 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Rendering-based Pose Estimation for Surgical Robotic Instruments
Mar 07, 2025



Robot pose estimation is a challenging and crucial task for vision-based surgical robotic automation. Typical robotic calibration approaches, however, are not applicable to surgical robots, such as the da Vinci Research Kit (dVRK), due to joint angle measurement errors from cable-drives and the partially visible kinematic chain. Hence, previous works in surgical robotic automation used tracking algorithms to estimate the pose of the surgical tool in real-time and compensate for the joint angle errors. However, a big limitation of these previous tracking works is the initialization step which relied on only keypoints and SolvePnP. In this work, we fully explore the potential of geometric primitives beyond just keypoints with differentiable rendering, cylinders, and construct a versatile pose matching pipeline in a novel pose hypothesis space. We demonstrate the state-of-the-art performance of our single-shot calibration method with both calibration consistency and real surgical tasks. As a result, this marker-less calibration approach proves to be a robust and generalizable initialization step for surgical tool tracking.
CtRNet-X: Camera-to-Robot Pose Estimation in Real-world Conditions Using a Single Camera
Sep 16, 2024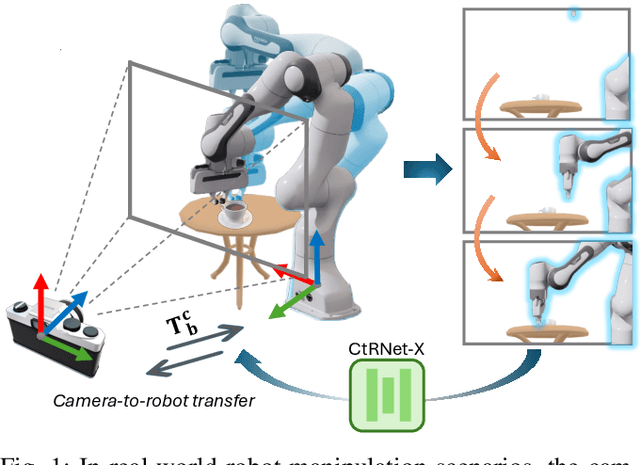

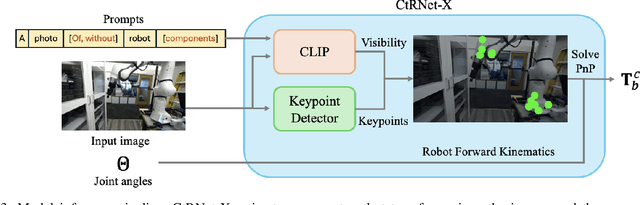
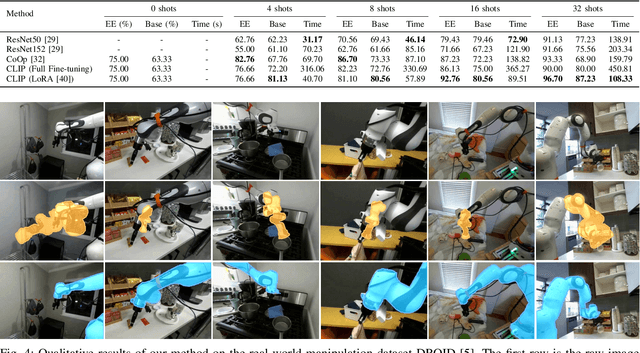
Camera-to-robot calibration is crucial for vision-based robot control and requires effort to make it accurate. Recent advancements in markerless pose estimation methods have eliminated the need for time-consuming physical setups for camera-to-robot calibration. While the existing markerless pose estimation methods have demonstrated impressive accuracy without the need for cumbersome setups, they rely on the assumption that all the robot joints are visible within the camera's field of view. However, in practice, robots usually move in and out of view, and some portion of the robot may stay out-of-frame during the whole manipulation task due to real-world constraints, leading to a lack of sufficient visual features and subsequent failure of these approaches. To address this challenge and enhance the applicability to vision-based robot control, we propose a novel framework capable of estimating the robot pose with partially visible robot manipulators. Our approach leverages the Vision-Language Models for fine-grained robot components detection, and integrates it into a keypoint-based pose estimation network, which enables more robust performance in varied operational conditions. The framework is evaluated on both public robot datasets and self-collected partial-view datasets to demonstrate our robustness and generalizability. As a result, this method is effective for robot pose estimation in a wider range of real-world manipulation scenarios.