 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical DLO Routing with Reinforcement Learning and In-Context Vision-language Models
Oct 22, 2025Long-horizon routing tasks of deformable linear objects (DLOs), such as cables and ropes, are common in industrial assembly lines and everyday life. These tasks are particularly challenging because they require robots to manipulate DLO with long-horizon planning and reliable skill execution. Successfully completing such tasks demands adapting to their nonlinear dynamics, decomposing abstract routing goals, and generating multi-step plans composed of multiple skills, all of which require accurate high-level reasoning during execution. In this paper, we propose a fully autonomous hierarchical framework for solving challenging DLO routing tasks. Given an implicit or explicit routing goal expressed in language, our framework leverages vision-language models~(VLMs) for in-context high-level reasoning to synthesize feasible plans, which are then executed by low-level skills trained via reinforcement learning. To improve robustness in long horizons, we further introduce a failure recovery mechanism that reorients the DLO into insertion-feasible states. Our approach generalizes to diverse scenes involving object attributes, spatial descriptions, as well as implicit language commands. It outperforms the next best baseline method by nearly 50% and achieves an overall success rate of 92.5% across long-horizon routing scenarios.
Learning for Deformable Linear Object Insertion Leveraging Flexibility Estimation from Visual Cues
Oct 30, 2024



Manipulation of deformable Linear objects (DLOs), including iron wire, rubber, silk, and nylon rope, is ubiquitous in daily life. These objects exhibit diverse physical properties, such as Young$'$s modulus and bending stiffness.Such diversity poses challenges for developing generalized manipulation policies. However, previous research limited their scope to single-material DLOs and engaged in time-consuming data collection for the state estimation. In this paper, we propose a two-stage manipulation approach consisting of a material property (e.g., flexibility) estimation and policy learning for DLO insertion with reinforcement learning. Firstly, we design a flexibility estimation scheme that characterizes the properties of different types of DLOs. The ground truth flexibility data is collected in simulation to train our flexibility estimation module. During the manipulation, the robot interacts with the DLOs to estimate flexibility by analyzing their visual configurations. Secondly, we train a policy conditioned on the estimated flexibility to perform challenging DLO insertion tasks. Our pipeline trained with diverse insertion scenarios achieves an 85.6% success rate in simulation and 66.67% in real robot experiments. Please refer to our project page: https://lmeee.github.io/DLOInsert/
* 7 pages, 9 figures, 3 tables. 2024 IEEE International Conference on Robotics and Automation (ICRA)
A Parameter-Efficient Tuning Framework for Language-guided Object Grounding and Robot Grasping
Sep 28, 2024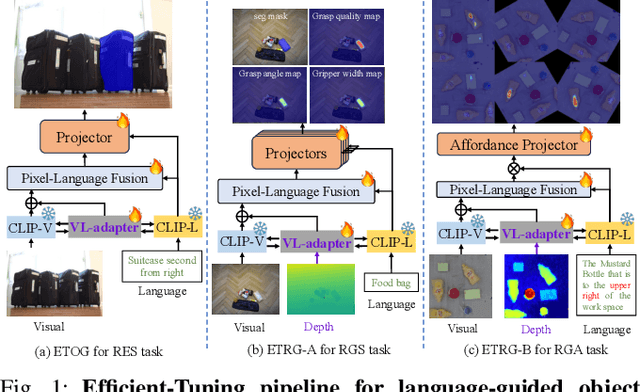
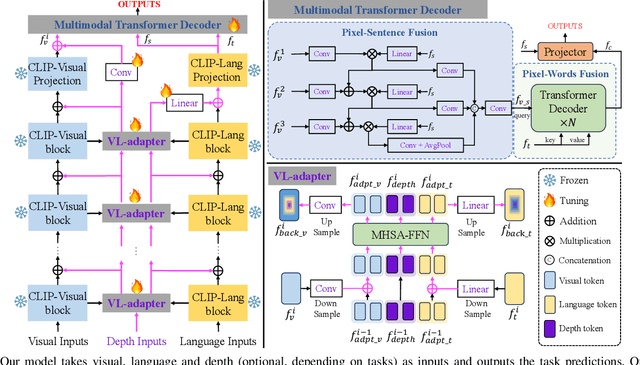
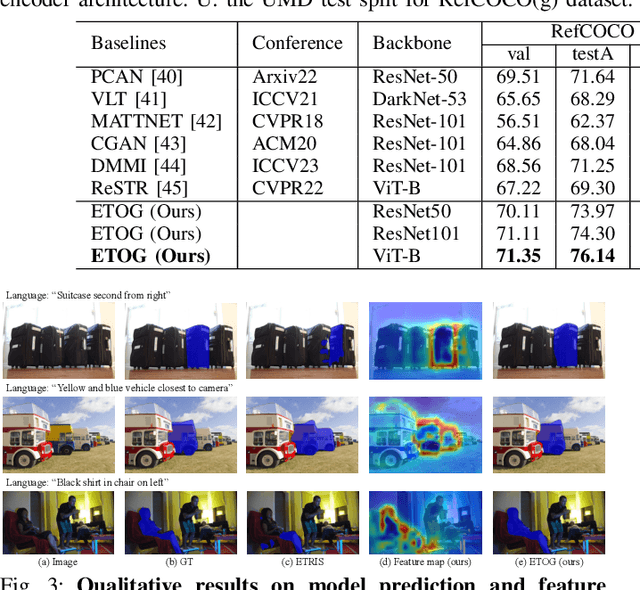

The language-guided robot grasping task requires a robot agent to integrate multimodal information from both visual and linguistic inputs to predict actions for target-driven grasping. While recent approaches utilizing Multimodal Large Language Models (MLLMs) have shown promising results, their extensive computation and data demands limit the feasibility of local deployment and customization. To address this, we propose a novel CLIP-based multimodal parameter-efficient tuning (PET) framework designed for three language-guided object grounding and grasping tasks: (1) Referring Expression Segmentation (RES), (2) Referring Grasp Synthesis (RGS), and (3) Referring Grasp Affordance (RGA). Our approach introduces two key innovations: a bi-directional vision-language adapter that aligns multimodal inputs for pixel-level language understanding and a depth fusion branch that incorporates geometric cues to facilitate robot grasping predictions. Experiment results demonstrate superior performance in the RES object grounding task compared with existing CLIP-based full-model tuning or PET approaches. In the RGS and RGA tasks, our model not only effectively interprets object attributes based on simple language descriptions but also shows strong potential for comprehending complex spatial reasoning scenarios, such as multiple identical objects present in the workspace.
Differentiable Robotic Manipulation of Deformable Rope-like Objects Using Compliant Position-based Dynamics
Feb 20, 2022

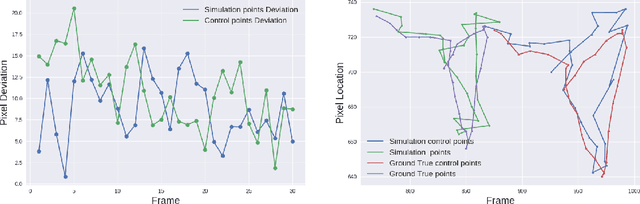
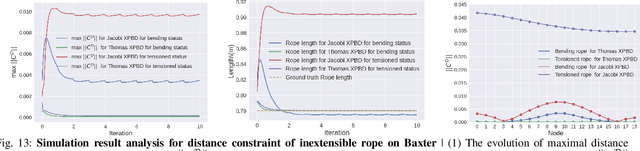
Robot manipulation of rope-like objects is an interesting problem that has some critical applications, such as autonomous robotic suturing. Solving for and controlling rope is difficult due to the complexity of rope physics and the challenge of building fast and accurate models of deformable materials. While more data-driven approaches have become more popular for finding controllers that learn to do a single task, there is still a strong motivation for a model-based method that could be used to solve a large variety of optimization problems. Towards this end, we introduced compliant, position-based dynamics (XPBD) to model rope-like objects. Using geometric constraints, the model can represent the coupling of shear/stretch and bend/twist effects. Of crucial importance is that our formulation is differentiable, which can solve parameter estimation problems and improve the matching of rope physics to real-life scenarios (i.e., the real-to-sim problem). For the generality of rope-like objects, two different solvers are proposed to handle the inextensible and extensible effects of varied material stiffness for the rope. We demonstrate our framework's robustness and accuracy on real-to-sim experimental setups using the Baxter robot and the da Vinci research kit (DVRK). Our work leads to a new path for robotic manipulation of the deformable rope-like object taking advantage of the ready-to-use gradients.
Parameter Identification and Motion Control for Articulated Rigid Body Robots Using Differentiable Position-based Dynamics
Jan 15, 2022
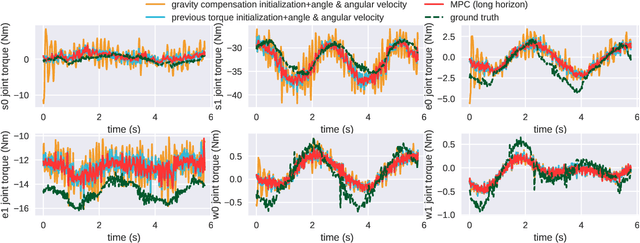
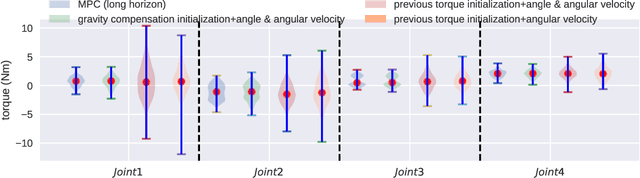
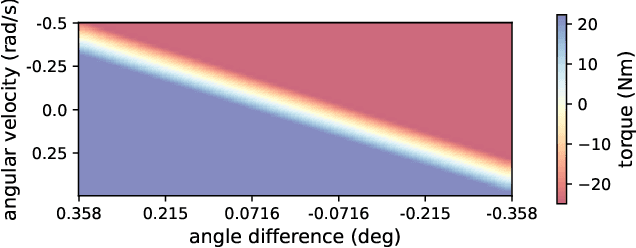
Simulation modeling of robots, objects, and environments is the backbone for all model-based control and learning. It is leveraged broadly across dynamic programming and model-predictive control, as well as data generation for imitation, transfer, and reinforcement learning. In addition to fidelity, key features of models in these control and learning contexts are speed, stability, and native differentiability. However, many popular simulation platforms for robotics today lack at least one of the features above. More recently, position-based dynamics (PBD) has become a very popular simulation tool for modeling complex scenes of rigid and non-rigid object interactions, due to its speed and stability, and is starting to gain significant interest in robotics for its potential use in model-based control and learning. Thus, in this paper, we present a mathematical formulation for coupling position-based dynamics (PBD) simulation and optimal robot design, model-based motion control and system identification. Our framework breaks down PBD definitions and derivations for various types of joint-based articulated rigid bodies. We present a back-propagation method with automatic differentiation, which can integrate both positional and angular geometric constraints. Our framework can critically provide the native gradient information and perform gradient-based optimization tasks. We also propose articulated joint model representations and simulation workflow for our differentiable framework. We demonstrate the capability of the framework in efficient optimal robot design, accurate trajectory torque estimation and supporting spring stiffness estimation, where we achieve minor errors. We also implement impedance control in real robots to demonstrate the potential of our differentiable framework in human-in-the-loop applications.