 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-Based Robotic Grasping with One-Grasp Adaptation
Paper and Code
Apr 06, 2021
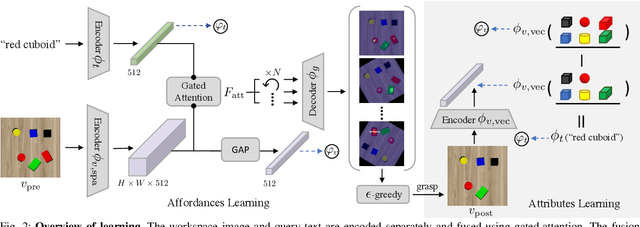


Robotic grasping is one of the most fundamental robotic manipulation tasks and has been actively studied. However, how to quickly teach a robot to grasp a novel target object in clutter remains challenging. This paper attempts to tackle the challenge by leveraging object attributes that facilitate recognition, grasping, and quick adaptation. In this work, we introduce an end-to-end learning method of attribute-based robotic grasping with one-grasp adaptation capability. Our approach fuses the embeddings of a workspace image and a query text using a gated-attention mechanism and learns to predict instance grasping affordances. Besides, we utilize object persistence before and after grasping to learn a joint metric space of visual and textual attributes. Our model is self-supervised in a simulation that only uses basic objects of various colors and shapes but generalizes to novel objects and real-world scenes. We further demonstrate that our model is capable of adapting to novel objects with only one grasp data and improving instance grasping performance significantly. Experimental results in both simulation and the real world demonstrate that our approach achieves over 80\% instance grasping success rate on unknown objects, which outperforms several baselines by large margins.