 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ubiqus English-Inuktitut System for WMT20
Nov 18, 2020

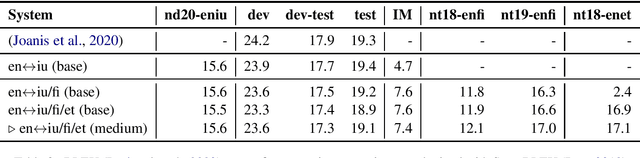
This paper describes Ubiqus' submission to the WMT20 English-Inuktitut shared news translation task. Our main system, and only submission, is based on a multilingual approach, jointly training a Transformer model on several agglutinative languages. The English-Inuktitut translation task is challenging at every step, from data selection, preparation and tokenization to quality evaluation down the line. Difficulties emerge both because of the peculiarities of the Inuktitut language as well as the low-resource context.
Leverage Unlabeled Data for Abstractive Speech Summarization with Self-Supervised Learning and Back-Summarization
Jul 30, 2020
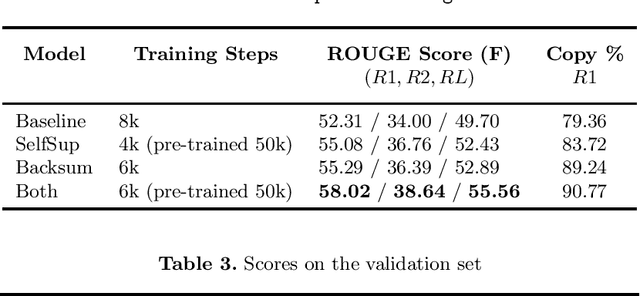
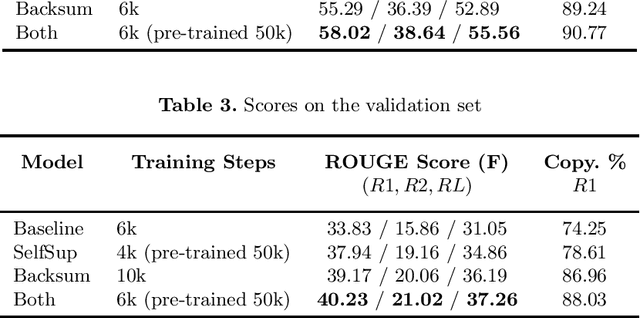
Supervised approaches for Neural Abstractive Summarization require large annotated corpora that are costly to build. We present a French meeting summarization task where reports are predicted based on the automatic transcription of the meeting audio recordings. In order to build a corpus for this task, it is necessary to obtain the (automatic or manual) transcription of each meeting, and then to segment and align it with the corresponding manual report to produce training examples suitable for training. On the other hand, we have access to a very large amount of unaligned data, in particular reports without corresponding transcription. Reports are professionally written and well formatted making pre-processing straightforward. In this context, we study how to take advantage of this massive amount of unaligned data using two approaches (i) self-supervised pre-training using a target-side denoising encoder-decoder model; (ii) back-summarization i.e. reversing the summarization process by learning to predict the transcription given the report, in order to align single reports with generated transcription, and use this synthetic dataset for further training. We report large improvements compared to the previous baseline (trained on aligned data only) for both approaches on two evaluation sets. Moreover, combining the two gives even better results, outperforming the baseline by a large margin of +6 ROUGE-1 and ROUGE-L and +5 ROUGE-2 on two evaluation sets
TED-LIUM 3: twice as much data and corpus repartition for experiments on speaker adaptation
Jul 03, 2018
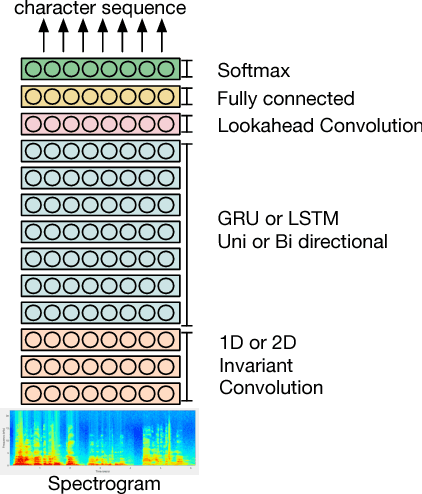
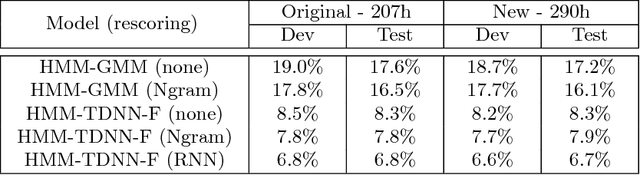
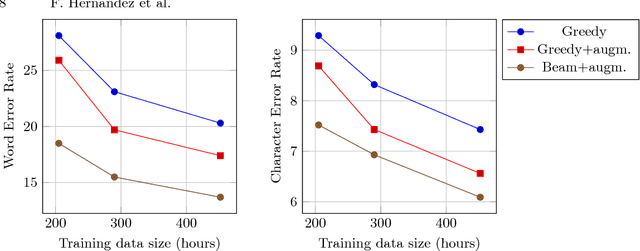
In this paper, we present TED-LIUM release 3 corpus dedicated to speech recognition in English, that multiplies by more than two the available data to train acoustic models in comparison with TED-LIUM 2. We present the recent development on Automatic Speech Recognition (ASR) systems in comparison with the two previous releases of the TED-LIUM Corpus from 2012 and 2014. We demonstrate that, passing from 207 to 452 hours of transcribed speech training data is really more useful for end-to-end ASR systems than for HMM-based state-of-the-art ones, even if the HMM-based ASR system still outperforms end-to-end ASR system when the size of audio training data is 452 hours, with respectively a Word Error Rate (WER) of 6.6% and 13.7%. Last, we propose two repartitions of the TED-LIUM release 3 corpus: the legacy one that is the same as the one existing in release 2, and a new one, calibrated and designed to make experiments on speaker adaptation. Like the two first releases, TED-LIUM 3 corpus will be freely available for the research community.