 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Classification Under Distribution Shifts
May 08, 2024In selective classification (SC), a classifier abstains from making predictions that are likely to be wrong to avoid excessive errors. To deploy imperfect classifiers -- imperfect either due to intrinsic statistical noise of data or for robustness issue of the classifier or beyond -- in high-stakes scenarios, SC appears to be an attractive and necessary path to follow. Despite decades of research in SC, most previous SC methods still focus on the ideal statistical setting only, i.e., the data distribution at deployment is the same as that of training, although practical data can come from the wild. To bridge this gap, in this paper, we propose an SC framework that takes into account distribution shifts, termed generalized selective classification, that covers label-shifted (or out-of-distribution) and covariate-shifted samples, in addition to typical in-distribution samples, the first of its kind in the SC literature. We focus on non-training-based confidence-score functions for generalized SC on deep learning (DL) classifiers and propose two novel margin-based score functions. Through extensive analysis and experiments, we show that our proposed score functions are more effective and reliable than the existing ones for generalized SC on a variety of classification tasks and DL classifiers.
A proximal augmented Lagrangian based algorithm for federated learning with global and local convex conic constraints
Oct 16, 2023This paper considers federated learning (FL) with constraints, where the central server and all local clients collectively minimize a sum of convex local objective functions subject to global and local convex conic constraints. To train the model without moving local data from clients to the central server, we propose an FL framework in which each local client performs multiple updates using the local objective and local constraint, while the central server handles the global constraint and performs aggregation based on the updated local models. In particular, we develop a proximal augmented Lagrangian (AL) based algorithm for FL with global and local convex conic constraints. The subproblems arising in this algorithm are solved by an inexact alternating direction method of multipliers (ADMM) in a federated fashion. Under a local Lipschitz condition and mild assumptions, we establish the worst-case complexity bounds of the proposed algorithm for finding an approximate KKT solution. To the best of our knowledge, this work proposes the first algorithm for FL with global and local constraints. Our numerical experiments demonstrate the practical advantages of our algorithm in performing Neyman-Pearson classification and enhancing model fairness in the context of FL.
A Systematic Evaluation of Federated Learning on Biomedical Natural Language Processing
Jul 20, 2023Language models (LMs) like BERT and GPT have revolutionized natural language processing (NLP). However, privacy-sensitive domains, particularly the medical field, face challenges to train LMs due to limited data access and privacy constraints imposed by regulations like the Health Insurance Portability and Accountability Act (HIPPA) and the General Data Protection Regulation (GDPR). Federated learning (FL) offers a decentralized solution that enables collaborative learning while ensuring the preservation of data privacy. In this study, we systematically evaluate FL in medicine across $2$ biomedical NLP tasks using $6$ LMs encompassing $8$ corpora. Our results showed that: 1) FL models consistently outperform LMs trained on individual client's data and sometimes match the model trained with polled data; 2) With the fixed number of total data, LMs trained using FL with more clients exhibit inferior performance, but pre-trained transformer-based models exhibited greater resilience. 3) LMs trained using FL perform nearly on par with the model trained with pooled data when clients' data are IID distributed while exhibiting visible gaps with non-IID data. Our code is available at: https://github.com/PL97/FedNLP
Optimization and Optimizers for Adversarial Robustness
Mar 23, 2023



Empirical robustness evaluation (RE) of deep learning models against adversarial perturbations entails solving nontrivial constrained optimization problems. Existing numerical algorithms that are commonly used to solve them in practice predominantly rely on projected gradient, and mostly handle perturbations modeled by the $\ell_1$, $\ell_2$ and $\ell_\infty$ distances. In this paper, we introduce a novel algorithmic framework that blends a general-purpose constrained-optimization solver PyGRANSO with Constraint Folding (PWCF), which can add more reliability and generality to the state-of-the-art RE packages, e.g., AutoAttack. Regarding reliability, PWCF provides solutions with stationarity measures and feasibility tests to assess the solution quality. For generality, PWCF can handle perturbation models that are typically inaccessible to the existing projected gradient methods; the main requirement is the distance metric to be almost everywhere differentiable. Taking advantage of PWCF and other existing numerical algorithms, we further explore the distinct patterns in the solutions found for solving these optimization problems using various combinations of losses, perturbation models, and optimization algorithms. We then discuss the implications of these patterns on the current robustness evaluation and adversarial training.
Welfare and Fairness Dynamics in Federated Learning: A Client Selection Perspective
Feb 17, 2023



Federated learning (FL) is a privacy-preserving learning technique that enables distributed computing devices to train shared learning models across data silos collaboratively. Existing FL works mostly focus on designing advanced FL algorithms to improve the model performance. However, the economic considerations of the clients, such as fairness and incentive, are yet to be fully explored. Without such considerations, self-motivated clients may lose interest and leave the federation. To address this problem, we designed a novel incentive mechanism that involves a client selection process to remove low-quality clients and a money transfer process to ensure a fair reward distribution. Our experimental results strongly demonstrate that the proposed incentive mechanism can effectively improve the duration and fairness of the federation.
Self-Validation: Early Stopping for Single-Instance Deep Generative Priors
Oct 23, 2021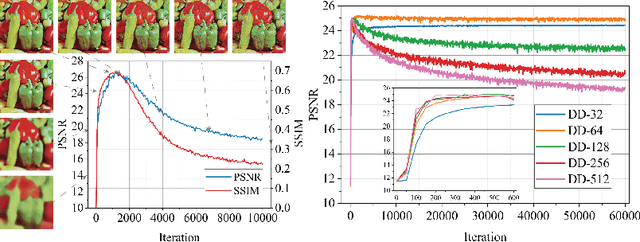
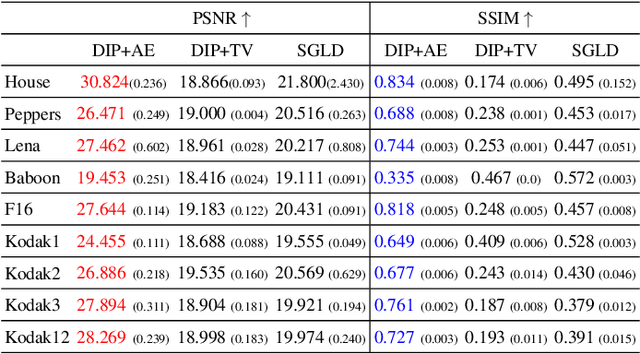
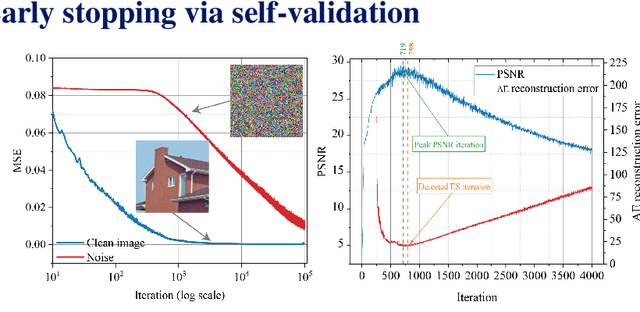
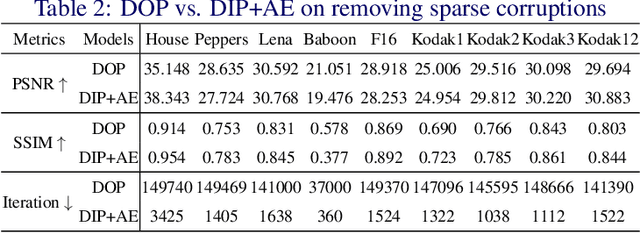
Recent works have shown the surprising effectiveness of deep generative models in solving numerous image reconstruction (IR) tasks, even without training data. We call these models, such as deep image prior and deep decoder, collectively as single-instance deep generative priors (SIDGPs). The successes, however, often hinge on appropriate early stopping (ES), which by far has largely been handled in an ad-hoc manner. In this paper, we propose the first principled method for ES when applying SIDGPs to IR, taking advantage of the typical bell trend of the reconstruction quality. In particular, our method is based on collaborative training and self-validation: the primal reconstruction process is monitored by a deep autoencoder, which is trained online with the historic reconstructed images and used to validate the reconstruction quality constantly. Experimentally, on several IR problems and different SIDGPs, our self-validation method is able to reliably detect near-peak performance and signal good ES points. Our code is available at https://sun-umn.github.io/Self-Validation/.
Rethink Transfer Learning in Medical Image Classification
Jun 10, 2021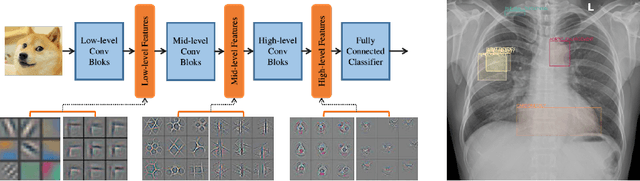
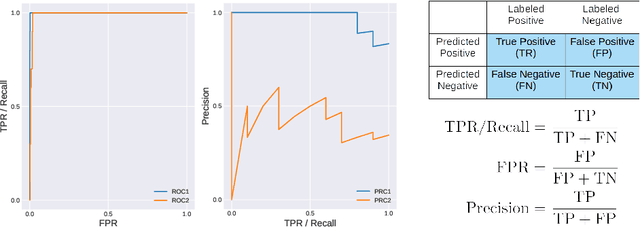
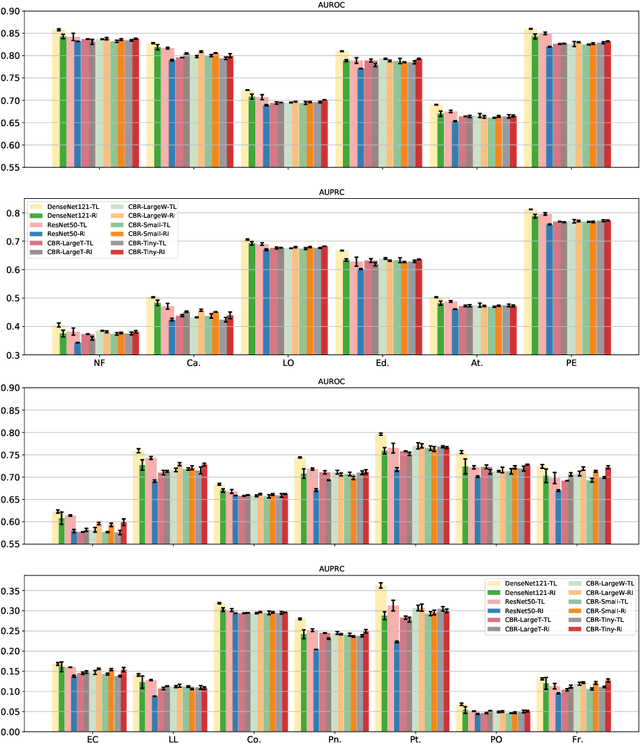
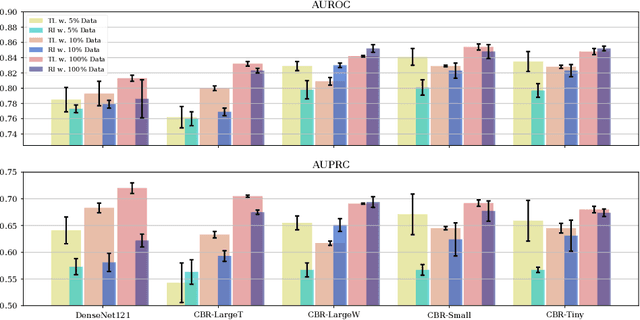
Transfer learning (TL) with deep convolutional neural networks (DCNNs) has proved successful in medical image classification (MIC). However, the current practice is puzzling, as MIC typically relies only on low- and/or mid-level features that are learned in the bottom layers of DCNNs. Following this intuition, we question the current strategies of TL in MIC. In this paper, we perform careful experimental comparisons between shallow and deep networks for classification on two chest x-ray datasets, using different TL strategies. We find that deep models are not always favorable, and finetuning truncated deep models almost always yields the best performance, especially in data-poor regimes. Project webpage: https://sun-umn.github.io/Transfer-Learning-in-Medical-Imaging/ Keywords: Transfer learning, Medical image classification, Feature hierarchy, Medical imaging, Evaluation metrics, Imbalanced data
A Prospective Observational Study to Investigate Performance of a Chest X-ray Artificial Intelligence Diagnostic Support Tool Across 12 U.S. Hospitals
Jun 07, 2021Importance: An artificial intelligence (AI)-based model to predict COVID-19 likelihood from chest x-ray (CXR) findings can serve as an important adjunct to accelerate immediate clinical decision making and improve clinical decision making. Despite significant efforts, many limitations and biases exist in previously developed AI diagnostic models for COVID-19. Utilizing a large set of local and international CXR images, we developed an AI model with high performance on temporal and external validation. Conclusions and Relevance: AI-based diagnostic tools may serve as an adjunct, but not replacement, for clinical decision support of COVID-19 diagnosis, which largely hinges on exposure history, signs, and symptoms. While AI-based tools have not yet reached full diagnostic potential in COVID-19, they may still offer valuable information to clinicians taken into consideration along with clinical signs and symptoms.