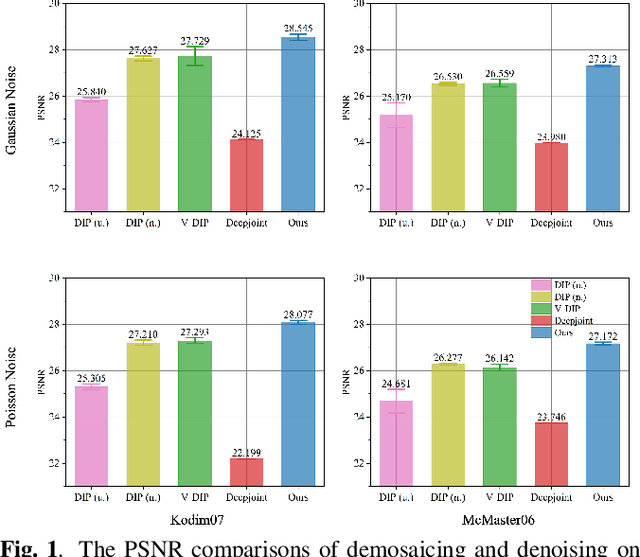
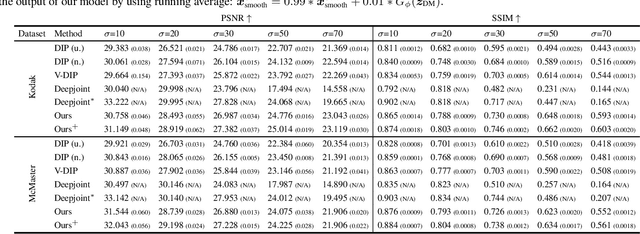
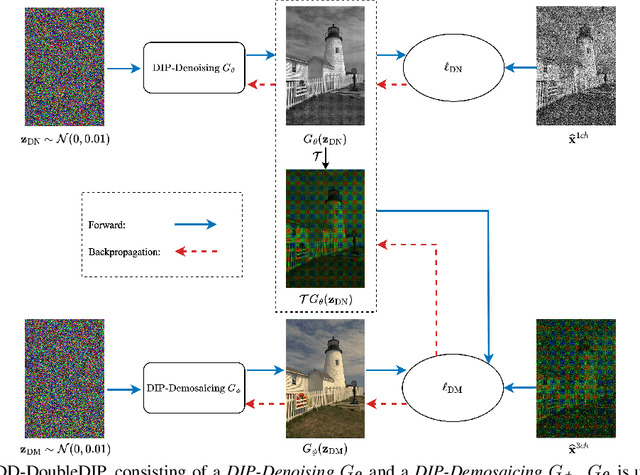
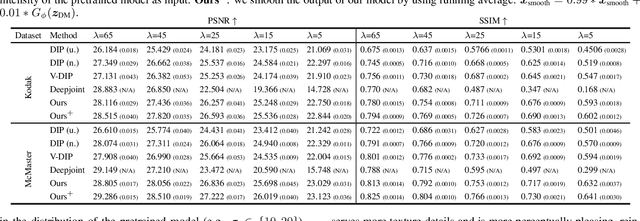
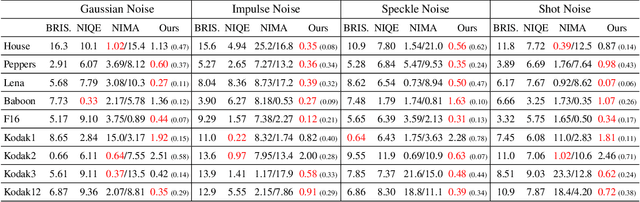
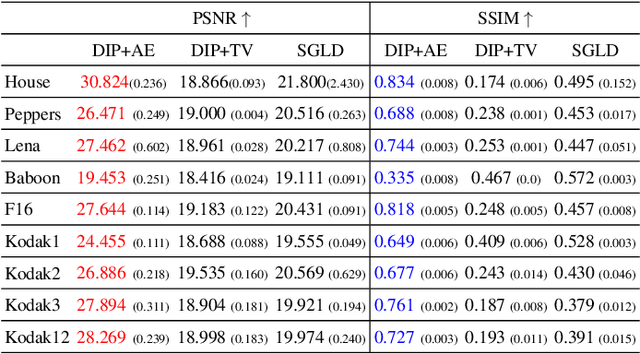
Demosaicing and denoising of RAW images are crucial steps in the processing pipeline of modern digital cameras. As only a third of the color information required to produce a digital image is captured by the camera sensor, the process of demosaicing is inherently ill-posed. The presence of noise further exacerbates this problem. Performing these two steps sequentially may distort the content of the captured RAW images and accumulate errors from one step to another. Recent deep neural-network-based approaches have shown the effectiveness of joint demosaicing and denoising to mitigate such challenges. However, these methods typically require a large number of training samples and do not generalize well to different types and intensities of noise. In this paper, we propose a novel joint demosaicing and denoising method, dubbed JDD-DoubleDIP, which operates directly on a single RAW image without requiring any training data. We validate the effectiveness of our method on two popular datasets -- Kodak and McMaster -- with various noises and noise intensities. The experimental results show that our method consistently outperforms other compared methods in terms of PSNR, SSIM, and qualitative visual perception.
Predicting the Future of the CMS Detector: Crystal Radiation Damage and Machine Learning at the LHC
Mar 23, 2023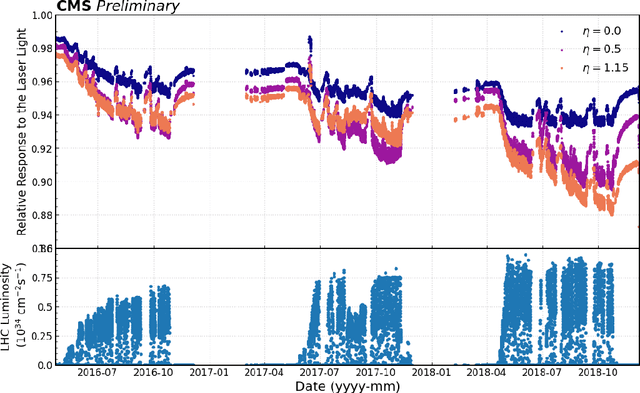
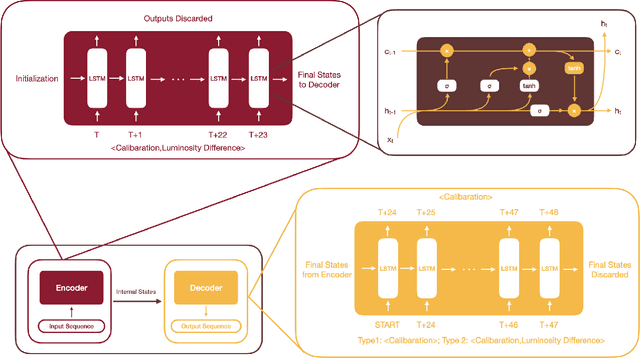
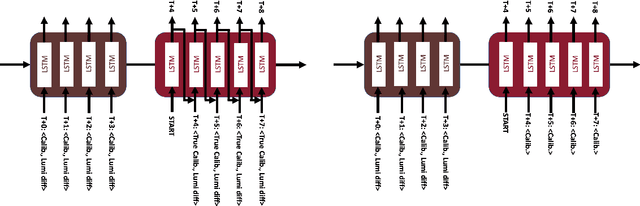
The 75,848 lead tungstate crystals in CMS experiment at the CERN Large Hadron Collider are used to measure the energy of electrons and photons produced in the proton-proton collisions. The optical transparency of the crystals degrades slowly with radiation dose due to the beam-beam collisions. The transparency of each crystal is monitored with a laser monitoring system that tracks changes in the optical properties of the crystals due to radiation from the collision products. Predicting the optical transparency of the crystals, both in the short-term and in the long-term, is a critical task for the CMS experiment. We describe here the public data release, following FAIR principles, of the crystal monitoring data collected by the CMS Collaboration between 2016 and 2018. Besides describing the dataset and its access, the problems that can be addressed with it are described, as well as an example solution based on a Long Short-Term Memory neural network developed to predict future behavior of the crystals.
Robust Autoencoders for Collective Corruption Removal
Mar 06, 2023


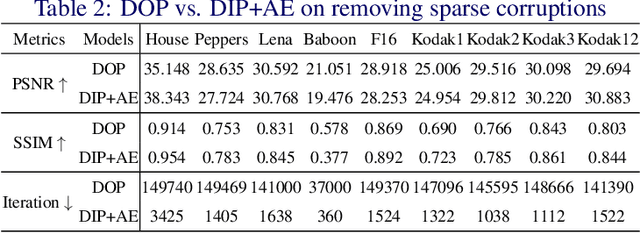
Robust PCA is a standard tool for learning a linear subspace in the presence of sparse corruption or rare outliers. What about robustly learning manifolds that are more realistic models for natural data, such as images? There have been several recent attempts to generalize robust PCA to manifold settings. In this paper, we propose $\ell_1$- and scaling-invariant $\ell_1/\ell_2$-robust autoencoders based on a surprisingly compact formulation built on the intuition that deep autoencoders perform manifold learning. We demonstrate on several standard image datasets that the proposed formulation significantly outperforms all previous methods in collectively removing sparse corruption, without clean images for training. Moreover, we also show that the learned manifold structures can be generalized to unseen data samples effectively.
Blind Image Deblurring with Unknown Kernel Size and Substantial Noise
Aug 18, 2022

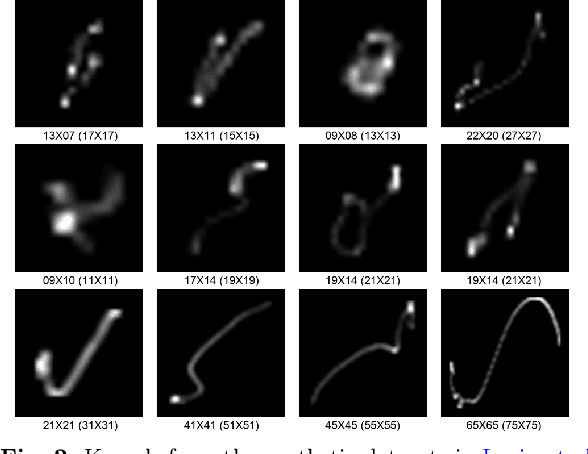

Blind image deblurring (BID) has been extensively studied in computer vision and adjacent fields. Modern methods for BID can be grouped into two categories: single-instance methods that deal with individual instances using statistical inference and numerical optimization, and data-driven methods that train deep-learning models to deblur future instances directly. Data-driven methods can be free from the difficulty in deriving accurate blur models, but are fundamentally limited by the diversity and quality of the training data -- collecting sufficiently expressive and realistic training data is a standing challenge. In this paper, we focus on single-instance methods that remain competitive and indispensable. However, most such methods do not prescribe how to deal with unknown kernel size and substantial noise, precluding practical deployment. Indeed, we show that several state-of-the-art (SOTA) single-instance methods are unstable when the kernel size is overspecified, and/or the noise level is high. On the positive side, we propose a practical BID method that is stable against both, the first of its kind. Our method builds on the recent ideas of solving inverse problems by integrating the physical models and structured deep neural networks, without extra training data. We introduce several crucial modifications to achieve the desired stability. Extensive empirical tests on standard synthetic datasets, as well as real-world NTIRE2020 and RealBlur datasets, show the superior effectiveness and practicality of our BID method compared to SOTA single-instance as well as data-driven methods. The code of our method is available at: \url{https://github.com/sun-umn/Blind-Image-Deblurring}.
Early Stopping for Deep Image Prior
Dec 11, 2021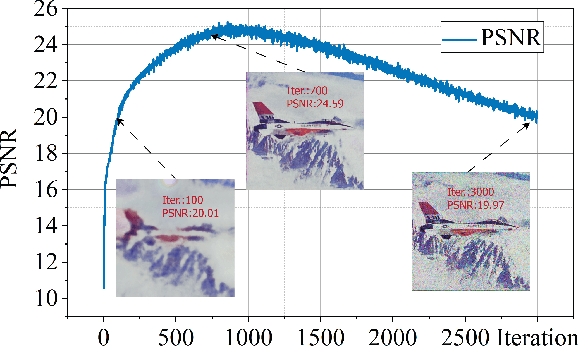
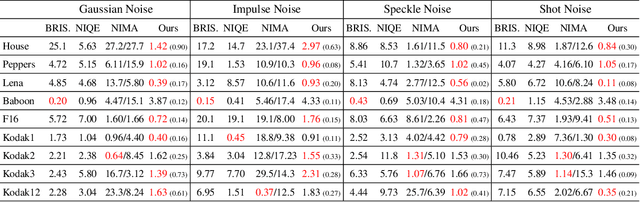
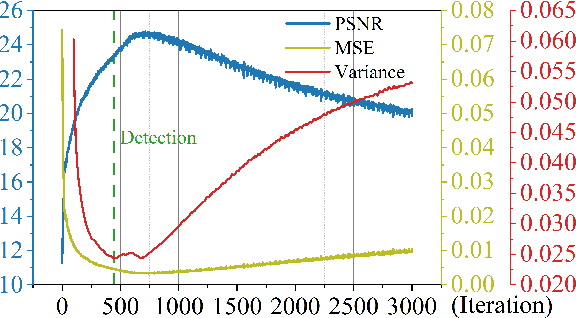
Deep image prior (DIP) and its variants have showed remarkable potential for solving inverse problems in computer vision, without any extra training data. Practical DIP models are often substantially overparameterized. During the fitting process, these models learn mostly the desired visual content first, and then pick up the potential modeling and observational noise, i.e., overfitting. Thus, the practicality of DIP often depends critically on good early stopping (ES) that captures the transition period. In this regard, the majority of DIP works for vision tasks only demonstrates the potential of the models -- reporting the peak performance against the ground truth, but provides no clue about how to operationally obtain near-peak performance without access to the groundtruth. In this paper, we set to break this practicality barrier of DIP, and propose an efficient ES strategy, which consistently detects near-peak performance across several vision tasks and DIP variants. Based on a simple measure of dispersion of consecutive DIP reconstructions, our ES method not only outpaces the existing ones -- which only work in very narrow domains, but also remains effective when combined with a number of methods that try to mitigate the overfitting. The code is available at https://github.com/sun-umn/Early_Stopping_for_DIP.
Self-Validation: Early Stopping for Single-Instance Deep Generative Priors
Oct 23, 2021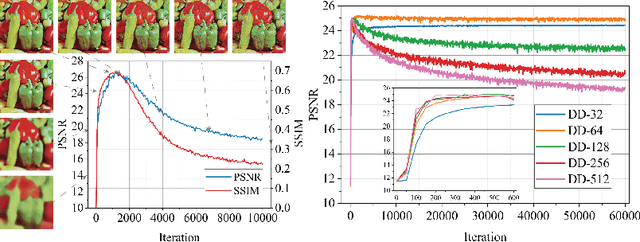
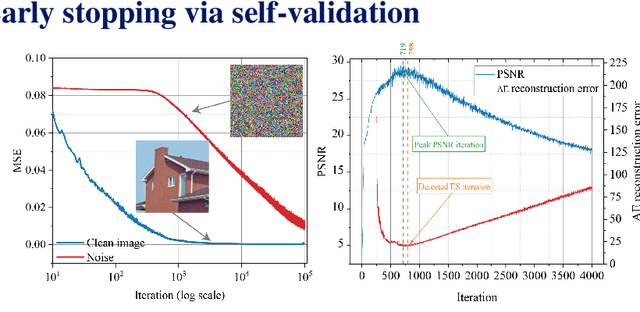
Recent works have shown the surprising effectiveness of deep generative models in solving numerous image reconstruction (IR) tasks, even without training data. We call these models, such as deep image prior and deep decoder, collectively as single-instance deep generative priors (SIDGPs). The successes, however, often hinge on appropriate early stopping (ES), which by far has largely been handled in an ad-hoc manner. In this paper, we propose the first principled method for ES when applying SIDGPs to IR, taking advantage of the typical bell trend of the reconstruction quality. In particular, our method is based on collaborative training and self-validation: the primal reconstruction process is monitored by a deep autoencoder, which is trained online with the historic reconstructed images and used to validate the reconstruction quality constantly. Experimentally, on several IR problems and different SIDGPs, our self-validation method is able to reliably detect near-peak performance and signal good ES points. Our code is available at https://sun-umn.github.io/Self-Validation/.
Rethink Transfer Learning in Medical Image Classification
Jun 10, 2021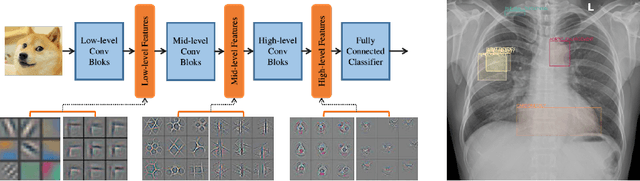
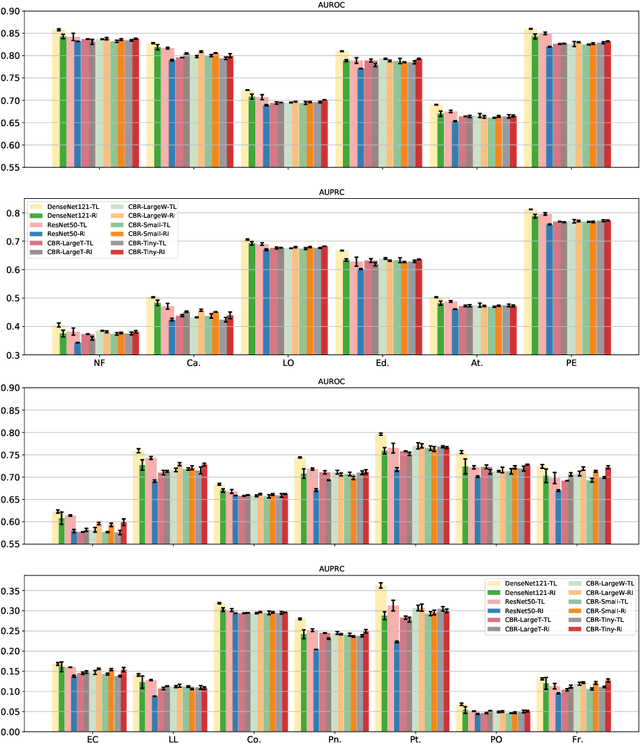
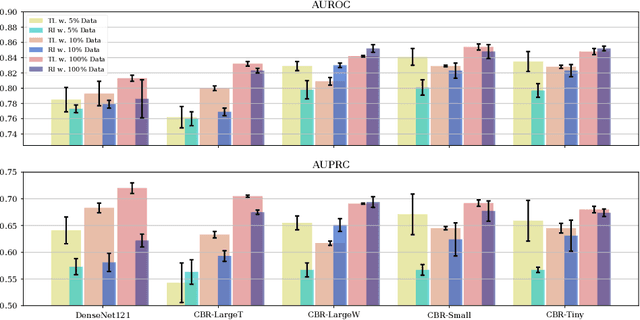
Transfer learning (TL) with deep convolutional neural networks (DCNNs) has proved successful in medical image classification (MIC). However, the current practice is puzzling, as MIC typically relies only on low- and/or mid-level features that are learned in the bottom layers of DCNNs. Following this intuition, we question the current strategies of TL in MIC. In this paper, we perform careful experimental comparisons between shallow and deep networks for classification on two chest x-ray datasets, using different TL strategies. We find that deep models are not always favorable, and finetuning truncated deep models almost always yields the best performance, especially in data-poor regimes. Project webpage: https://sun-umn.github.io/Transfer-Learning-in-Medical-Imaging/ Keywords: Transfer learning, Medical image classification, Feature hierarchy, Medical imaging, Evaluation metrics, Imbalanced data
A Prospective Observational Study to Investigate Performance of a Chest X-ray Artificial Intelligence Diagnostic Support Tool Across 12 U.S. Hospitals
Jun 07, 2021Importance: An artificial intelligence (AI)-based model to predict COVID-19 likelihood from chest x-ray (CXR) findings can serve as an important adjunct to accelerate immediate clinical decision making and improve clinical decision making. Despite significant efforts, many limitations and biases exist in previously developed AI diagnostic models for COVID-19. Utilizing a large set of local and international CXR images, we developed an AI model with high performance on temporal and external validation. Conclusions and Relevance: AI-based diagnostic tools may serve as an adjunct, but not replacement, for clinical decision support of COVID-19 diagnosis, which largely hinges on exposure history, signs, and symptoms. While AI-based tools have not yet reached full diagnostic potential in COVID-19, they may still offer valuable information to clinicians taken into consideration along with clinical signs and symptoms.