 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCtRNet-X: Camera-to-Robot Pose Estimation in Real-world Conditions Using a Single Camera
Sep 16, 2024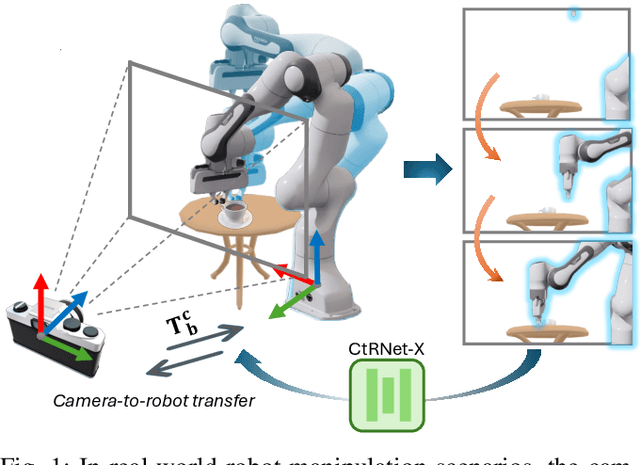

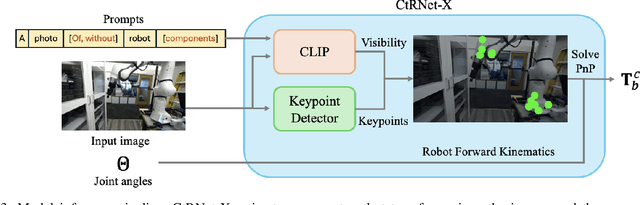
Camera-to-robot calibration is crucial for vision-based robot control and requires effort to make it accurate. Recent advancements in markerless pose estimation methods have eliminated the need for time-consuming physical setups for camera-to-robot calibration. While the existing markerless pose estimation methods have demonstrated impressive accuracy without the need for cumbersome setups, they rely on the assumption that all the robot joints are visible within the camera's field of view. However, in practice, robots usually move in and out of view, and some portion of the robot may stay out-of-frame during the whole manipulation task due to real-world constraints, leading to a lack of sufficient visual features and subsequent failure of these approaches. To address this challenge and enhance the applicability to vision-based robot control, we propose a novel framework capable of estimating the robot pose with partially visible robot manipulators. Our approach leverages the Vision-Language Models for fine-grained robot components detection, and integrates it into a keypoint-based pose estimation network, which enables more robust performance in varied operational conditions. The framework is evaluated on both public robot datasets and self-collected partial-view datasets to demonstrate our robustness and generalizability. As a result, this method is effective for robot pose estimation in a wider range of real-world manipulation scenarios.
HemoSet: The First Blood Segmentation Dataset for Automation of Hemostasis Management
Mar 24, 2024



Hemorrhaging occurs in surgeries of all types, forcing surgeons to quickly adapt to the visual interference that results from blood rapidly filling the surgical field. Introducing automation into the crucial surgical task of hemostasis management would offload mental and physical tasks from the surgeon and surgical assistants while simultaneously increasing the efficiency and safety of the operation. The first step in automation of hemostasis management is detection of blood in the surgical field. To propel the development of blood detection algorithms in surgeries, we present HemoSet, the first blood segmentation dataset based on bleeding during a live animal robotic surgery. Our dataset features vessel hemorrhage scenarios where turbulent flow leads to abnormal pooling geometries in surgical fields. These pools are formed in conditions endemic to surgical procedures -- uneven heterogeneous tissue, under glossy lighting conditions and rapid tool movement. We benchmark several state-of-the-art segmentation models and provide insight into the difficulties specific to blood detection. We intend for HemoSet to spur development of autonomous blood suction tools by providing a platform for training and refining blood segmentation models, addressing the precision needed for such robotics.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



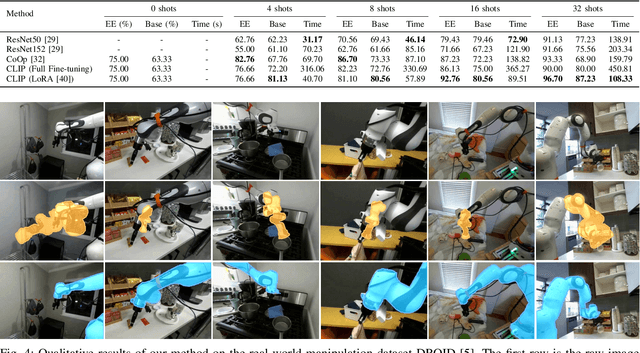
The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
BASED: Bundle-Adjusting Surgical Endoscopic Dynamic Video Reconstruction using Neural Radiance Fields
Sep 27, 2023Reconstruction of deformable scenes from endoscopic videos is important for many applications such as intraoperative navigation, surgical visual perception, and robotic surgery. It is a foundational requirement for realizing autonomous robotic interventions for minimally invasive surgery. However, previous approaches in this domain have been limited by their modular nature and are confined to specific camera and scene settings. Our work adopts the Neural Radiance Fields (NeRF) approach to learning 3D implicit representations of scenes that are both dynamic and deformable over time, and furthermore with unknown camera poses. We demonstrate this approach on endoscopic surgical scenes from robotic surgery. This work removes the constraints of known camera poses and overcomes the drawbacks of the state-of-the-art unstructured dynamic scene reconstruction technique, which relies on the static part of the scene for accurate reconstruction. Through several experimental datasets, we demonstrate the versatility of our proposed model to adapt to diverse camera and scene settings, and show its promise for both current and future robotic surgical systems.
Tracking Snake-like Robots in the Wild Using Only a Single Camera
Sep 27, 2023



Robot navigation within complex environments requires precise state estimation and localization to ensure robust and safe operations. For ambulating mobile robots like robot snakes, traditional methods for sensing require multiple embedded sensors or markers, leading to increased complexity, cost, and increased points of failure. Alternatively, deploying an external camera in the environment is very easy to do, and marker-less state estimation of the robot from this camera's images is an ideal solution: both simple and cost-effective. However, the challenge in this process is in tracking the robot under larger environments where the cameras may be moved around without extrinsic calibration, or maybe when in motion (e.g., a drone following the robot). The scenario itself presents a complex challenge: single-image reconstruction of robot poses under noisy observations. In this paper, we address the problem of tracking ambulatory mobile robots from a single camera. The method combines differentiable rendering with the Kalman filter. This synergy allows for simultaneous estimation of the robot's joint angle and pose while also providing state uncertainty which could be used later on for robust control. We demonstrate the efficacy of our approach on a snake-like robot in both stationary and non-stationary (moving) cameras, validating its performance in both structured and unstructured scenarios. The results achieved show an average error of 0.05 m in localizing the robot's base position and 6 degrees in joint state estimation. We believe this novel technique opens up possibilities for enhanced robot mobility and navigation in future exploratory and search-and-rescue missions.
SuPerPM: A Large Deformation-Robust Surgical Perception Framework Based on Deep Point Matching Learned from Physical Constrained Simulation Data
Sep 25, 2023Manipulation of tissue with surgical tools often results in large deformations that current methods in tracking and reconstructing algorithms have not effectively addressed. A major source of tracking errors during large deformations stems from wrong data association between observed sensor measurements with previously tracked scene. To mitigate this issue, we present a surgical perception framework, SuPerPM, that leverages learning-based non-rigid point cloud matching for data association, thus accommodating larger deformations. The learning models typically require training data with ground truth point cloud correspondences, which is challenging or even impractical to collect in surgical environments. Thus, for tuning the learning model, we gather endoscopic data of soft tissue being manipulated by a surgical robot and then establish correspondences between point clouds at different time points to serve as ground truth. This was achieved by employing a position-based dynamics (PBD) simulation to ensure that the correspondences adhered to physical constraints. The proposed framework is demonstrated on several challenging surgical datasets that are characterized by large deformations, achieving superior performance over state-of-the-art surgical scene tracking algorithms.
BAA-NGP: Bundle-Adjusting Accelerated Neural Graphics Primitives
Jun 09, 2023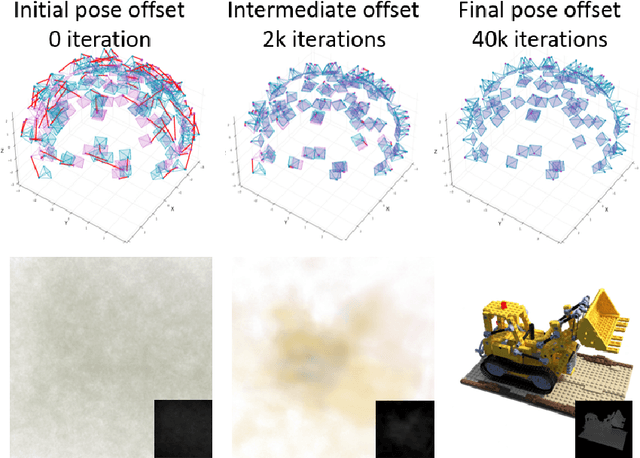
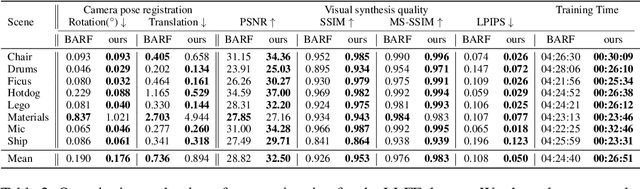
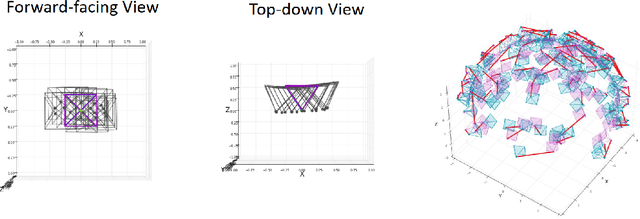
Implicit neural representation has emerged as a powerful method for reconstructing 3D scenes from 2D images. Given a set of camera poses and associated images, the models can be trained to synthesize novel, unseen views. In order to expand the use cases for implicit neural representations, we need to incorporate camera pose estimation capabilities as part of the representation learning, as this is necessary for reconstructing scenes from real-world video sequences where cameras are generally not being tracked. Existing approaches like COLMAP and, most recently, bundle-adjusting neural radiance field methods often suffer from lengthy processing times. These delays ranging from hours to days, arise from laborious feature matching, hardware limitations, dense point sampling, and long training times required by a multi-layer perceptron structure with a large number of parameters. To address these challenges, we propose a framework called bundle-adjusting accelerated neural graphics primitives (BAA-NGP). Our approach leverages accelerated sampling and hash encoding to expedite both pose refinement/estimation and 3D scene reconstruction. Experimental results demonstrate that our method achieves a more than 10 to 20 $\times$ speed improvement in novel view synthesis compared to other bundle-adjusting neural radiance field methods without sacrificing the quality of pose estimation.
Markerless Camera-to-Robot Pose Estimation via Self-supervised Sim-to-Real Transfer
Mar 21, 2023



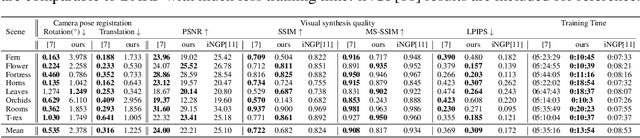
Solving the camera-to-robot pose is a fundamental requirement for vision-based robot control, and is a process that takes considerable effort and cares to make accurate. Traditional approaches require modification of the robot via markers, and subsequent deep learning approaches enabled markerless feature extraction. Mainstream deep learning methods only use synthetic data and rely on Domain Randomization to fill the sim-to-real gap, because acquiring the 3D annotation is labor-intensive. In this work, we go beyond the limitation of 3D annotations for real-world data. We propose an end-to-end pose estimation framework that is capable of online camera-to-robot calibration and a self-supervised training method to scale the training to unlabeled real-world data. Our framework combines deep learning and geometric vision for solving the robot pose, and the pipeline is fully differentiable. To train the Camera-to-Robot Pose Estimation Network (CtRNet), we leverage foreground segmentation and differentiable rendering for image-level self-supervision. The pose prediction is visualized through a renderer and the image loss with the input image is back-propagated to train the neural network. Our experimental results on two public real datasets confirm the effectiveness of our approach over existing works. We also integrate our framework into a visual servoing system to demonstrate the promise of real-time precise robot pose estimation for automation tasks.
Image-based Pose Estimation and Shape Reconstruction for Robot Manipulators and Soft, Continuum Robots via Differentiable Rendering
Feb 27, 2023

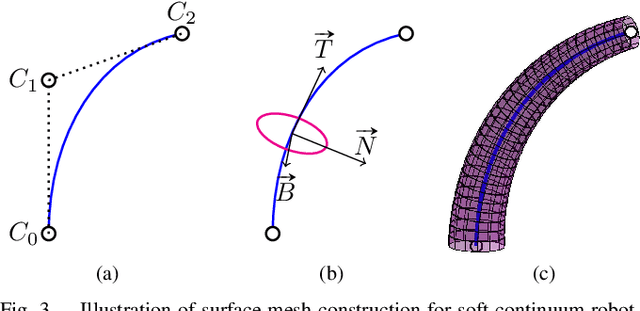

State estimation from measured data is crucial for robotic applications as autonomous systems rely on sensors to capture the motion and localize in the 3D world. Among sensors that are designed for measuring a robot's pose, or for soft robots, their shape, vision sensors are favorable because they are information-rich, easy to set up, and cost-effective. With recent advancements in computer vision, deep learning-based methods no longer require markers for identifying feature points on the robot. However, learning-based methods are data-hungry and hence not suitable for soft and prototyping robots, as building such bench-marking datasets is usually infeasible. In this work, we achieve image-based robot pose estimation and shape reconstruction from camera images. Our method requires no precise robot meshes, but rather utilizes a differentiable renderer and primitive shapes. It hence can be applied to robots for which CAD models might not be available or are crude. Our parameter estimation pipeline is fully differentiable. The robot shape and pose are estimated iteratively by back-propagating the image loss to update the parameters. We demonstrate that our method of using geometrical shape primitives can achieve high accuracy in shape reconstruction for a soft continuum robot and pose estimation for a robot manipulator.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.