 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical DLO Routing with Reinforcement Learning and In-Context Vision-language Models
Oct 22, 2025Long-horizon routing tasks of deformable linear objects (DLOs), such as cables and ropes, are common in industrial assembly lines and everyday life. These tasks are particularly challenging because they require robots to manipulate DLO with long-horizon planning and reliable skill execution. Successfully completing such tasks demands adapting to their nonlinear dynamics, decomposing abstract routing goals, and generating multi-step plans composed of multiple skills, all of which require accurate high-level reasoning during execution. In this paper, we propose a fully autonomous hierarchical framework for solving challenging DLO routing tasks. Given an implicit or explicit routing goal expressed in language, our framework leverages vision-language models~(VLMs) for in-context high-level reasoning to synthesize feasible plans, which are then executed by low-level skills trained via reinforcement learning. To improve robustness in long horizons, we further introduce a failure recovery mechanism that reorients the DLO into insertion-feasible states. Our approach generalizes to diverse scenes involving object attributes, spatial descriptions, as well as implicit language commands. It outperforms the next best baseline method by nearly 50% and achieves an overall success rate of 92.5% across long-horizon routing scenarios.
Attribute-based Object Grounding and Robot Grasp Detection with Spatial Reasoning
Sep 09, 2025Enabling robots to grasp objects specified through natural language is essential for effective human-robot interaction, yet it remains a significant challenge. Existing approaches often struggle with open-form language expressions and typically assume unambiguous target objects without duplicates. Moreover, they frequently rely on costly, dense pixel-wise annotations for both object grounding and grasp configuration. We present Attribute-based Object Grounding and Robotic Grasping (OGRG), a novel framework that interprets open-form language expressions and performs spatial reasoning to ground target objects and predict planar grasp poses, even in scenes containing duplicated object instances. We investigate OGRG in two settings: (1) Referring Grasp Synthesis (RGS) under pixel-wise full supervision, and (2) Referring Grasp Affordance (RGA) using weakly supervised learning with only single-pixel grasp annotations. Key contributions include a bi-directional vision-language fusion module and the integration of depth information to enhance geometric reasoning, improving both grounding and grasping performance. Experiment results show that OGRG outperforms strong baselines in tabletop scenes with diverse spatial language instructions. In RGS, it operates at 17.59 FPS on a single NVIDIA RTX 2080 Ti GPU, enabling potential use in closed-loop or multi-object sequential grasping, while delivering superior grounding and grasp prediction accuracy compared to all the baselines considered. Under the weakly supervised RGA setting, OGRG also surpasses baseline grasp-success rates in both simulation and real-robot trials, underscoring the effectiveness of its spatial reasoning design. Project page: https://z.umn.edu/ogrg
Attribute-Based Robotic Grasping with Data-Efficient Adaptation
Jan 04, 2025



Robotic grasping is one of the most fundamental robotic manipulation tasks and has been the subject of extensive research. However, swiftly teaching a robot to grasp a novel target object in clutter remains challenging. This paper attempts to address the challenge by leveraging object attributes that facilitate recognition, grasping, and rapid adaptation to new domains. In this work, we present an end-to-end encoder-decoder network to learn attribute-based robotic grasping with data-efficient adaptation capability. We first pre-train the end-to-end model with a variety of basic objects to learn generic attribute representation for recognition and grasping. Our approach fuses the embeddings of a workspace image and a query text using a gated-attention mechanism and learns to predict instance grasping affordances. To train the joint embedding space of visual and textual attributes, the robot utilizes object persistence before and after grasping. Our model is self-supervised in a simulation that only uses basic objects of various colors and shapes but generalizes to novel objects in new environments. To further facilitate generalization, we propose two adaptation methods, adversarial adaption and one-grasp adaptation. Adversarial adaptation regulates the image encoder using augmented data of unlabeled images, whereas one-grasp adaptation updates the overall end-to-end model using augmented data from one grasp trial. Both adaptation methods are data-efficient and considerably improve instance grasping performance. Experimental results in both simulation and the real world demonstrate that our approach achieves over 81% instance grasping success rate on unknown objects, which outperforms several baselines by large margins.
* Project page: https://z.umn.edu/attr-grasp. arXiv admin note: substantial text overlap with arXiv:2104.02271
A Parameter-Efficient Tuning Framework for Language-guided Object Grounding and Robot Grasping
Sep 28, 2024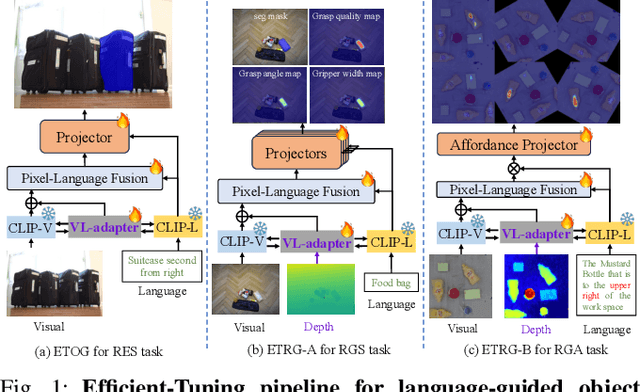
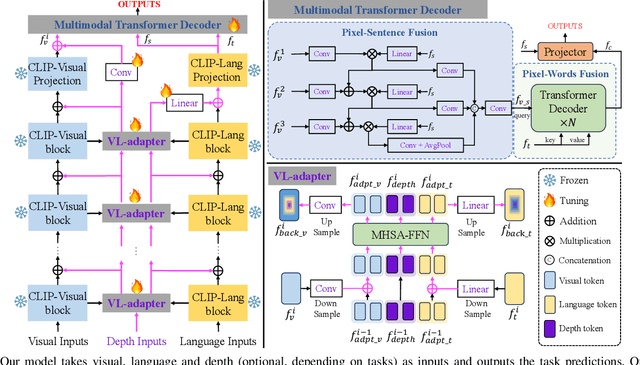
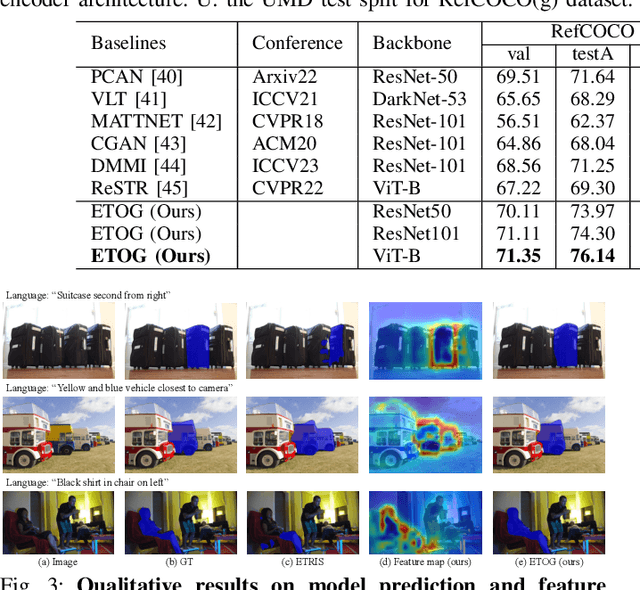

The language-guided robot grasping task requires a robot agent to integrate multimodal information from both visual and linguistic inputs to predict actions for target-driven grasping. While recent approaches utilizing Multimodal Large Language Models (MLLMs) have shown promising results, their extensive computation and data demands limit the feasibility of local deployment and customization. To address this, we propose a novel CLIP-based multimodal parameter-efficient tuning (PET) framework designed for three language-guided object grounding and grasping tasks: (1) Referring Expression Segmentation (RES), (2) Referring Grasp Synthesis (RGS), and (3) Referring Grasp Affordance (RGA). Our approach introduces two key innovations: a bi-directional vision-language adapter that aligns multimodal inputs for pixel-level language understanding and a depth fusion branch that incorporates geometric cues to facilitate robot grasping predictions. Experiment results demonstrate superior performance in the RES object grounding task compared with existing CLIP-based full-model tuning or PET approaches. In the RGS and RGA tasks, our model not only effectively interprets object attributes based on simple language descriptions but also shows strong potential for comprehending complex spatial reasoning scenarios, such as multiple identical objects present in the workspace.
Adversarial Object Rearrangement in Constrained Environments with Heterogeneous Graph Neural Networks
Sep 27, 2023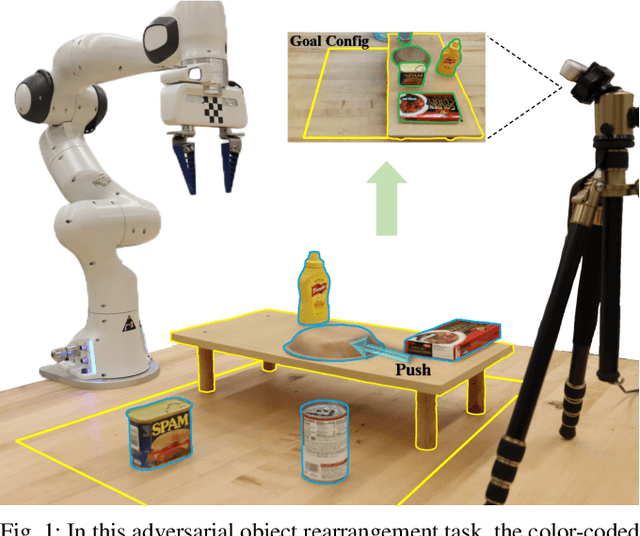
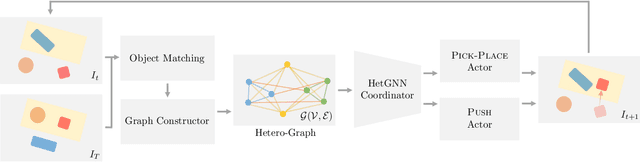
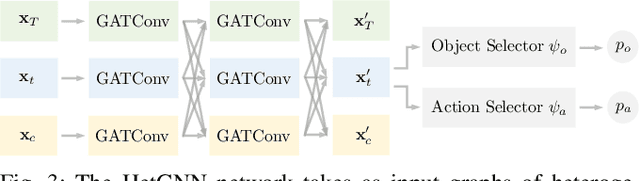

Adversarial object rearrangement in the real world (e.g., previously unseen or oversized items in kitchens and stores) could benefit from understanding task scenes, which inherently entail heterogeneous components such as current objects, goal objects, and environmental constraints. The semantic relationships among these components are distinct from each other and crucial for multi-skilled robots to perform efficiently in everyday scenarios. We propose a hierarchical robotic manipulation system that learns the underlying relationships and maximizes the collaborative power of its diverse skills (e.g., pick-place, push) for rearranging adversarial objects in constrained environments. The high-level coordinator employs a heterogeneous graph neural network (HetGNN), which reasons about the current objects, goal objects, and environmental constraints; the low-level 3D Convolutional Neural Network-based actors execute the action primitives. Our approach is trained entirely in simulation, and achieved an average success rate of 87.88% and a planning cost of 12.82 in real-world experiments, surpassing all baseline methods. Supplementary material is available at https://sites.google.com/umn.edu/versatile-rearrangement.
IOSG: Image-driven Object Searching and Grasping
Aug 10, 2023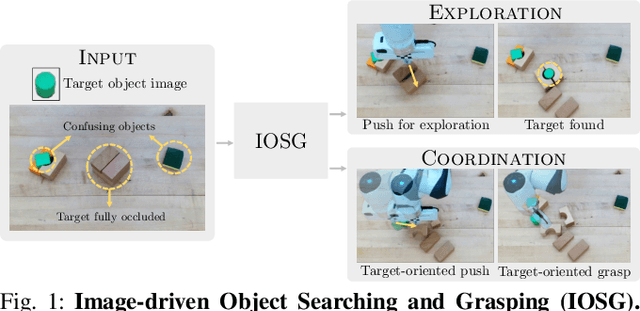
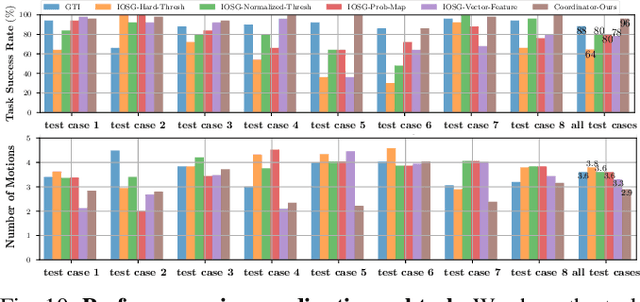

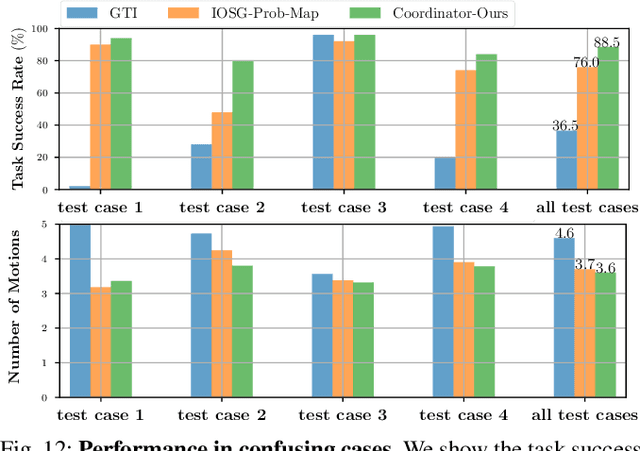
When robots retrieve specific objects from cluttered scenes, such as home and warehouse environments, the target objects are often partially occluded or completely hidden. Robots are thus required to search, identify a target object, and successfully grasp it. Preceding works have relied on pre-trained object recognition or segmentation models to find the target object. However, such methods require laborious manual annotations to train the models and even fail to find novel target objects. In this paper, we propose an Image-driven Object Searching and Grasping (IOSG) approach where a robot is provided with the reference image of a novel target object and tasked to find and retrieve it. We design a Target Similarity Network that generates a probability map to infer the location of the novel target. IOSG learns a hierarchical policy; the high-level policy predicts the subtask type, whereas the low-level policies, explorer and coordinator, generate effective push and grasp actions. The explorer is responsible for searching the target object when it is hidden or occluded by other objects. Once the target object is found, the coordinator conducts target-oriented pushing and grasping to retrieve the target from the clutter. The proposed pipeline is trained with full self-supervision in simulation and applied to a real environment. Our model achieves a 96.0% and 94.5% task success rate on coordination and exploration tasks in simulation respectively, and 85.0% success rate on a real robot for the search-and-grasp task.
Self-Supervised Interactive Object Segmentation Through a Singulation-and-Grasping Approach
Jul 20, 2022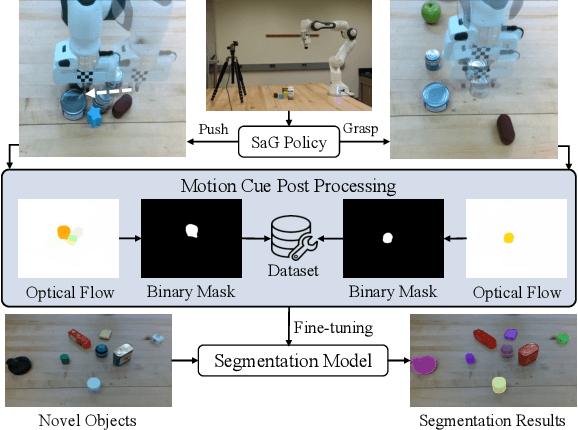
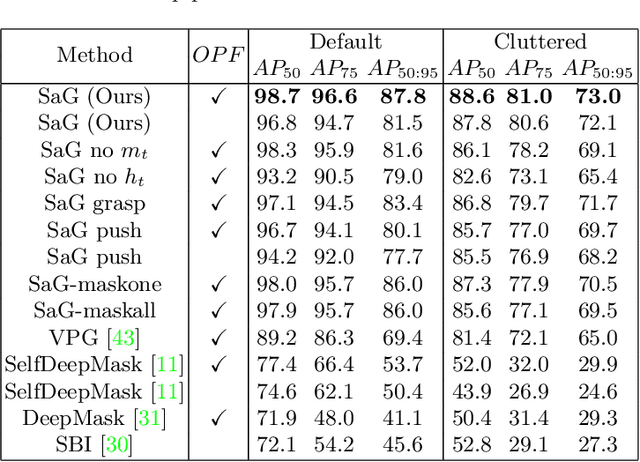
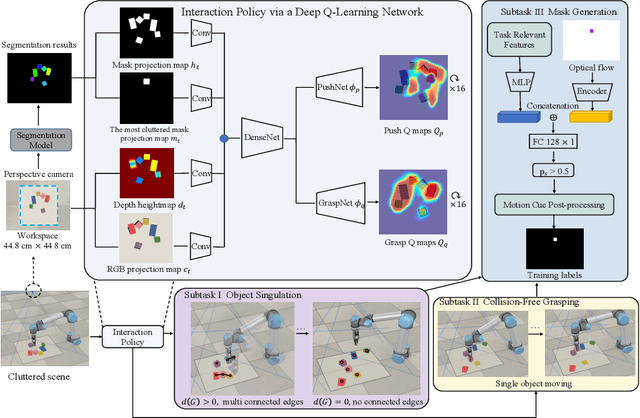
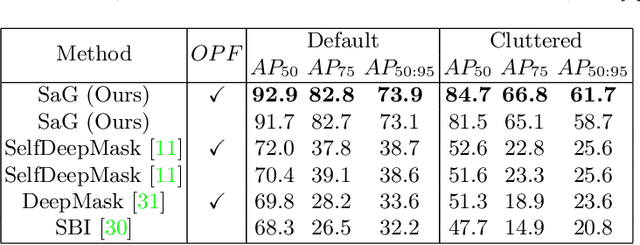
Instance segmentation with unseen objects is a challenging problem in unstructured environments. To solve this problem, we propose a robot learning approach to actively interact with novel objects and collect each object's training label for further fine-tuning to improve the segmentation model performance, while avoiding the time-consuming process of manually labeling a dataset. The Singulation-and-Grasping (SaG) policy is trained through end-to-end reinforcement learning. Given a cluttered pile of objects, our approach chooses pushing and grasping motions to break the clutter and conducts object-agnostic grasping for which the SaG policy takes as input the visual observations and imperfect segmentation. We decompose the problem into three subtasks: (1) the object singulation subtask aims to separate the objects from each other, which creates more space that alleviates the difficulty of (2) the collision-free grasping subtask; (3) the mask generation subtask to obtain the self-labeled ground truth masks by using an optical flow-based binary classifier and motion cue post-processing for transfer learning. Our system achieves 70% singulation success rate in simulated cluttered scenes. The interactive segmentation of our system achieves 87.8%, 73.9%, and 69.3% average precision for toy blocks, YCB objects in simulation and real-world novel objects, respectively, which outperforms several baselines.