 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-Based Robotic Grasping with Data-Efficient Adaptation
Jan 04, 2025



Robotic grasping is one of the most fundamental robotic manipulation tasks and has been the subject of extensive research. However, swiftly teaching a robot to grasp a novel target object in clutter remains challenging. This paper attempts to address the challenge by leveraging object attributes that facilitate recognition, grasping, and rapid adaptation to new domains. In this work, we present an end-to-end encoder-decoder network to learn attribute-based robotic grasping with data-efficient adaptation capability. We first pre-train the end-to-end model with a variety of basic objects to learn generic attribute representation for recognition and grasping. Our approach fuses the embeddings of a workspace image and a query text using a gated-attention mechanism and learns to predict instance grasping affordances. To train the joint embedding space of visual and textual attributes, the robot utilizes object persistence before and after grasping. Our model is self-supervised in a simulation that only uses basic objects of various colors and shapes but generalizes to novel objects in new environments. To further facilitate generalization, we propose two adaptation methods, adversarial adaption and one-grasp adaptation. Adversarial adaptation regulates the image encoder using augmented data of unlabeled images, whereas one-grasp adaptation updates the overall end-to-end model using augmented data from one grasp trial. Both adaptation methods are data-efficient and considerably improve instance grasping performance. Experimental results in both simulation and the real world demonstrate that our approach achieves over 81% instance grasping success rate on unknown objects, which outperforms several baselines by large margins.
* Project page: https://z.umn.edu/attr-grasp. arXiv admin note: substantial text overlap with arXiv:2104.02271
A Dual-Fusion Cognitive Diagnosis Framework for Open Student Learning Environments
Oct 19, 2024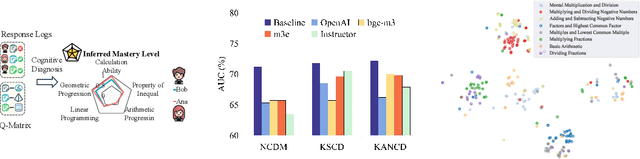

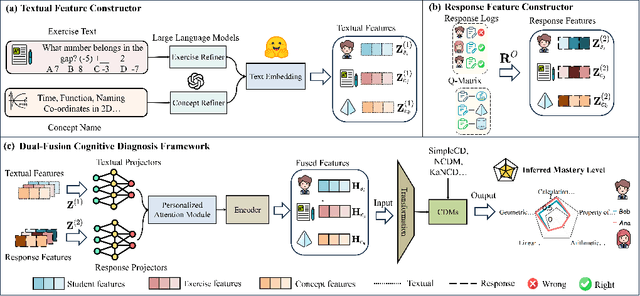
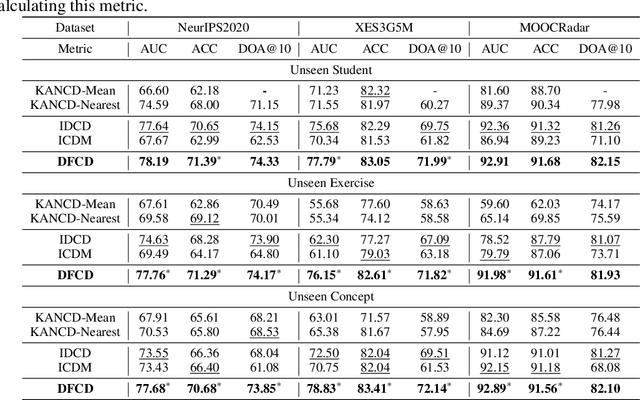
Cognitive diagnosis model (CDM) is a fundamental and upstream component in intelligent education. It aims to infer students' mastery levels based on historical response logs. However, existing CDMs usually follow the ID-based embedding paradigm, which could often diminish the effectiveness of CDMs in open student learning environments. This is mainly because they can hardly directly infer new students' mastery levels or utilize new exercises or knowledge without retraining. Textual semantic information, due to its unified feature space and easy accessibility, can help alleviate this issue. Unfortunately, directly incorporating semantic information may not benefit CDMs, since it does not capture response-relevant features and thus discards the individual characteristics of each student. To this end, this paper proposes a dual-fusion cognitive diagnosis framework (DFCD) to address the challenge of aligning two different modalities, i.e., textual semantic features and response-relevant features. Specifically, in DFCD, we first propose the exercise-refiner and concept-refiner to make the exercises and knowledge concepts more coherent and reasonable via large language models. Then, DFCD encodes the refined features using text embedding models to obtain the semantic information. For response-related features, we propose a novel response matrix to fully incorporate the information within the response logs. Finally, DFCD designs a dual-fusion module to merge the two modal features. The ultimate representations possess the capability of inference in open student learning environments and can be also plugged in existing CDMs. Extensive experiments across real-world datasets show that DFCD achieves superior performance by integrating different modalities and strong adaptability in open student learning environments.
MCNS: Mining Causal Natural Structures Inside Time Series via A Novel Internal Causality Scheme
Sep 13, 2023



Causal inference permits us to discover covert relationships of various variables in time series. However, in most existing works, the variables mentioned above are the dimensions. The causality between dimensions could be cursory, which hinders the comprehension of the internal relationship and the benefit of the causal graph to the neural networks (NNs). In this paper, we find that causality exists not only outside but also inside the time series because it reflects a succession of events in the real world. It inspires us to seek the relationship between internal subsequences. However, the challenges are the hardship of discovering causality from subsequences and utilizing the causal natural structures to improve NNs. To address these challenges, we propose a novel framework called Mining Causal Natural Structure (MCNS), which is automatic and domain-agnostic and helps to find the causal natural structures inside time series via the internal causality scheme. We evaluate the MCNS framework and impregnation NN with MCNS on time series classification tasks. Experimental results illustrate that our impregnation, by refining attention, shape selection classification, and pruning datasets, drives NN, even the data itself preferable accuracy and interpretability. Besides, MCNS provides an in-depth, solid summary of the time series and datasets.
Popularity Debiasing from Exposure to Interaction in Collaborative Filtering
May 09, 2023Recommender systems often suffer from popularity bias, where popular items are overly recommended while sacrificing unpopular items. Existing researches generally focus on ensuring the number of recommendations exposure of each item is equal or proportional, using inverse propensity weighting, causal intervention, or adversarial training. However, increasing the exposure of unpopular items may not bring more clicks or interactions, resulting in skewed benefits and failing in achieving real reasonable popularity debiasing. In this paper, we propose a new criterion for popularity debiasing, i.e., in an unbiased recommender system, both popular and unpopular items should receive Interactions Proportional to the number of users who Like it, namely IPL criterion. Under the guidance of the criterion, we then propose a debiasing framework with IPL regularization term which is theoretically shown to achieve a win-win situation of both popularity debiasing and recommendation performance. Experiments conducted on four public datasets demonstrate that when equipping two representative collaborative filtering models with our framework, the popularity bias is effectively alleviated while maintaining the recommendation performance.
Meta Pattern Concern Score: A Novel Metric for Customizable Evaluation of Multi-classification
Sep 14, 2022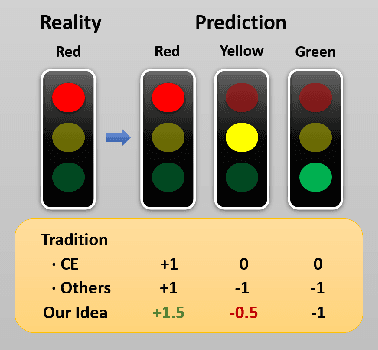
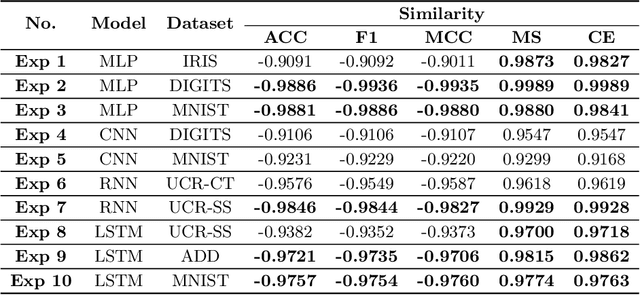

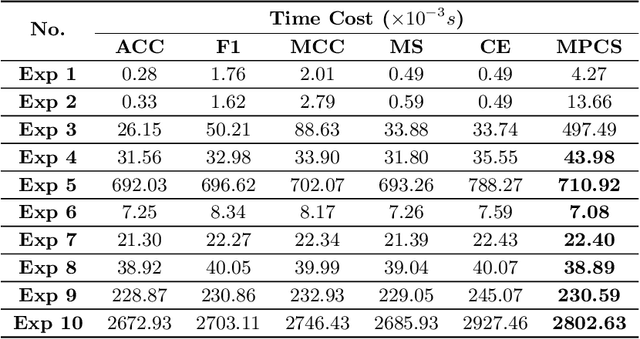
Classifiers have been widely implemented in practice, while how to evaluate them properly remains a problem. Commonly used two types of metrics respectively based on confusion matrix and loss function have different advantages in flexibility and mathematical completeness, while they struggle in different dilemmas like the insensitivity to slight improvements or the lack of customizability in different tasks. In this paper, we propose a novel metric named Meta Pattern Concern Score based on the abstract representation of the probabilistic prediction, as well as the targeted design for processing negative classes in multi-classification and reducing the discreteness of metric value, to achieve advantages of both the two kinds of metrics and avoid their weaknesses. Our metric provides customizability to pick out the model for specific requirements in different practices, and make sure it is also fine under traditional metrics at the same time. Evaluation in four kinds of models and six datasets demonstrates the effectiveness and efficiency of our metric, and a case study shows it can select a model to reduce 0.53% of dangerous misclassifications by sacrificing only 0.04% of training accuracy.
TSFool: Crafting High-quality Adversarial Time Series through Multi-objective Optimization to Fool Recurrent Neural Network Classifiers
Sep 14, 2022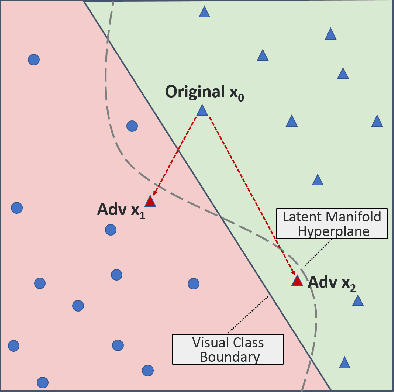
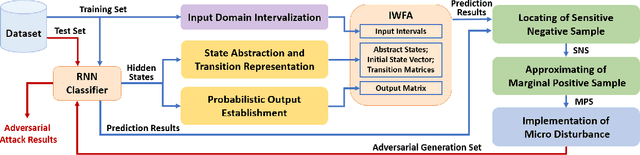
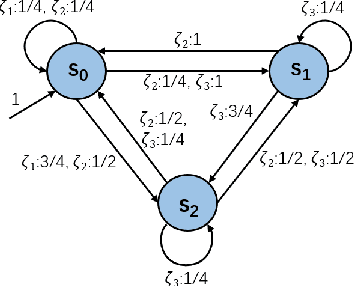

Deep neural network (DNN) classifiers are vulnerable to adversarial attacks. Although the existing gradient-based attacks have achieved good performance in feed-forward model and image recognition tasks, the extension for time series classification in the recurrent neural network (RNN) remains a dilemma, because the cyclical structure of RNN prevents direct model differentiation and the visual sensitivity to perturbations of time series data challenges the traditional local optimization objective to minimize perturbation. In this paper, an efficient and widely applicable approach called TSFool for crafting high-quality adversarial time series for the RNN classifier is proposed. We propose a novel global optimization objective named Camouflage Coefficient to consider how well the adversarial samples hide in class clusters, and accordingly redefine the high-quality adversarial attack as a multi-objective optimization problem. We also propose a new idea to use intervalized weighted finite automata (IWFA) to capture deeply embedded vulnerable samples having otherness between features and latent manifold to guide the approximation to the optimization solution. Experiments on 22 UCR datasets are conducted to confirm that TSFool is a widely effective, efficient and high-quality approach with 93.22% less local perturbation, 32.33% better global camouflage, and 1.12 times speedup to existing methods.
A Novel Initialization Method for HybridUnderwater Optical Acoustic Networks
Sep 29, 2021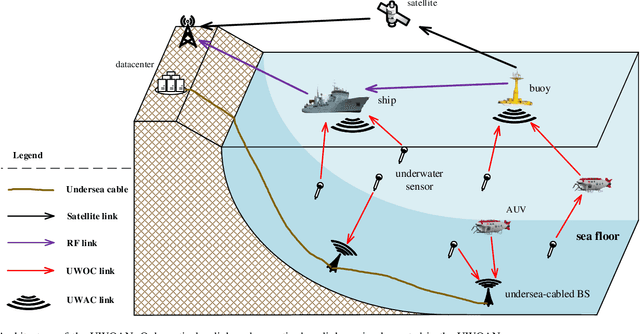
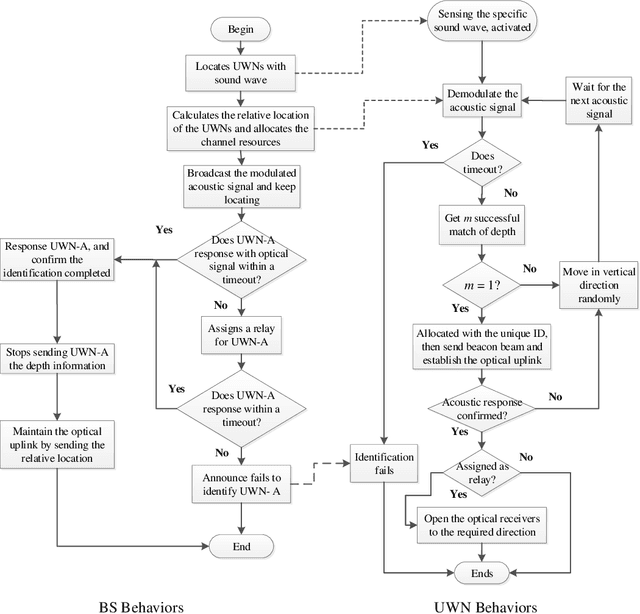
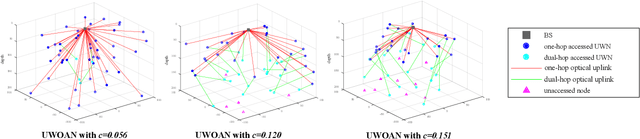
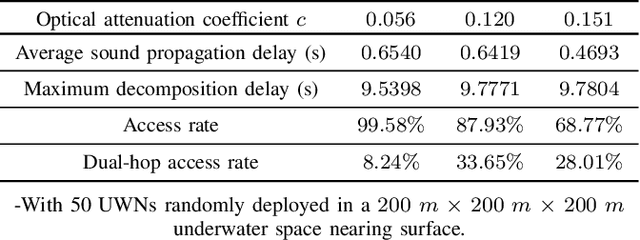
To satisfy the high data rate requirement andreliable transmission demands in underwater scenarios, it isdesirable to construct an efficient hybrid underwater opticalacoustic network (UWOAN) architecture by considering the keyfeatures and critical needs of underwater terminals. In UWOANs,optical uplinks and acoustic downlinks are configured betweenunderwater nodes (UWNs) and the base station (BS), wherethe optical beam transmits the high data rate traffic to theBS, while the acoustic waves carry the control information torealize the network management. In this paper, we focus onsolving the network initializing problem in UWOANs, which isa challenging task due to the lack of GPS service and limiteddevice payload in underwater environments. To this end, weleverage acoustic waves for node localization and propose anovel network initialization method, which consists of UWNidentification, discovery, localization, as well as decomposition.Numerical simulations are also conducted to verify the proposedinitialization method.
Throughput Maximization Leveraging Just-Enough SNR Margin and Channel Spacing Optimization
Jun 14, 2021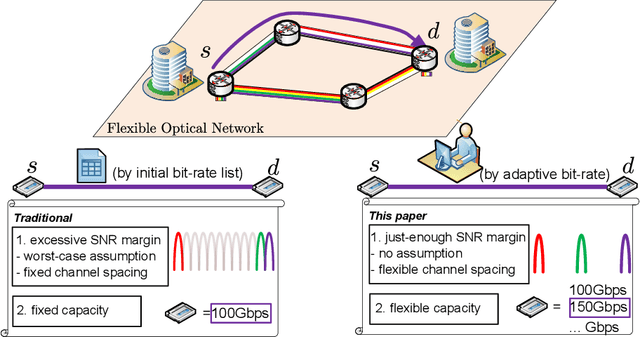



Flexible optical network is a promising technology to accommodate high-capacity demands in next-generation networks. To ensure uninterrupted communication, existing lightpath provisioning schemes are mainly done with the assumption of worst-case resource under-provisioning and fixed channel spacing, which preserves an excessive signal-to-noise ratio (SNR) margin. However, under a resource over-provisioning scenario, the excessive SNR margin restricts the transmission bit-rate, leading to physical layer resource waste and stranded transmission capacity. To tackle this challenging problem, we leverage an iterative feedback tuning algorithm to provide a just-enough SNR margin, so as to maximize the network throughput. Specifically, the proposed algorithm is implemented in three steps. First, starting from the high SNR margin setup, we establish an integer linear programming model as well as a heuristic algorithm to maximize the network throughput by solving the problem of routing, modulation format, forward error correction, baud-rate selection, and spectrum assignment. Second, we optimize the channel spacing of the lightpaths obtained from the previous step, thereby increasing the available physical layer resources. Finally, we iteratively reduce the SNR margin of each lightpath until the network throughput cannot be increased. Through numerical simulations, we confirm the throughput improvement in different networks and with different baud-rates. In particular, we find that our algorithm enables over 20\% relative gain when network resource is over-provisioned, compared to the traditional method preserving an excessive SNR margin.
Attribute-Based Robotic Grasping with One-Grasp Adaptation
Apr 06, 2021
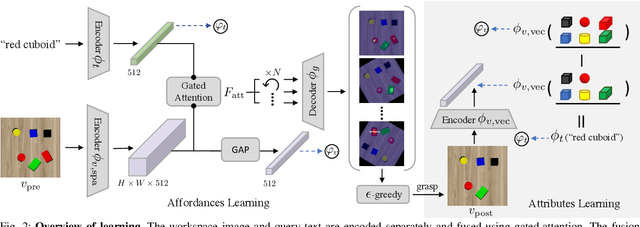


Robotic grasping is one of the most fundamental robotic manipulation tasks and has been actively studied. However, how to quickly teach a robot to grasp a novel target object in clutter remains challenging. This paper attempts to tackle the challenge by leveraging object attributes that facilitate recognition, grasping, and quick adaptation. In this work, we introduce an end-to-end learning method of attribute-based robotic grasping with one-grasp adaptation capability. Our approach fuses the embeddings of a workspace image and a query text using a gated-attention mechanism and learns to predict instance grasping affordances. Besides, we utilize object persistence before and after grasping to learn a joint metric space of visual and textual attributes. Our model is self-supervised in a simulation that only uses basic objects of various colors and shapes but generalizes to novel objects and real-world scenes. We further demonstrate that our model is capable of adapting to novel objects with only one grasp data and improving instance grasping performance significantly. Experimental results in both simulation and the real world demonstrate that our approach achieves over 80\% instance grasping success rate on unknown objects, which outperforms several baselines by large margins.
Word Segmentation as Graph Partition
Apr 05, 2018

We propose a new approach to the Chinese word segmentation problem that considers the sentence as an undirected graph, whose nodes are the characters. One can use various techniques to compute the edge weights that measure the connection strength between characters. Spectral graph partition algorithms are used to group the characters and achieve word segmentation. We follow the graph partition approach and design several unsupervised algorithms, and we show their inspiring segmentation results on two corpora: (1) electronic health records in Chinese, and (2) benchmark data from the Second International Chinese Word Segmentation Bakeoff.