 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLC-Score: Reference-less estimation of Text Comprehension Difficulty
Oct 05, 2023Being able to read and understand written text is critical in a digital era. However, studies shows that a large fraction of the population experiences comprehension issues. In this context, further initiatives in accessibility are required to improve the audience text comprehension. However, writers are hardly assisted nor encouraged to produce easy-to-understand content. Moreover, Automatic Text Simplification (ATS) model development suffers from the lack of metric to accurately estimate comprehension difficulty We present \textsc{LC-Score}, a simple approach for training text comprehension metric for any French text without reference \ie predicting how easy to understand a given text is on a $[0, 100]$ scale. Our objective with this scale is to quantitatively capture the extend to which a text suits to the \textit{Langage Clair} (LC, \textit{Clear Language}) guidelines, a French initiative closely related to English Plain Language. We explore two approaches: (i) using linguistically motivated indicators used to train statistical models, and (ii) neural learning directly from text leveraging pre-trained language models. We introduce a simple proxy task for comprehension difficulty training as a classification task. To evaluate our models, we run two distinct human annotation experiments, and find that both approaches (indicator based and neural) outperforms commonly used readability and comprehension metrics such as FKGL.
Leverage Unlabeled Data for Abstractive Speech Summarization with Self-Supervised Learning and Back-Summarization
Jul 30, 2020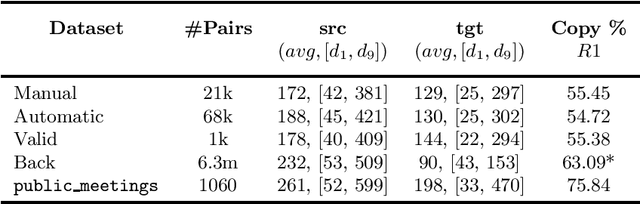
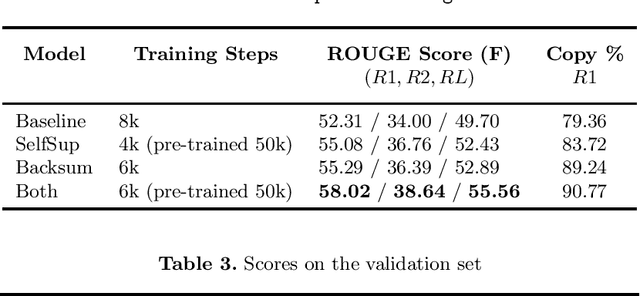
Supervised approaches for Neural Abstractive Summarization require large annotated corpora that are costly to build. We present a French meeting summarization task where reports are predicted based on the automatic transcription of the meeting audio recordings. In order to build a corpus for this task, it is necessary to obtain the (automatic or manual) transcription of each meeting, and then to segment and align it with the corresponding manual report to produce training examples suitable for training. On the other hand, we have access to a very large amount of unaligned data, in particular reports without corresponding transcription. Reports are professionally written and well formatted making pre-processing straightforward. In this context, we study how to take advantage of this massive amount of unaligned data using two approaches (i) self-supervised pre-training using a target-side denoising encoder-decoder model; (ii) back-summarization i.e. reversing the summarization process by learning to predict the transcription given the report, in order to align single reports with generated transcription, and use this synthetic dataset for further training. We report large improvements compared to the previous baseline (trained on aligned data only) for both approaches on two evaluation sets. Moreover, combining the two gives even better results, outperforming the baseline by a large margin of +6 ROUGE-1 and ROUGE-L and +5 ROUGE-2 on two evaluation sets
Align then Summarize: Automatic Alignment Methods for Summarization Corpus Creation
Jul 15, 2020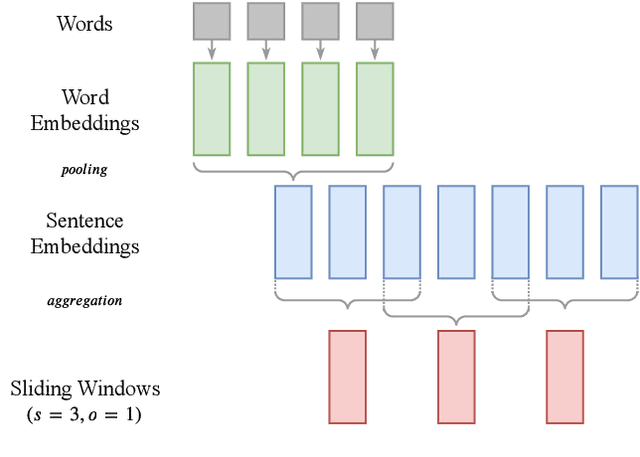
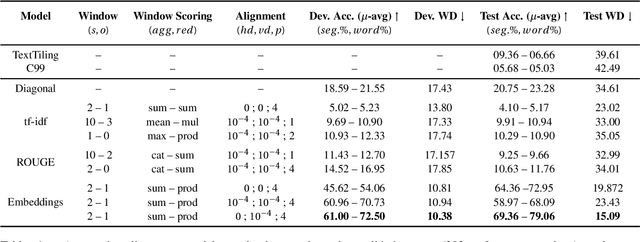
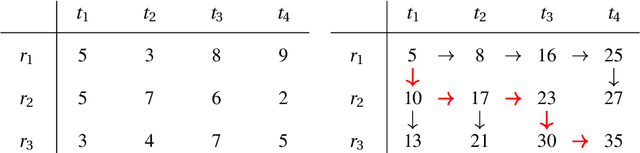
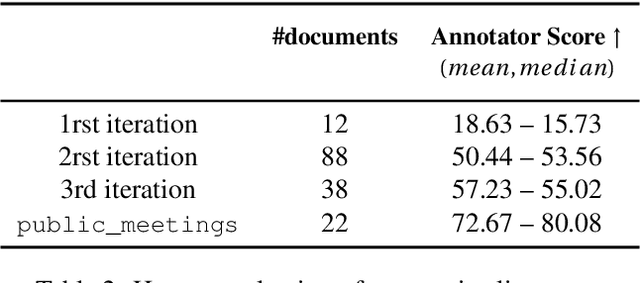
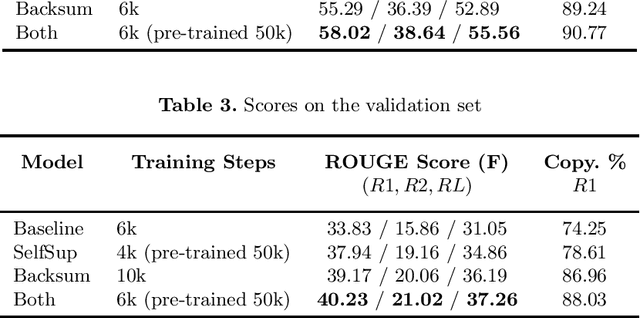
Summarizing texts is not a straightforward task. Before even considering text summarization, one should determine what kind of summary is expected. How much should the information be compressed? Is it relevant to reformulate or should the summary stick to the original phrasing? State-of-the-art on automatic text summarization mostly revolves around news articles. We suggest that considering a wider variety of tasks would lead to an improvement in the field, in terms of generalization and robustness. We explore meeting summarization: generating reports from automatic transcriptions. Our work consists in segmenting and aligning transcriptions with respect to reports, to get a suitable dataset for neural summarization. Using a bootstrapping approach, we provide pre-alignments that are corrected by human annotators, making a validation set against which we evaluate automatic models. This consistently reduces annotators' efforts by providing iteratively better pre-alignment and maximizes the corpus size by using annotations from our automatic alignment models. Evaluation is conducted on \publicmeetings, a novel corpus of aligned public meetings. We report automatic alignment and summarization performances on this corpus and show that automatic alignment is relevant for data annotation since it leads to large improvement of almost +4 on all ROUGE scores on the summarization task.