 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAA-NGP: Bundle-Adjusting Accelerated Neural Graphics Primitives
Jun 09, 2023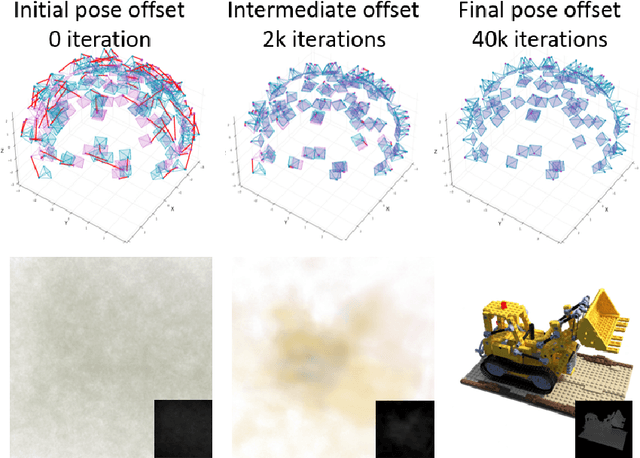
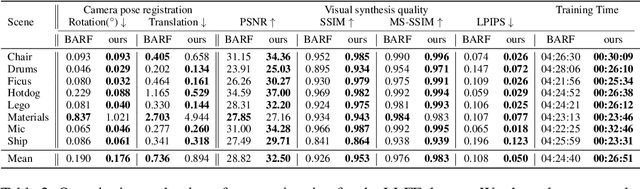
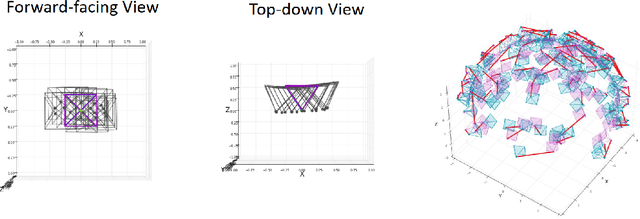
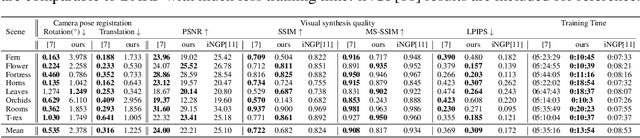
Implicit neural representation has emerged as a powerful method for reconstructing 3D scenes from 2D images. Given a set of camera poses and associated images, the models can be trained to synthesize novel, unseen views. In order to expand the use cases for implicit neural representations, we need to incorporate camera pose estimation capabilities as part of the representation learning, as this is necessary for reconstructing scenes from real-world video sequences where cameras are generally not being tracked. Existing approaches like COLMAP and, most recently, bundle-adjusting neural radiance field methods often suffer from lengthy processing times. These delays ranging from hours to days, arise from laborious feature matching, hardware limitations, dense point sampling, and long training times required by a multi-layer perceptron structure with a large number of parameters. To address these challenges, we propose a framework called bundle-adjusting accelerated neural graphics primitives (BAA-NGP). Our approach leverages accelerated sampling and hash encoding to expedite both pose refinement/estimation and 3D scene reconstruction. Experimental results demonstrate that our method achieves a more than 10 to 20 $\times$ speed improvement in novel view synthesis compared to other bundle-adjusting neural radiance field methods without sacrificing the quality of pose estimation.
INV: Towards Streaming Incremental Neural Videos
Feb 03, 2023Recent works in spatiotemporal radiance fields can produce photorealistic free-viewpoint videos. However, they are inherently unsuitable for interactive streaming scenarios (e.g. video conferencing, telepresence) because have an inevitable lag even if the training is instantaneous. This is because these approaches consume videos and thus have to buffer chunks of frames (often seconds) before processing. In this work, we take a step towards interactive streaming via a frame-by-frame approach naturally free of lag. Conventional wisdom believes that per-frame NeRFs are impractical due to prohibitive training costs and storage. We break this belief by introducing Incremental Neural Videos (INV), a per-frame NeRF that is efficiently trained and streamable. We designed INV based on two insights: (1) Our main finding is that MLPs naturally partition themselves into Structure and Color Layers, which store structural and color/texture information respectively. (2) We leverage this property to retain and improve upon knowledge from previous frames, thus amortizing training across frames and reducing redundant learning. As a result, with negligible changes to NeRF, INV can achieve good qualities (>28.6db) in 8min/frame. It can also outperform prior SOTA in 19% less training time. Additionally, our Temporal Weight Compression reduces the per-frame size to 0.3MB/frame (6.6% of NeRF). More importantly, INV is free from buffer lag and is naturally fit for streaming. While this work does not achieve real-time training, it shows that incremental approaches like INV present new possibilities in interactive 3D streaming. Moreover, our discovery of natural information partition leads to a better understanding and manipulation of MLPs. Code and dataset will be released soon.