 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Baseline Method for Removing Invisible Image Watermarks using Deep Image Prior
Feb 19, 2025Image watermarks have been considered a promising technique to help detect AI-generated content, which can be used to protect copyright or prevent fake image abuse. In this work, we present a black-box method for removing invisible image watermarks, without the need of any dataset of watermarked images or any knowledge about the watermark system. Our approach is simple to implement: given a single watermarked image, we regress it by deep image prior (DIP). We show that from the intermediate steps of DIP one can reliably find an evasion image that can remove invisible watermarks while preserving high image quality. Due to its unique working mechanism and practical effectiveness, we advocate including DIP as a baseline invasion method for benchmarking the robustness of watermarking systems. Finally, by showing the limited ability of DIP and other existing black-box methods in evading training-based visible watermarks, we discuss the positive implications on the practical use of training-based visible watermarks to prevent misinformation abuse.
Selective Classification Under Distribution Shifts
May 08, 2024



In selective classification (SC), a classifier abstains from making predictions that are likely to be wrong to avoid excessive errors. To deploy imperfect classifiers -- imperfect either due to intrinsic statistical noise of data or for robustness issue of the classifier or beyond -- in high-stakes scenarios, SC appears to be an attractive and necessary path to follow. Despite decades of research in SC, most previous SC methods still focus on the ideal statistical setting only, i.e., the data distribution at deployment is the same as that of training, although practical data can come from the wild. To bridge this gap, in this paper, we propose an SC framework that takes into account distribution shifts, termed generalized selective classification, that covers label-shifted (or out-of-distribution) and covariate-shifted samples, in addition to typical in-distribution samples, the first of its kind in the SC literature. We focus on non-training-based confidence-score functions for generalized SC on deep learning (DL) classifiers and propose two novel margin-based score functions. Through extensive analysis and experiments, we show that our proposed score functions are more effective and reliable than the existing ones for generalized SC on a variety of classification tasks and DL classifiers.
Optimization and Optimizers for Adversarial Robustness
Mar 23, 2023



Empirical robustness evaluation (RE) of deep learning models against adversarial perturbations entails solving nontrivial constrained optimization problems. Existing numerical algorithms that are commonly used to solve them in practice predominantly rely on projected gradient, and mostly handle perturbations modeled by the $\ell_1$, $\ell_2$ and $\ell_\infty$ distances. In this paper, we introduce a novel algorithmic framework that blends a general-purpose constrained-optimization solver PyGRANSO with Constraint Folding (PWCF), which can add more reliability and generality to the state-of-the-art RE packages, e.g., AutoAttack. Regarding reliability, PWCF provides solutions with stationarity measures and feasibility tests to assess the solution quality. For generality, PWCF can handle perturbation models that are typically inaccessible to the existing projected gradient methods; the main requirement is the distance metric to be almost everywhere differentiable. Taking advantage of PWCF and other existing numerical algorithms, we further explore the distinct patterns in the solutions found for solving these optimization problems using various combinations of losses, perturbation models, and optimization algorithms. We then discuss the implications of these patterns on the current robustness evaluation and adversarial training.
Optimization for Robustness Evaluation beyond $\ell_p$ Metrics
Oct 02, 2022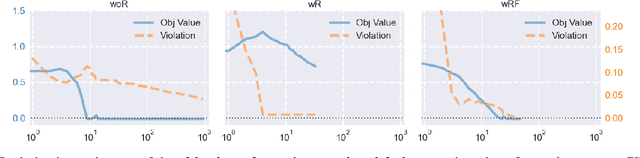
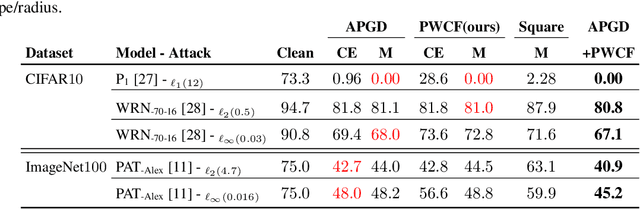
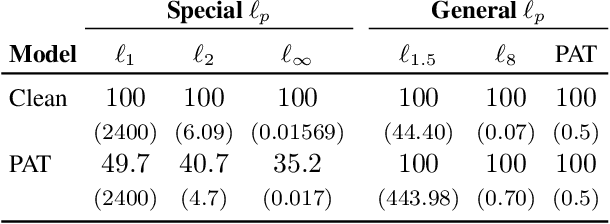
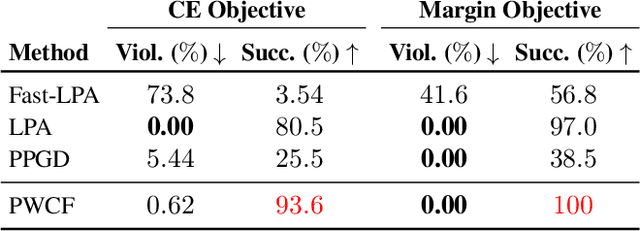
Empirical evaluation of deep learning models against adversarial attacks entails solving nontrivial constrained optimization problems. Popular algorithms for solving these constrained problems rely on projected gradient descent (PGD) and require careful tuning of multiple hyperparameters. Moreover, PGD can only handle $\ell_1$, $\ell_2$, and $\ell_\infty$ attack models due to the use of analytical projectors. In this paper, we introduce a novel algorithmic framework that blends a general-purpose constrained-optimization solver PyGRANSO, With Constraint-Folding (PWCF), to add reliability and generality to robustness evaluation. PWCF 1) finds good-quality solutions without the need of delicate hyperparameter tuning, and 2) can handle general attack models, e.g., general $\ell_p$ ($p \geq 0$) and perceptual attacks, which are inaccessible to PGD-based algorithms.
Early Stopping for Deep Image Prior
Dec 11, 2021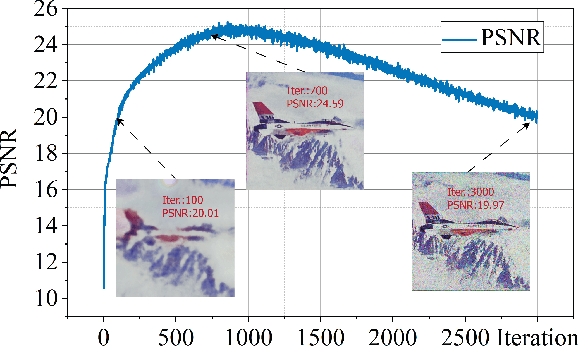
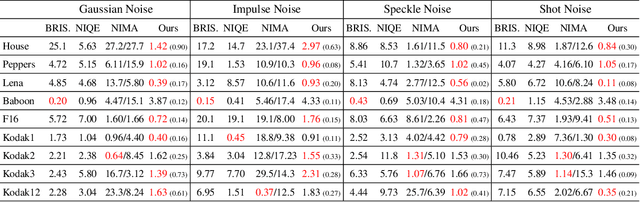
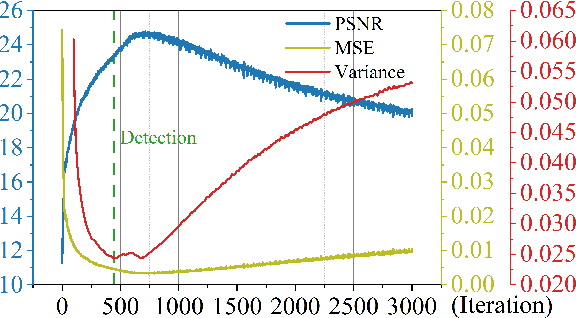
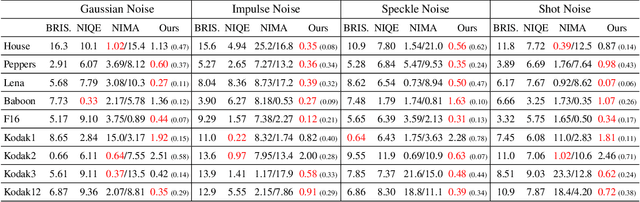
Deep image prior (DIP) and its variants have showed remarkable potential for solving inverse problems in computer vision, without any extra training data. Practical DIP models are often substantially overparameterized. During the fitting process, these models learn mostly the desired visual content first, and then pick up the potential modeling and observational noise, i.e., overfitting. Thus, the practicality of DIP often depends critically on good early stopping (ES) that captures the transition period. In this regard, the majority of DIP works for vision tasks only demonstrates the potential of the models -- reporting the peak performance against the ground truth, but provides no clue about how to operationally obtain near-peak performance without access to the groundtruth. In this paper, we set to break this practicality barrier of DIP, and propose an efficient ES strategy, which consistently detects near-peak performance across several vision tasks and DIP variants. Based on a simple measure of dispersion of consecutive DIP reconstructions, our ES method not only outpaces the existing ones -- which only work in very narrow domains, but also remains effective when combined with a number of methods that try to mitigate the overfitting. The code is available at https://github.com/sun-umn/Early_Stopping_for_DIP.
Self-Validation: Early Stopping for Single-Instance Deep Generative Priors
Oct 23, 2021
Recent works have shown the surprising effectiveness of deep generative models in solving numerous image reconstruction (IR) tasks, even without training data. We call these models, such as deep image prior and deep decoder, collectively as single-instance deep generative priors (SIDGPs). The successes, however, often hinge on appropriate early stopping (ES), which by far has largely been handled in an ad-hoc manner. In this paper, we propose the first principled method for ES when applying SIDGPs to IR, taking advantage of the typical bell trend of the reconstruction quality. In particular, our method is based on collaborative training and self-validation: the primal reconstruction process is monitored by a deep autoencoder, which is trained online with the historic reconstructed images and used to validate the reconstruction quality constantly. Experimentally, on several IR problems and different SIDGPs, our self-validation method is able to reliably detect near-peak performance and signal good ES points. Our code is available at https://sun-umn.github.io/Self-Validation/.
Rethink Transfer Learning in Medical Image Classification
Jun 10, 2021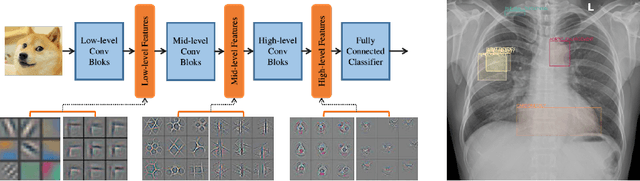
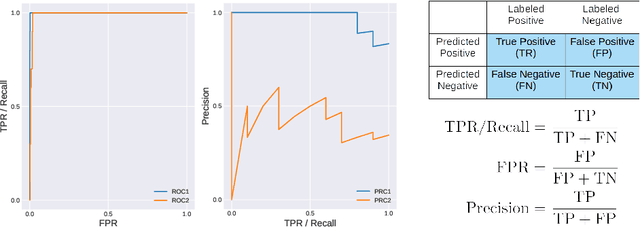
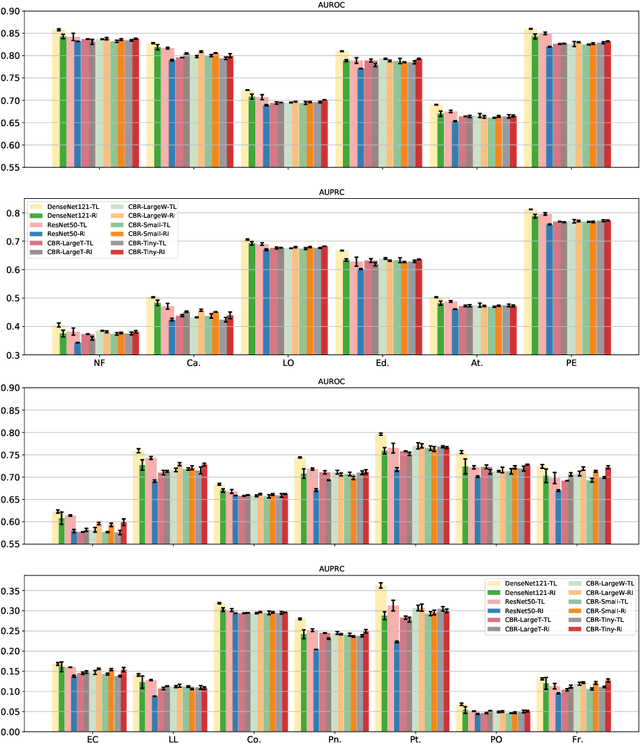
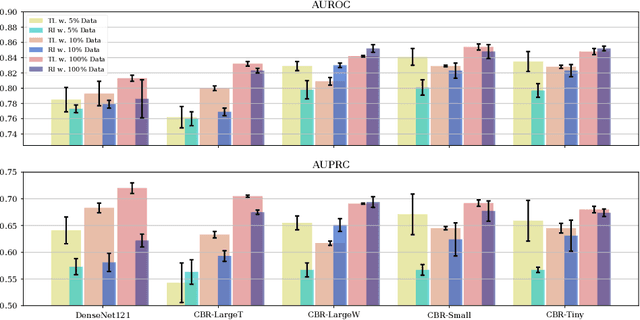
Transfer learning (TL) with deep convolutional neural networks (DCNNs) has proved successful in medical image classification (MIC). However, the current practice is puzzling, as MIC typically relies only on low- and/or mid-level features that are learned in the bottom layers of DCNNs. Following this intuition, we question the current strategies of TL in MIC. In this paper, we perform careful experimental comparisons between shallow and deep networks for classification on two chest x-ray datasets, using different TL strategies. We find that deep models are not always favorable, and finetuning truncated deep models almost always yields the best performance, especially in data-poor regimes. Project webpage: https://sun-umn.github.io/Transfer-Learning-in-Medical-Imaging/ Keywords: Transfer learning, Medical image classification, Feature hierarchy, Medical imaging, Evaluation metrics, Imbalanced data
Attribute-Based Robotic Grasping with One-Grasp Adaptation
Apr 06, 2021
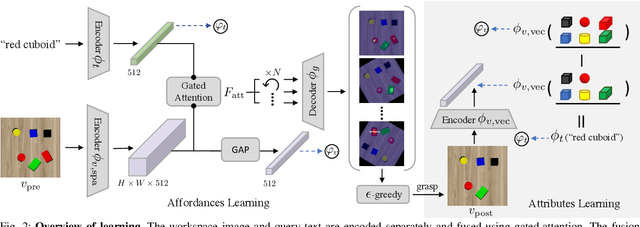


Robotic grasping is one of the most fundamental robotic manipulation tasks and has been actively studied. However, how to quickly teach a robot to grasp a novel target object in clutter remains challenging. This paper attempts to tackle the challenge by leveraging object attributes that facilitate recognition, grasping, and quick adaptation. In this work, we introduce an end-to-end learning method of attribute-based robotic grasping with one-grasp adaptation capability. Our approach fuses the embeddings of a workspace image and a query text using a gated-attention mechanism and learns to predict instance grasping affordances. Besides, we utilize object persistence before and after grasping to learn a joint metric space of visual and textual attributes. Our model is self-supervised in a simulation that only uses basic objects of various colors and shapes but generalizes to novel objects and real-world scenes. We further demonstrate that our model is capable of adapting to novel objects with only one grasp data and improving instance grasping performance significantly. Experimental results in both simulation and the real world demonstrate that our approach achieves over 80\% instance grasping success rate on unknown objects, which outperforms several baselines by large margins.
Knowledge Induced Deep Q-Network for a Slide-to-Wall Object Grasping
Oct 09, 2019
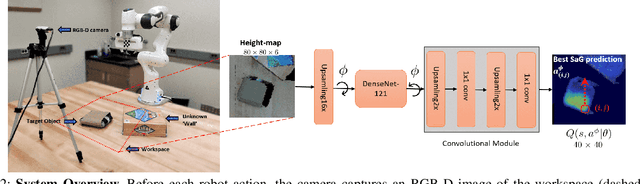

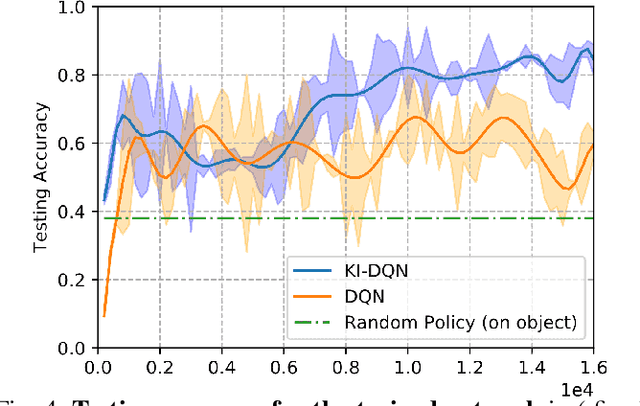
In robotic grasping tasks, robots usually avoid any collisions with the environment and exclusively interact with the target objects. However, the environment can facilitate grasping rather than being obstacles. Indeed, interacting with the environment sometimes provides an alternative strategy when it is not possible to grasp from the top. One example of such tasks is the Slide-to-Wall grasping, where the target object needs to be pushed towards a wall before a feasible grasp can be applied. In this paper, we propose an approach that actively exploits the environment to grasp objects. We formulate the Slide-to-Wall grasping problem as a Markov Decision Process and propose a reinforcement learning approach. Though a standard Deep Q-Network (DQN) method is capable of solving MDP problems, it does not effectively generalize to unseen environment settings that are different from training. To tackle the generalization challenge, we propose a Knowledge Induced DQN (KI-DQN) that not only trains more effectively, but also outperforms the standard DQN significantly in testing cases with unseen walls, and can be directly tested on real robots without fine-tuning while DQN cannot.
A Deep Learning Approach to Grasping the Invisible
Sep 11, 2019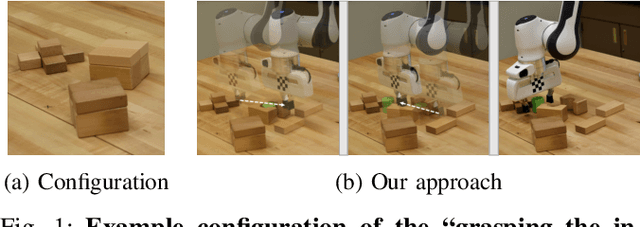

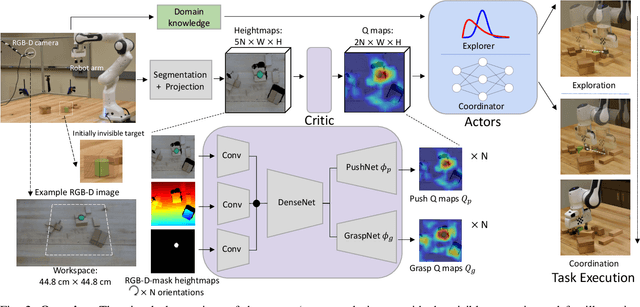
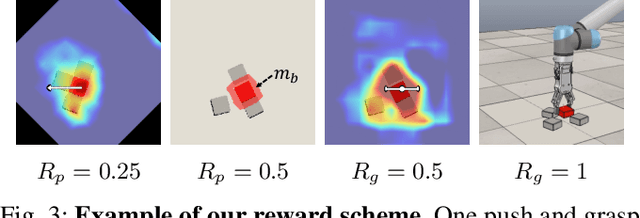
We introduce a new problem named "grasping the invisible", where a robot is tasked to grasp an initially invisible target object via a sequence of non-prehensile (e.g., pushing) and prehensile (e.g., grasping) actions. In this problem, non-prehensile actions are needed to search for the target and rearrange cluttered objects around it. We propose to solve the problem by formulating a deep reinforcement learning approach in an actor-critic format. A critic that maps both the visual observations and the target information to expected rewards of actions is learned via deep Q-learning for instance pushing and grasping. Two actors are proposed to take in the critic predictions and the domain knowledge for two subtasks: a Bayesian-based actor accounting for past experience performs explorational pushing to search for the target; once the target is found, a classifier-based actor coordinates the target-oriented pushing and grasping to grasp the target in clutter. The model is entirely self-supervised through the robot-environment interactions. Our system achieves 93% and 87% task success rate on the two subtasks in simulation and 85% task success rate in real robot experiments, which outperforms several baselines by large margins. Supplementary material is available at: https://sites.google.com/umn.edu/grasping-invisible.