 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-efficient Continual Learning with Neural Collapse Contrastive
Dec 05, 2024



Contrastive learning has significantly improved representation quality, enhancing knowledge transfer across tasks in continual learning (CL). However, catastrophic forgetting remains a key challenge, as contrastive based methods primarily focus on "soft relationships" or "softness" between samples, which shift with changing data distributions and lead to representation overlap across tasks. Recently, the newly identified Neural Collapse phenomenon has shown promise in CL by focusing on "hard relationships" or "hardness" between samples and fixed prototypes. However, this approach overlooks "softness", crucial for capturing intra-class variability, and this rigid focus can also pull old class representations toward current ones, increasing forgetting. Building on these insights, we propose Focal Neural Collapse Contrastive (FNC2), a novel representation learning loss that effectively balances both soft and hard relationships. Additionally, we introduce the Hardness-Softness Distillation (HSD) loss to progressively preserve the knowledge gained from these relationships across tasks. Our method outperforms state-of-the-art approaches, particularly in minimizing memory reliance. Remarkably, even without the use of memory, our approach rivals rehearsal-based methods, offering a compelling solution for data privacy concerns.
Towards Panoptic 3D Parsing for Single Image in the Wild
Nov 29, 2021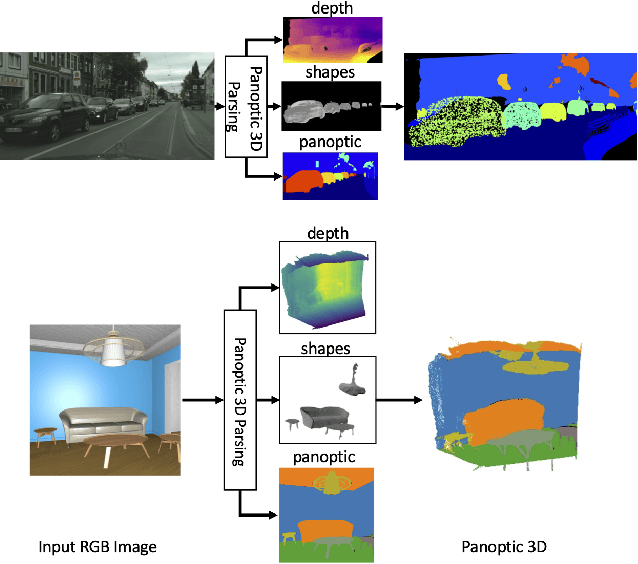
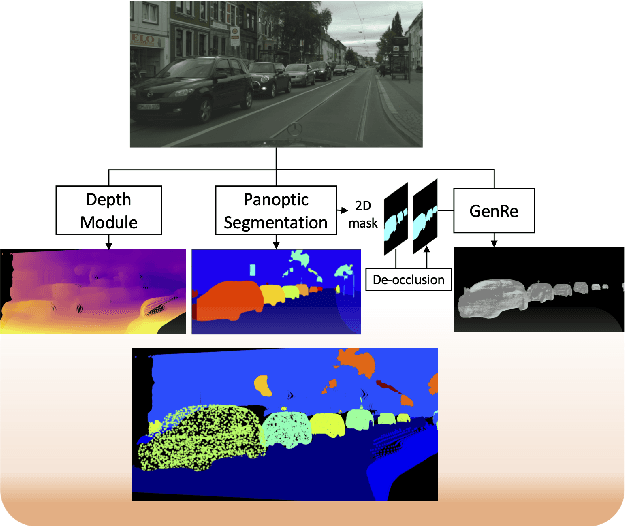

Performing single image holistic understanding and 3D reconstruction is a central task in computer vision. This paper presents an integrated system that performs dense scene labeling, object detection, instance segmentation, depth estimation, 3D shape reconstruction, and 3D layout estimation for indoor and outdoor scenes from a single RGB image. We name our system panoptic 3D parsing (Panoptic3D) in which panoptic segmentation ("stuff" segmentation and "things" detection/segmentation) with 3D reconstruction is performed. We design a stage-wise system, Panoptic3D (stage-wise), where a complete set of annotations is absent. Additionally, we present an end-to-end pipeline, Panoptic3D (end-to-end), trained on a synthetic dataset with a full set of annotations. We show results on both indoor (3D-FRONT) and outdoor (COCO and Cityscapes) scenes. Our proposed panoptic 3D parsing framework points to a promising direction in computer vision. Panoptic3D can be applied to a variety of applications, including autonomous driving, mapping, robotics, design, computer graphics, robotics, human-computer interaction, and augmented reality.
Query-Focused Extractive Summarisation for Finding Ideal Answers to Biomedical and COVID-19 Questions
Aug 31, 2021
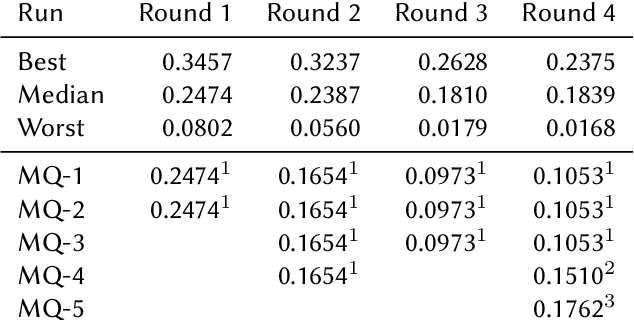
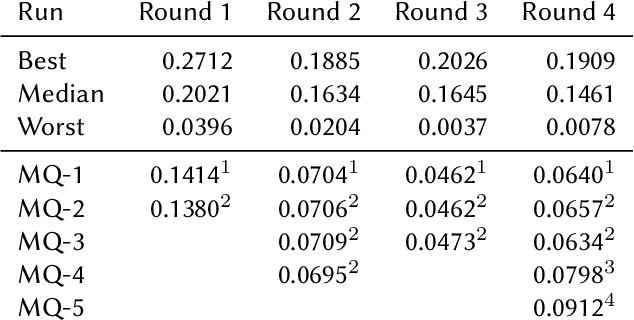
This paper presents Macquarie University's participation to the BioASQ Synergy Task, and BioASQ9b Phase B. In each of these tasks, our participation focused on the use of query-focused extractive summarisation to obtain the ideal answers to medical questions. The Synergy Task is an end-to-end question answering task on COVID-19 where systems are required to return relevant documents, snippets, and answers to a given question. Given the absence of training data, we used a query-focused summarisation system that was trained with the BioASQ8b training data set and we experimented with methods to retrieve the documents and snippets. Considering the poor quality of the documents and snippets retrieved by our system, we observed reasonably good quality in the answers returned. For phase B of the BioASQ9b task, the relevant documents and snippets were already included in the test data. Our system split the snippets into candidate sentences and used BERT variants under a sentence classification setup. The system used the question and candidate sentence as input and was trained to predict the likelihood of the candidate sentence being part of the ideal answer. The runs obtained either the best or second best ROUGE-F1 results of all participants to all batches of BioASQ9b. This shows that using BERT in a classification setup is a very strong baseline for the identification of ideal answers.
ICDAR 2021 Competition on Historical Map Segmentation
May 27, 2021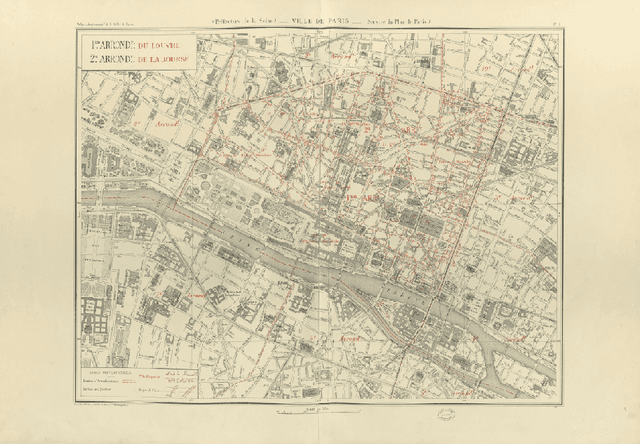
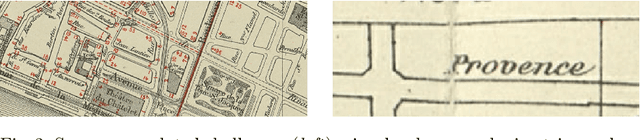
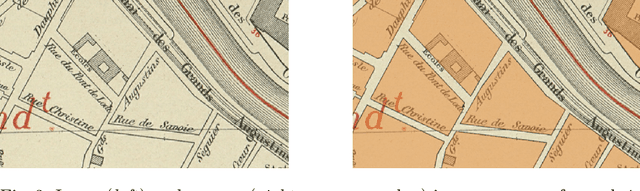
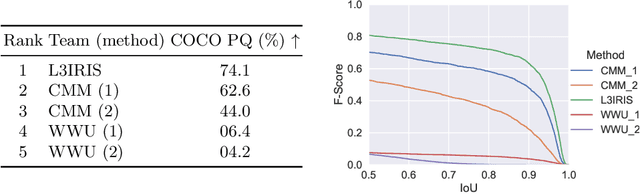
This paper presents the final results of the ICDAR 2021 Competition on Historical Map Segmentation (MapSeg), encouraging research on a series of historical atlases of Paris, France, drawn at 1/5000 scale between 1894 and 1937. The competition featured three tasks, awarded separately. Task~1 consists in detecting building blocks and was won by the L3IRIS team using a DenseNet-121 network trained in a weakly supervised fashion. This task is evaluated on 3 large images containing hundreds of shapes to detect. Task~2 consists in segmenting map content from the larger map sheet, and was won by the UWB team using a U-Net-like FCN combined with a binarization method to increase detection edge accuracy. Task~3 consists in locating intersection points of geo-referencing lines, and was also won by the UWB team who used a dedicated pipeline combining binarization, line detection with Hough transform, candidate filtering, and template matching for intersection refinement. Tasks~2 and~3 are evaluated on 95 map sheets with complex content. Dataset, evaluation tools and results are available under permissive licensing at \url{https://icdar21-mapseg.github.io/}.
The Ubiqus English-Inuktitut System for WMT20
Nov 18, 2020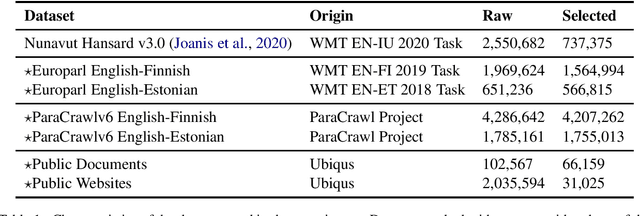

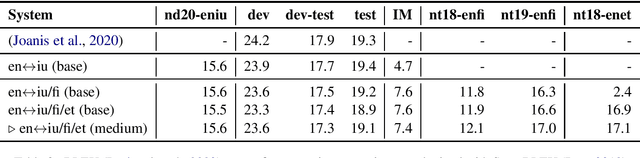
This paper describes Ubiqus' submission to the WMT20 English-Inuktitut shared news translation task. Our main system, and only submission, is based on a multilingual approach, jointly training a Transformer model on several agglutinative languages. The English-Inuktitut translation task is challenging at every step, from data selection, preparation and tokenization to quality evaluation down the line. Difficulties emerge both because of the peculiarities of the Inuktitut language as well as the low-resource context.
Query Focused Multi-document Summarisation of Biomedical Texts
Aug 27, 2020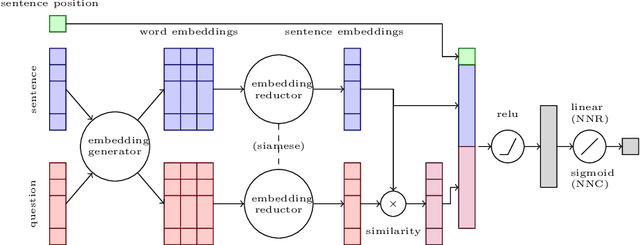
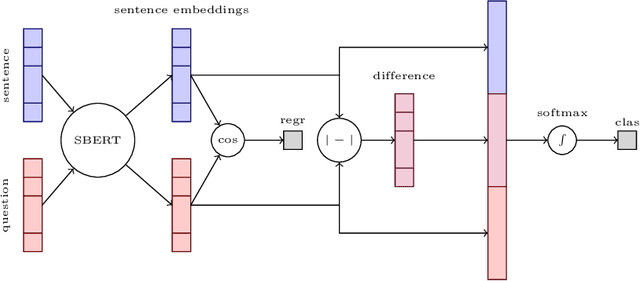
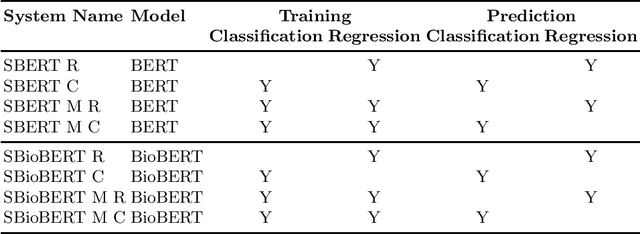
This paper presents the participation of Macquarie University and the Australian National University for Task B Phase B of the 2020 BioASQ Challenge (BioASQ8b). Our overall framework implements Query focused multi-document extractive summarisation by applying either a classification or a regression layer to the candidate sentence embeddings and to the comparison between the question and sentence embeddings. We experiment with variants using BERT and BioBERT, Siamese architectures, and reinforcement learning. We observe the best results when BERT is used to obtain the word embeddings, followed by an LSTM layer to obtain sentence embeddings. Variants using Siamese architectures or BioBERT did not improve the results.
Leverage Unlabeled Data for Abstractive Speech Summarization with Self-Supervised Learning and Back-Summarization
Jul 30, 2020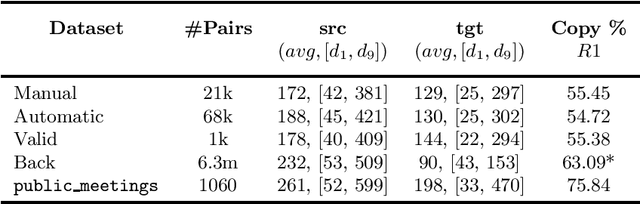
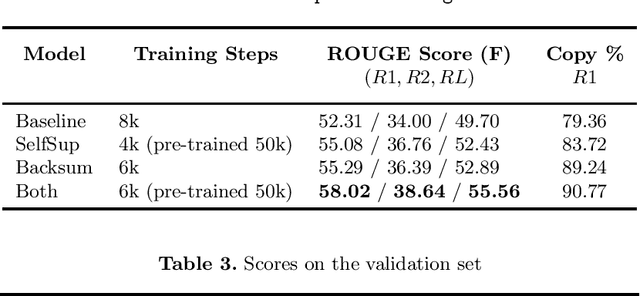
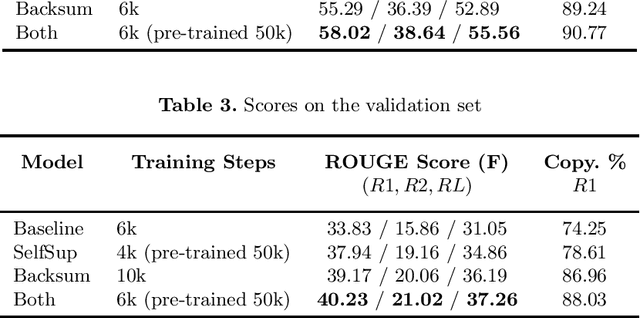
Supervised approaches for Neural Abstractive Summarization require large annotated corpora that are costly to build. We present a French meeting summarization task where reports are predicted based on the automatic transcription of the meeting audio recordings. In order to build a corpus for this task, it is necessary to obtain the (automatic or manual) transcription of each meeting, and then to segment and align it with the corresponding manual report to produce training examples suitable for training. On the other hand, we have access to a very large amount of unaligned data, in particular reports without corresponding transcription. Reports are professionally written and well formatted making pre-processing straightforward. In this context, we study how to take advantage of this massive amount of unaligned data using two approaches (i) self-supervised pre-training using a target-side denoising encoder-decoder model; (ii) back-summarization i.e. reversing the summarization process by learning to predict the transcription given the report, in order to align single reports with generated transcription, and use this synthetic dataset for further training. We report large improvements compared to the previous baseline (trained on aligned data only) for both approaches on two evaluation sets. Moreover, combining the two gives even better results, outperforming the baseline by a large margin of +6 ROUGE-1 and ROUGE-L and +5 ROUGE-2 on two evaluation sets
Align then Summarize: Automatic Alignment Methods for Summarization Corpus Creation
Jul 15, 2020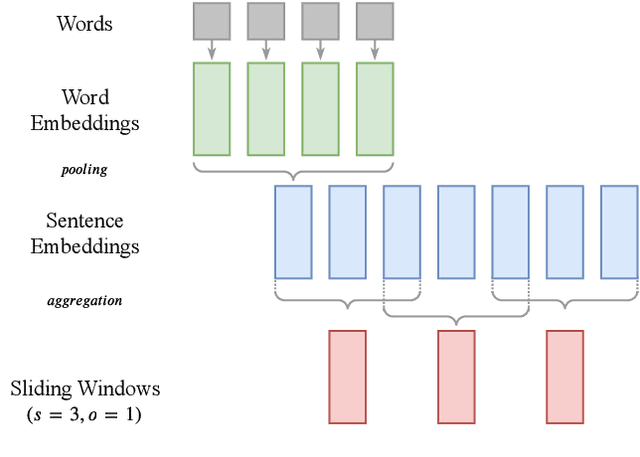
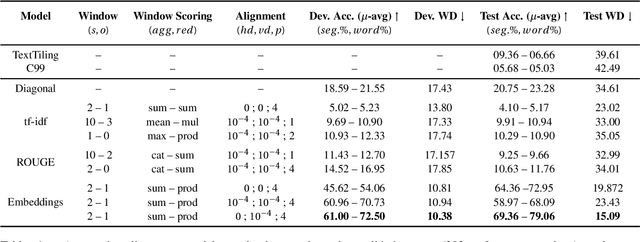
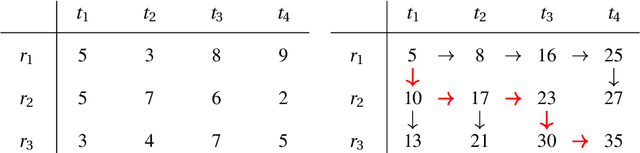
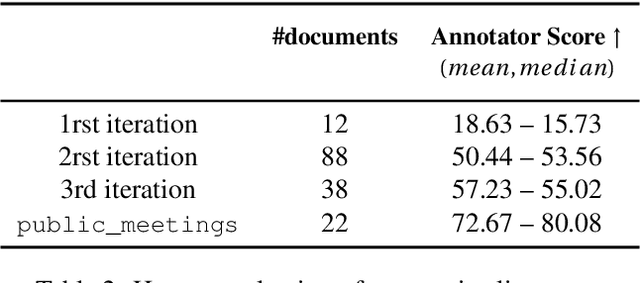
Summarizing texts is not a straightforward task. Before even considering text summarization, one should determine what kind of summary is expected. How much should the information be compressed? Is it relevant to reformulate or should the summary stick to the original phrasing? State-of-the-art on automatic text summarization mostly revolves around news articles. We suggest that considering a wider variety of tasks would lead to an improvement in the field, in terms of generalization and robustness. We explore meeting summarization: generating reports from automatic transcriptions. Our work consists in segmenting and aligning transcriptions with respect to reports, to get a suitable dataset for neural summarization. Using a bootstrapping approach, we provide pre-alignments that are corrected by human annotators, making a validation set against which we evaluate automatic models. This consistently reduces annotators' efforts by providing iteratively better pre-alignment and maximizes the corpus size by using annotations from our automatic alignment models. Evaluation is conducted on \publicmeetings, a novel corpus of aligned public meetings. We report automatic alignment and summarization performances on this corpus and show that automatic alignment is relevant for data annotation since it leads to large improvement of almost +4 on all ROUGE scores on the summarization task.
Searching Scientific Literature for Answers on COVID-19 Questions
Jul 06, 2020
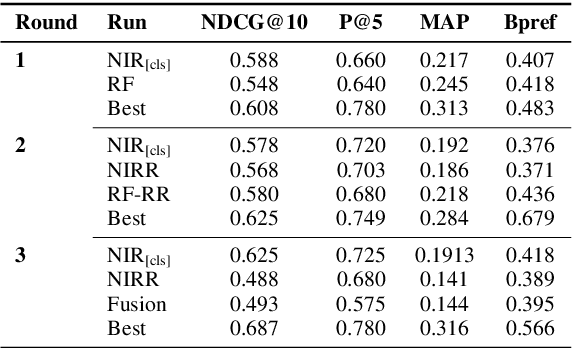
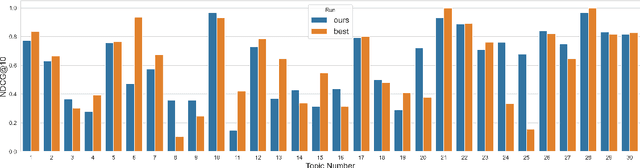
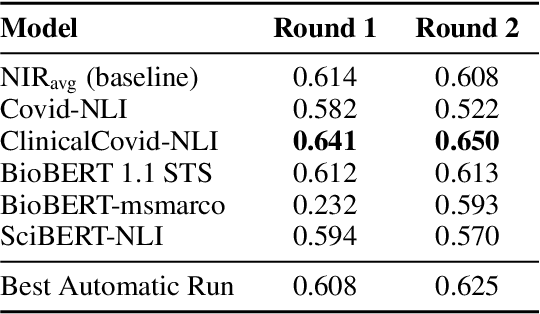
Finding answers related to a pandemic of a novel disease raises new challenges for information seeking and retrieval, as the new information becomes available gradually. TREC COVID search track aims to assist in creating search tools to aid scientists, clinicians, policy makers and others with similar information needs in finding reliable answers from the scientific literature. We experiment with different ranking algorithms as part of our participation in this challenge. We propose a novel method for neural retrieval, and demonstrate its effectiveness on the TREC COVID search.
TED-LIUM 3: twice as much data and corpus repartition for experiments on speaker adaptation
Jul 03, 2018
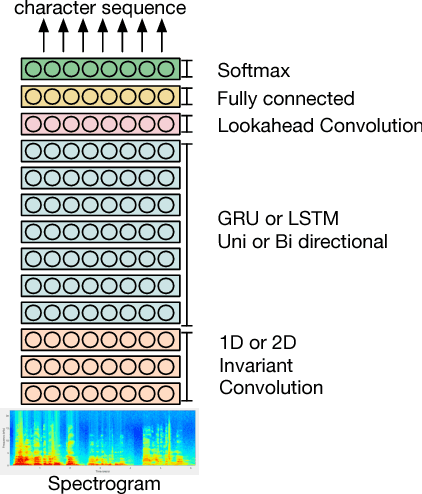
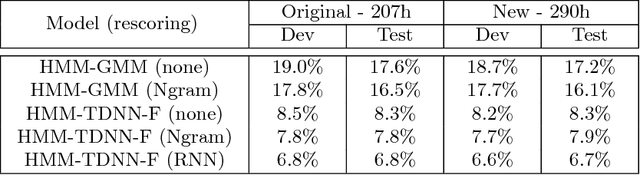
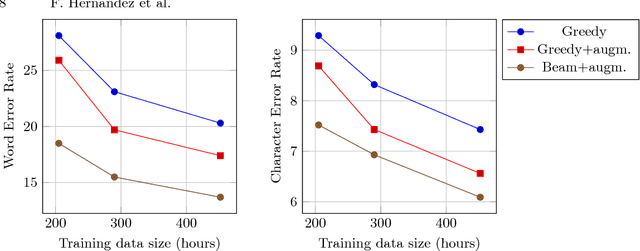
In this paper, we present TED-LIUM release 3 corpus dedicated to speech recognition in English, that multiplies by more than two the available data to train acoustic models in comparison with TED-LIUM 2. We present the recent development on Automatic Speech Recognition (ASR) systems in comparison with the two previous releases of the TED-LIUM Corpus from 2012 and 2014. We demonstrate that, passing from 207 to 452 hours of transcribed speech training data is really more useful for end-to-end ASR systems than for HMM-based state-of-the-art ones, even if the HMM-based ASR system still outperforms end-to-end ASR system when the size of audio training data is 452 hours, with respectively a Word Error Rate (WER) of 6.6% and 13.7%. Last, we propose two repartitions of the TED-LIUM release 3 corpus: the legacy one that is the same as the one existing in release 2, and a new one, calibrated and designed to make experiments on speaker adaptation. Like the two first releases, TED-LIUM 3 corpus will be freely available for the research community.