 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepurposing Geometric Foundation Models for Multi-view Diffusion
Mar 23, 2026While recent advances in generative latent spaces have driven substantial progress in single-image generation, the optimal latent space for novel view synthesis (NVS) remains largely unexplored. In particular, NVS requires geometrically consistent generation across viewpoints, but existing approaches typically operate in a view-independent VAE latent space. In this paper, we propose Geometric Latent Diffusion (GLD), a framework that repurposes the geometrically consistent feature space of geometric foundation models as the latent space for multi-view diffusion. We show that these features not only support high-fidelity RGB reconstruction but also encode strong cross-view geometric correspondences, providing a well-suited latent space for NVS. Our experiments demonstrate that GLD outperforms both VAE and RAE on 2D image quality and 3D consistency metrics, while accelerating training by more than 4.4x compared to the VAE latent space. Notably, GLD remains competitive with state-of-the-art methods that leverage large-scale text-to-image pretraining, despite training its diffusion model from scratch without such generative pretraining.
Search2Motion: Training-Free Object-Level Motion Control via Attention-Consensus Search
Mar 17, 2026We present Search2Motion, a training-free framework for object-level motion editing in image-to-video generation. Unlike prior methods requiring trajectories, bounding boxes, masks, or motion fields, Search2Motion adopts target-frame-based control, leveraging first-last-frame motion priors to realize object relocation while preserving scene stability without fine-tuning. Reliable target-frame construction is achieved through semantic-guided object insertion and robust background inpainting. We further show that early-step self-attention maps predict object and camera dynamics, offering interpretable user feedback and motivating ACE-Seed (Attention Consensus for Early-step Seed selection), a lightweight search strategy that improves motion fidelity without look-ahead sampling or external evaluators. Noting that existing benchmarks conflate object and camera motion, we introduce S2M-DAVIS and S2M-OMB for stable-camera, object-only evaluation, alongside FLF2V-obj metrics that isolate object artifacts without requiring ground-truth trajectories. Search2Motion consistently outperforms baselines on FLF2V-obj and VBench.
PISA Experiments: Exploring Physics Post-Training for Video Diffusion Models by Watching Stuff Drop
Mar 12, 2025
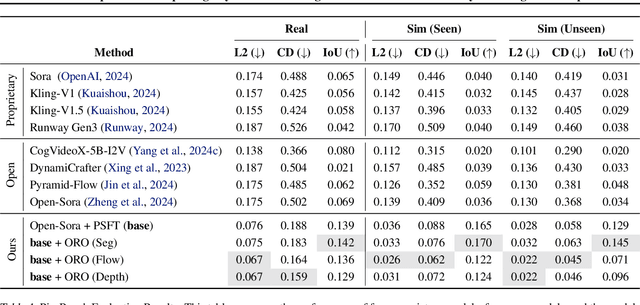
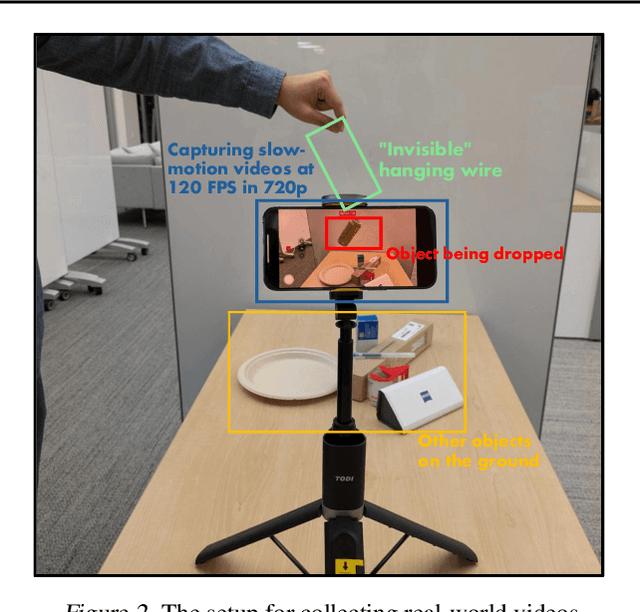

Large-scale pre-trained video generation models excel in content creation but are not reliable as physically accurate world simulators out of the box. This work studies the process of post-training these models for accurate world modeling through the lens of the simple, yet fundamental, physics task of modeling object freefall. We show state-of-the-art video generation models struggle with this basic task, despite their visually impressive outputs. To remedy this problem, we find that fine-tuning on a relatively small amount of simulated videos is effective in inducing the dropping behavior in the model, and we can further improve results through a novel reward modeling procedure we introduce. Our study also reveals key limitations of post-training in generalization and distribution modeling. Additionally, we release a benchmark for this task that may serve as a useful diagnostic tool for tracking physical accuracy in large-scale video generative model development.
CtRNet-X: Camera-to-Robot Pose Estimation in Real-world Conditions Using a Single Camera
Sep 16, 2024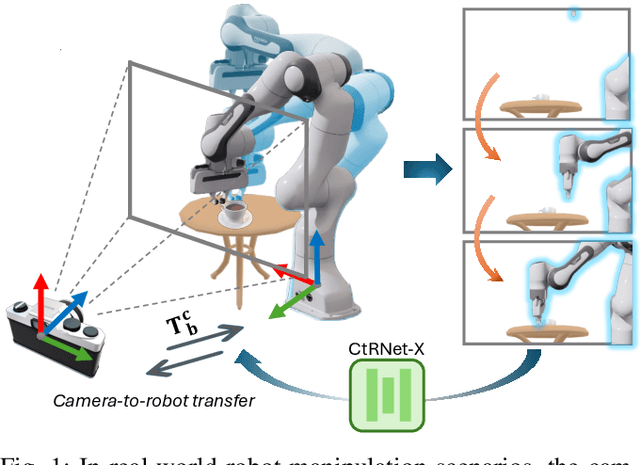

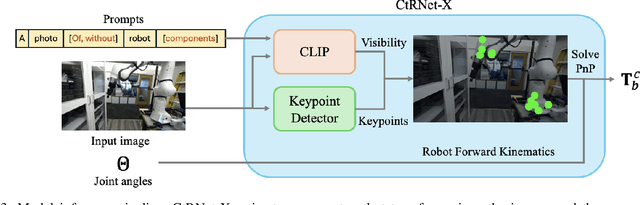
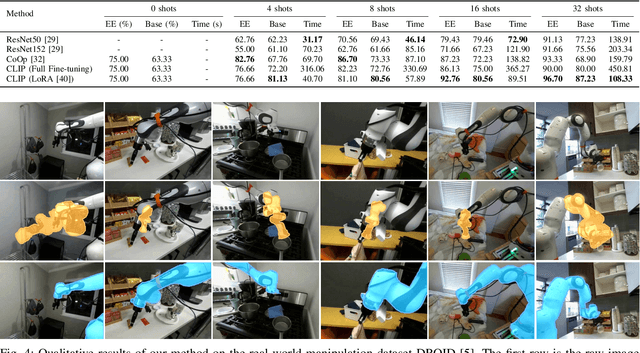
Camera-to-robot calibration is crucial for vision-based robot control and requires effort to make it accurate. Recent advancements in markerless pose estimation methods have eliminated the need for time-consuming physical setups for camera-to-robot calibration. While the existing markerless pose estimation methods have demonstrated impressive accuracy without the need for cumbersome setups, they rely on the assumption that all the robot joints are visible within the camera's field of view. However, in practice, robots usually move in and out of view, and some portion of the robot may stay out-of-frame during the whole manipulation task due to real-world constraints, leading to a lack of sufficient visual features and subsequent failure of these approaches. To address this challenge and enhance the applicability to vision-based robot control, we propose a novel framework capable of estimating the robot pose with partially visible robot manipulators. Our approach leverages the Vision-Language Models for fine-grained robot components detection, and integrates it into a keypoint-based pose estimation network, which enables more robust performance in varied operational conditions. The framework is evaluated on both public robot datasets and self-collected partial-view datasets to demonstrate our robustness and generalizability. As a result, this method is effective for robot pose estimation in a wider range of real-world manipulation scenarios.
Image Sculpting: Precise Object Editing with 3D Geometry Control
Jan 02, 2024We present Image Sculpting, a new framework for editing 2D images by incorporating tools from 3D geometry and graphics. This approach differs markedly from existing methods, which are confined to 2D spaces and typically rely on textual instructions, leading to ambiguity and limited control. Image Sculpting converts 2D objects into 3D, enabling direct interaction with their 3D geometry. Post-editing, these objects are re-rendered into 2D, merging into the original image to produce high-fidelity results through a coarse-to-fine enhancement process. The framework supports precise, quantifiable, and physically-plausible editing options such as pose editing, rotation, translation, 3D composition, carving, and serial addition. It marks an initial step towards combining the creative freedom of generative models with the precision of graphics pipelines.
BASED: Bundle-Adjusting Surgical Endoscopic Dynamic Video Reconstruction using Neural Radiance Fields
Sep 27, 2023



Reconstruction of deformable scenes from endoscopic videos is important for many applications such as intraoperative navigation, surgical visual perception, and robotic surgery. It is a foundational requirement for realizing autonomous robotic interventions for minimally invasive surgery. However, previous approaches in this domain have been limited by their modular nature and are confined to specific camera and scene settings. Our work adopts the Neural Radiance Fields (NeRF) approach to learning 3D implicit representations of scenes that are both dynamic and deformable over time, and furthermore with unknown camera poses. We demonstrate this approach on endoscopic surgical scenes from robotic surgery. This work removes the constraints of known camera poses and overcomes the drawbacks of the state-of-the-art unstructured dynamic scene reconstruction technique, which relies on the static part of the scene for accurate reconstruction. Through several experimental datasets, we demonstrate the versatility of our proposed model to adapt to diverse camera and scene settings, and show its promise for both current and future robotic surgical systems.
BAA-NGP: Bundle-Adjusting Accelerated Neural Graphics Primitives
Jun 09, 2023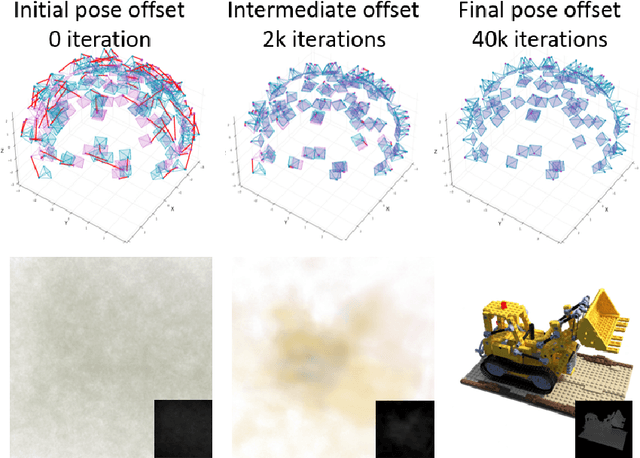
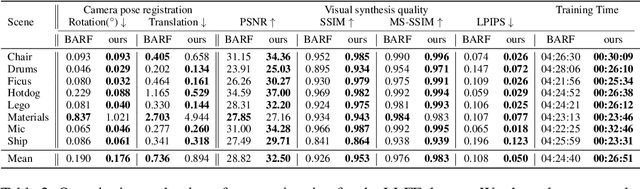
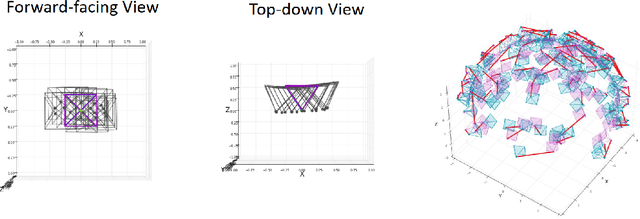
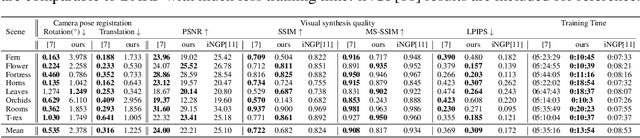
Implicit neural representation has emerged as a powerful method for reconstructing 3D scenes from 2D images. Given a set of camera poses and associated images, the models can be trained to synthesize novel, unseen views. In order to expand the use cases for implicit neural representations, we need to incorporate camera pose estimation capabilities as part of the representation learning, as this is necessary for reconstructing scenes from real-world video sequences where cameras are generally not being tracked. Existing approaches like COLMAP and, most recently, bundle-adjusting neural radiance field methods often suffer from lengthy processing times. These delays ranging from hours to days, arise from laborious feature matching, hardware limitations, dense point sampling, and long training times required by a multi-layer perceptron structure with a large number of parameters. To address these challenges, we propose a framework called bundle-adjusting accelerated neural graphics primitives (BAA-NGP). Our approach leverages accelerated sampling and hash encoding to expedite both pose refinement/estimation and 3D scene reconstruction. Experimental results demonstrate that our method achieves a more than 10 to 20 $\times$ speed improvement in novel view synthesis compared to other bundle-adjusting neural radiance field methods without sacrificing the quality of pose estimation.
Towards Panoptic 3D Parsing for Single Image in the Wild
Nov 29, 2021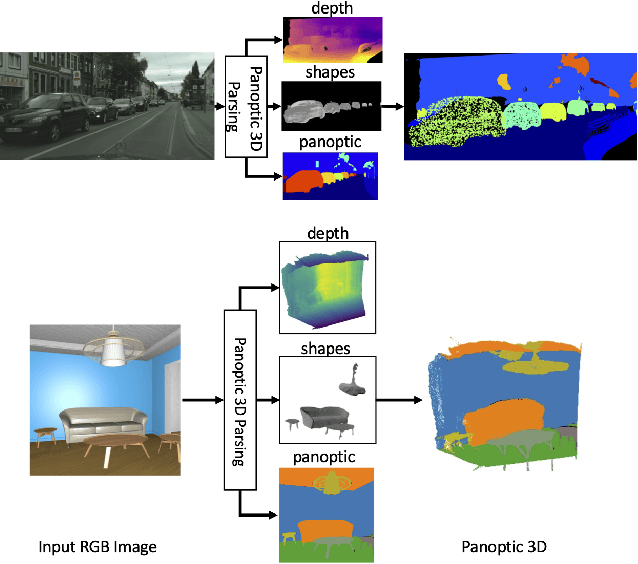
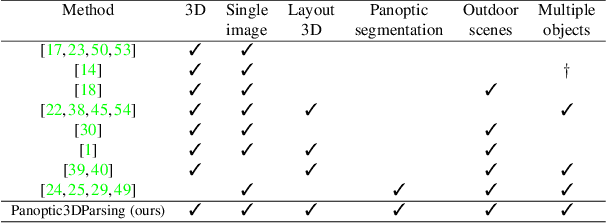
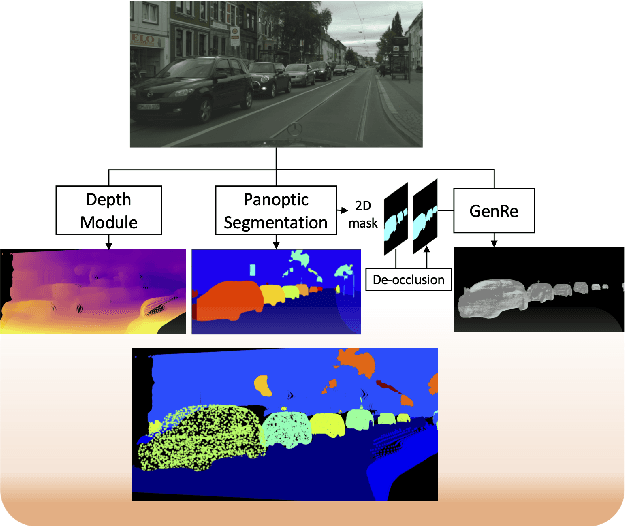

Performing single image holistic understanding and 3D reconstruction is a central task in computer vision. This paper presents an integrated system that performs dense scene labeling, object detection, instance segmentation, depth estimation, 3D shape reconstruction, and 3D layout estimation for indoor and outdoor scenes from a single RGB image. We name our system panoptic 3D parsing (Panoptic3D) in which panoptic segmentation ("stuff" segmentation and "things" detection/segmentation) with 3D reconstruction is performed. We design a stage-wise system, Panoptic3D (stage-wise), where a complete set of annotations is absent. Additionally, we present an end-to-end pipeline, Panoptic3D (end-to-end), trained on a synthetic dataset with a full set of annotations. We show results on both indoor (3D-FRONT) and outdoor (COCO and Cityscapes) scenes. Our proposed panoptic 3D parsing framework points to a promising direction in computer vision. Panoptic3D can be applied to a variety of applications, including autonomous driving, mapping, robotics, design, computer graphics, robotics, human-computer interaction, and augmented reality.