 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-Based Robotic Grasping with Data-Efficient Adaptation
Jan 04, 2025



Robotic grasping is one of the most fundamental robotic manipulation tasks and has been the subject of extensive research. However, swiftly teaching a robot to grasp a novel target object in clutter remains challenging. This paper attempts to address the challenge by leveraging object attributes that facilitate recognition, grasping, and rapid adaptation to new domains. In this work, we present an end-to-end encoder-decoder network to learn attribute-based robotic grasping with data-efficient adaptation capability. We first pre-train the end-to-end model with a variety of basic objects to learn generic attribute representation for recognition and grasping. Our approach fuses the embeddings of a workspace image and a query text using a gated-attention mechanism and learns to predict instance grasping affordances. To train the joint embedding space of visual and textual attributes, the robot utilizes object persistence before and after grasping. Our model is self-supervised in a simulation that only uses basic objects of various colors and shapes but generalizes to novel objects in new environments. To further facilitate generalization, we propose two adaptation methods, adversarial adaption and one-grasp adaptation. Adversarial adaptation regulates the image encoder using augmented data of unlabeled images, whereas one-grasp adaptation updates the overall end-to-end model using augmented data from one grasp trial. Both adaptation methods are data-efficient and considerably improve instance grasping performance. Experimental results in both simulation and the real world demonstrate that our approach achieves over 81% instance grasping success rate on unknown objects, which outperforms several baselines by large margins.
* Project page: https://z.umn.edu/attr-grasp. arXiv admin note: substantial text overlap with arXiv:2104.02271
Adversarial Object Rearrangement in Constrained Environments with Heterogeneous Graph Neural Networks
Sep 27, 2023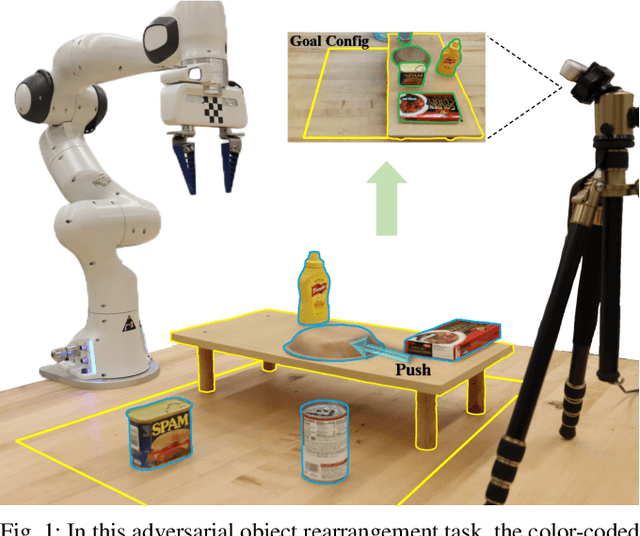
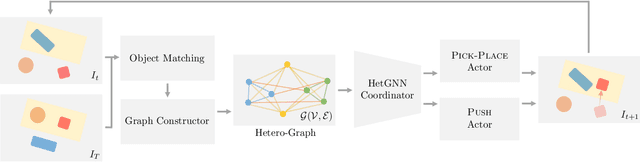
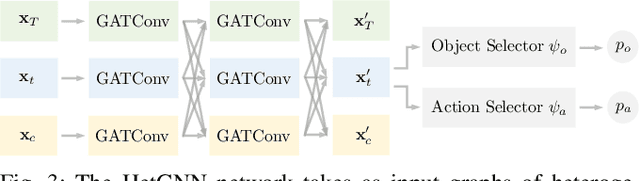

Adversarial object rearrangement in the real world (e.g., previously unseen or oversized items in kitchens and stores) could benefit from understanding task scenes, which inherently entail heterogeneous components such as current objects, goal objects, and environmental constraints. The semantic relationships among these components are distinct from each other and crucial for multi-skilled robots to perform efficiently in everyday scenarios. We propose a hierarchical robotic manipulation system that learns the underlying relationships and maximizes the collaborative power of its diverse skills (e.g., pick-place, push) for rearranging adversarial objects in constrained environments. The high-level coordinator employs a heterogeneous graph neural network (HetGNN), which reasons about the current objects, goal objects, and environmental constraints; the low-level 3D Convolutional Neural Network-based actors execute the action primitives. Our approach is trained entirely in simulation, and achieved an average success rate of 87.88% and a planning cost of 12.82 in real-world experiments, surpassing all baseline methods. Supplementary material is available at https://sites.google.com/umn.edu/versatile-rearrangement.
IOSG: Image-driven Object Searching and Grasping
Aug 10, 2023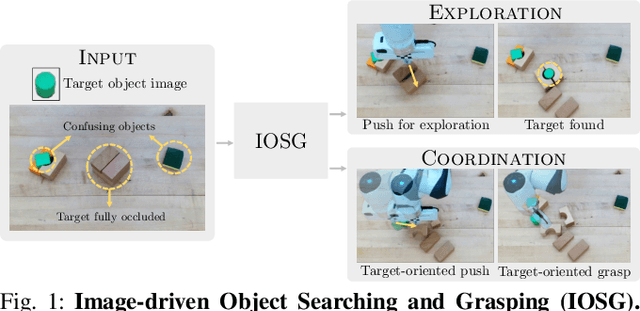
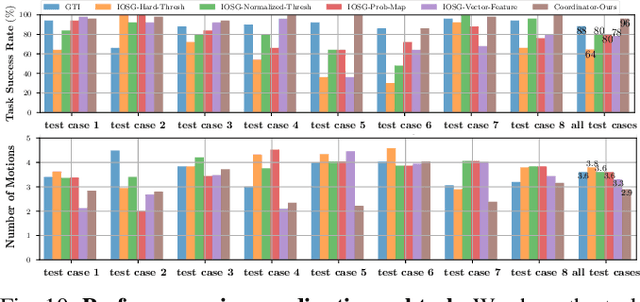

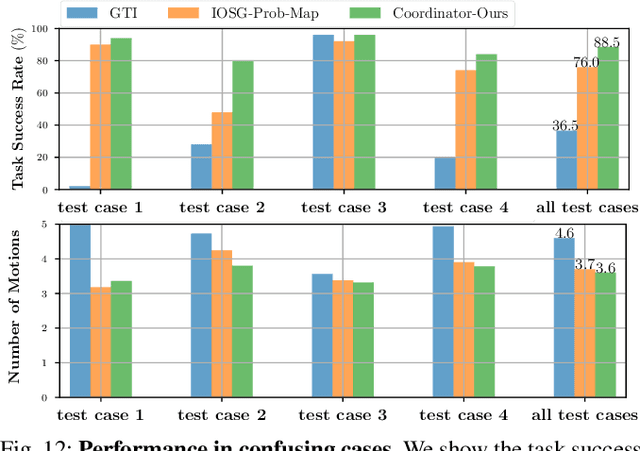
When robots retrieve specific objects from cluttered scenes, such as home and warehouse environments, the target objects are often partially occluded or completely hidden. Robots are thus required to search, identify a target object, and successfully grasp it. Preceding works have relied on pre-trained object recognition or segmentation models to find the target object. However, such methods require laborious manual annotations to train the models and even fail to find novel target objects. In this paper, we propose an Image-driven Object Searching and Grasping (IOSG) approach where a robot is provided with the reference image of a novel target object and tasked to find and retrieve it. We design a Target Similarity Network that generates a probability map to infer the location of the novel target. IOSG learns a hierarchical policy; the high-level policy predicts the subtask type, whereas the low-level policies, explorer and coordinator, generate effective push and grasp actions. The explorer is responsible for searching the target object when it is hidden or occluded by other objects. Once the target object is found, the coordinator conducts target-oriented pushing and grasping to retrieve the target from the clutter. The proposed pipeline is trained with full self-supervision in simulation and applied to a real environment. Our model achieves a 96.0% and 94.5% task success rate on coordination and exploration tasks in simulation respectively, and 85.0% success rate on a real robot for the search-and-grasp task.
Interactive Robotic Grasping with Attribute-Guided Disambiguation
Mar 15, 2022
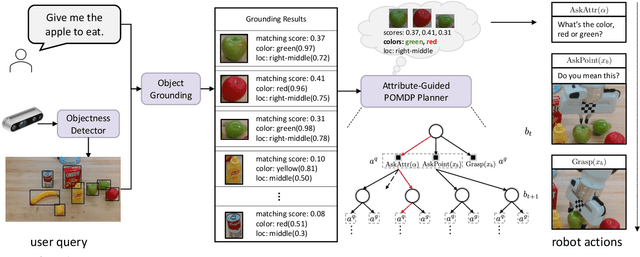

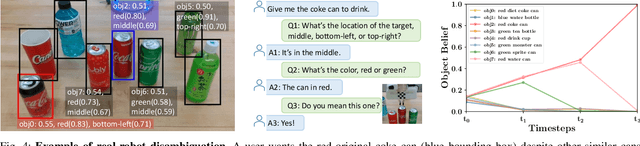
Interactive robotic grasping using natural language is one of the most fundamental tasks in human-robot interaction. However, language can be a source of ambiguity, particularly when there are ambiguous visual or linguistic contents. This paper investigates the use of object attributes in disambiguation and develops an interactive grasping system capable of effectively resolving ambiguities via dialogues. Our approach first predicts target scores and attribute scores through vision-and-language grounding. To handle ambiguous objects and commands, we propose an attribute-guided formulation of the partially observable Markov decision process (Attr-POMDP) for disambiguation. The Attr-POMDP utilizes target and attribute scores as the observation model to calculate the expected return of an attribute-based (e.g., "what is the color of the target, red or green?") or a pointing-based (e.g., "do you mean this one?") question. Our disambiguation module runs in real time on a real robot, and the interactive grasping system achieves a 91.43\% selection accuracy in the real-robot experiments, outperforming several baselines by large margins.
Learning Object Relations with Graph Neural Networks for Target-Driven Grasping in Dense Clutter
Mar 02, 2022
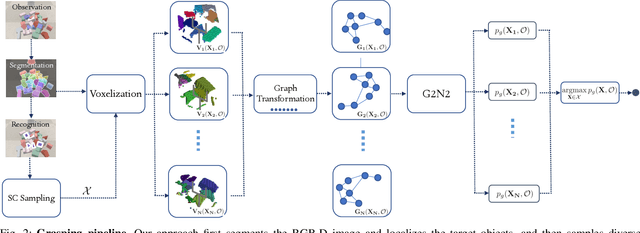
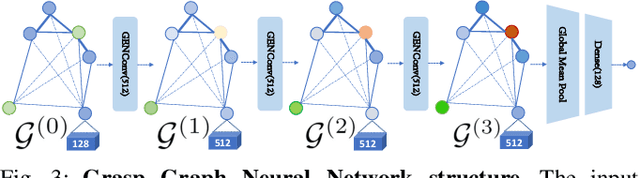
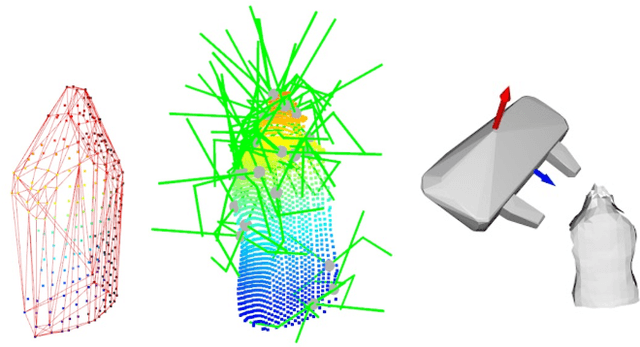
Robots in the real world frequently come across identical objects in dense clutter. When evaluating grasp poses in these scenarios, a target-driven grasping system requires knowledge of spatial relations between scene objects (e.g., proximity, adjacency, and occlusions). To efficiently complete this task, we propose a target-driven grasping system that simultaneously considers object relations and predicts 6-DoF grasp poses. A densely cluttered scene is first formulated as a grasp graph with nodes representing object geometries in the grasp coordinate frame and edges indicating spatial relations between the objects. We design a Grasp Graph Neural Network (G2N2) that evaluates the grasp graph and finds the most feasible 6-DoF grasp pose for a target object. Additionally, we develop a shape completion-assisted grasp pose sampling method that improves sample quality and consequently grasping efficiency. We compare our method against several baselines in both simulated and real settings. In real-world experiments with novel objects, our approach achieves a 77.78% grasping accuracy in densely cluttered scenarios, surpassing the best-performing baseline by more than 15%. Supplementary material is available at https://sites.google.com/umn.edu/graph-grasping.
Attribute-Based Robotic Grasping with One-Grasp Adaptation
Apr 06, 2021
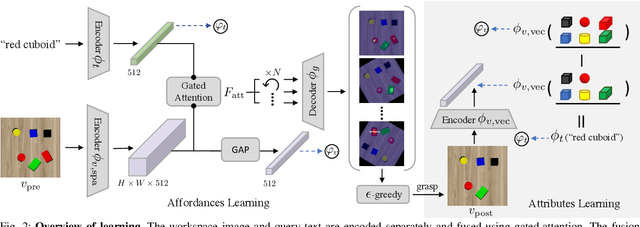


Robotic grasping is one of the most fundamental robotic manipulation tasks and has been actively studied. However, how to quickly teach a robot to grasp a novel target object in clutter remains challenging. This paper attempts to tackle the challenge by leveraging object attributes that facilitate recognition, grasping, and quick adaptation. In this work, we introduce an end-to-end learning method of attribute-based robotic grasping with one-grasp adaptation capability. Our approach fuses the embeddings of a workspace image and a query text using a gated-attention mechanism and learns to predict instance grasping affordances. Besides, we utilize object persistence before and after grasping to learn a joint metric space of visual and textual attributes. Our model is self-supervised in a simulation that only uses basic objects of various colors and shapes but generalizes to novel objects and real-world scenes. We further demonstrate that our model is capable of adapting to novel objects with only one grasp data and improving instance grasping performance significantly. Experimental results in both simulation and the real world demonstrate that our approach achieves over 80\% instance grasping success rate on unknown objects, which outperforms several baselines by large margins.
Collision-Aware Target-Driven Object Grasping in Constrained Environments
Apr 01, 2021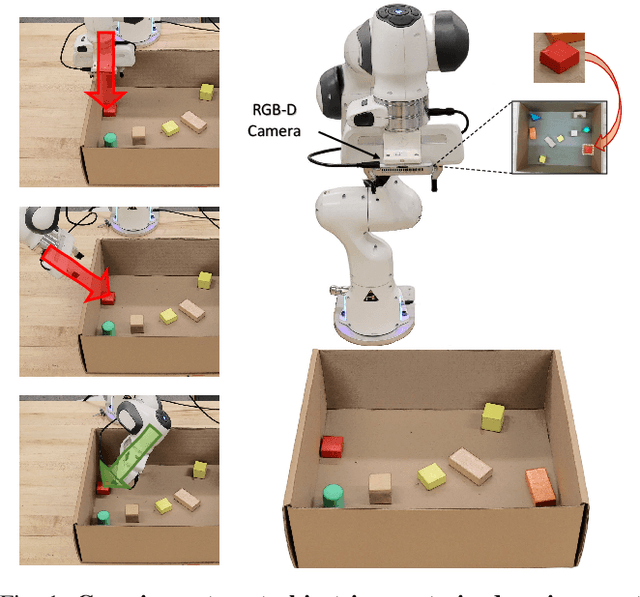
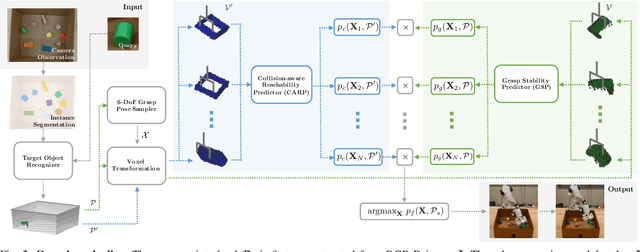
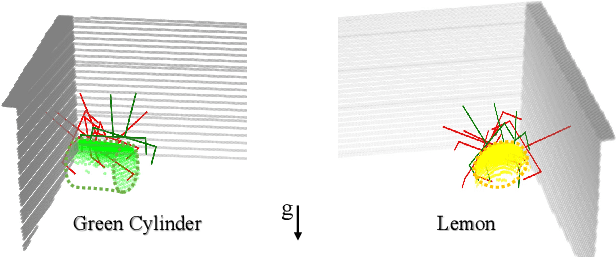
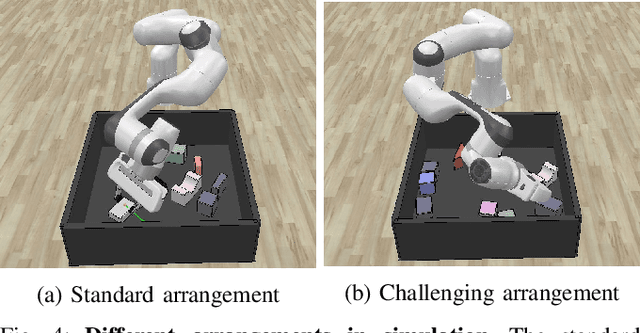
Grasping a novel target object in constrained environments (e.g., walls, bins, and shelves) requires intensive reasoning about grasp pose reachability to avoid collisions with the surrounding structures. Typical 6-DoF robotic grasping systems rely on the prior knowledge about the environment and intensive planning computation, which is ungeneralizable and inefficient. In contrast, we propose a novel Collision-Aware Reachability Predictor (CARP) for 6-DoF grasping systems. The CARP learns to estimate the collision-free probabilities for grasp poses and significantly improves grasping in challenging environments. The deep neural networks in our approach are trained fully by self-supervision in simulation. The experiments in both simulation and the real world show that our approach achieves more than 75% grasping rate on novel objects in various surrounding structures. The ablation study demonstrates the effectiveness of the CARP, which improves the 6-DoF grasping rate by 95.7%.
Learning to Generate 6-DoF Grasp Poses with Reachability Awareness
Oct 28, 2019

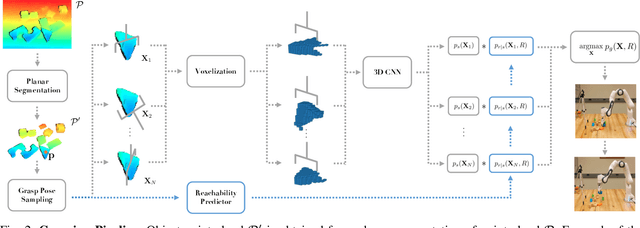
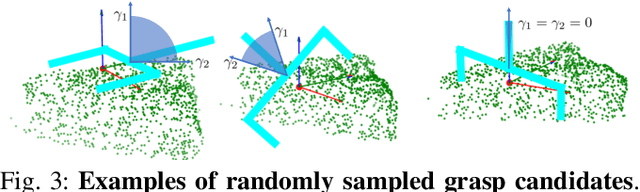
Motivated by the stringent requirements of unstructured real-world where a plethora of unknown objects reside in arbitrary locations of the surface, we propose a voxel-based deep 3D Convolutional Neural Network (3D CNN) that generates feasible 6-DoF grasp poses in unrestricted workspace with reachability awareness. Unlike the majority of works that predict if a proposed grasp pose within the restricted workspace will be successful solely based on grasp pose stability, our approach further learns a reachability predictor that evaluates if the grasp pose is reachable or not from robot's own experience. To avoid the laborious real training data collection, we exploit the power of simulation to train our networks on a large-scale synthetic dataset. This work is an early attempt that simultaneously evaluates grasping reachability from learned knowledge while proposing feasible grasp poses with 3D CNN. Experimental results in both simulation and real-world demonstrate that our approach outperforms several other methods and achieves 82.5\% grasping success rate on unknown objects.
Knowledge Induced Deep Q-Network for a Slide-to-Wall Object Grasping
Oct 09, 2019
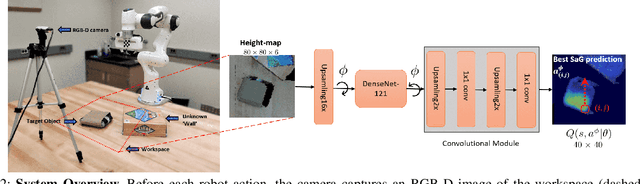

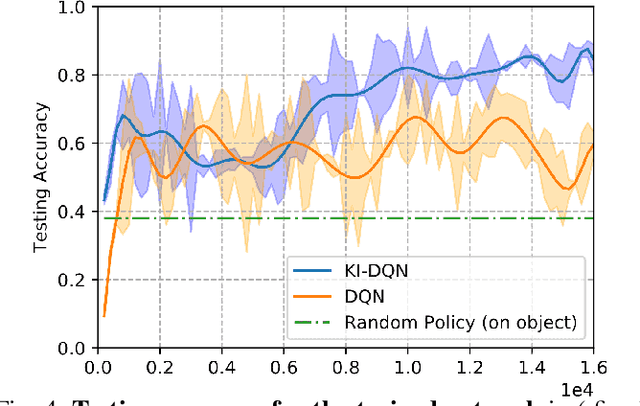
In robotic grasping tasks, robots usually avoid any collisions with the environment and exclusively interact with the target objects. However, the environment can facilitate grasping rather than being obstacles. Indeed, interacting with the environment sometimes provides an alternative strategy when it is not possible to grasp from the top. One example of such tasks is the Slide-to-Wall grasping, where the target object needs to be pushed towards a wall before a feasible grasp can be applied. In this paper, we propose an approach that actively exploits the environment to grasp objects. We formulate the Slide-to-Wall grasping problem as a Markov Decision Process and propose a reinforcement learning approach. Though a standard Deep Q-Network (DQN) method is capable of solving MDP problems, it does not effectively generalize to unseen environment settings that are different from training. To tackle the generalization challenge, we propose a Knowledge Induced DQN (KI-DQN) that not only trains more effectively, but also outperforms the standard DQN significantly in testing cases with unseen walls, and can be directly tested on real robots without fine-tuning while DQN cannot.